Med3D: Transfer Learning for 3D Medical Image Analysis
1. Introduction
- 의료 영상 분석은 데이터 부족과 높은 annotation 비용 때문에 딥러닝 적용이 어려움.
- 일반 이미지 분야처럼 pre-training을 통한 transfer learning이 필요.
- Med3D는 다양한 의료 영상 dataset을 합쳐 3D 사전학습 네트워크를 만들고, 이를 segmentation·classification 등 여러 downstream task에 transfer
2. Related Work
- 2D 사전학습 모델(ImageNet 기반)은 풍부하지만, 3D 의료 영상에는 직접 적용이 어려움.
- 기존 3D 모델들은 dataset 규모가 작아 과적합에 취약.
- 따라서 대규모 3D 의료 영상 pre-training 모델의 필요성이 대두됨
3. Methodology
(1) Med3D Backbone
- 기본 구조는 ResNet 계열.
- FC layer 제거 → multi-branch decoder 추가 (8-branch, 1×1×1 conv + upsampling)

(2) Dataset: 3DSeg-8
- 8개의 공개 의료 영상 dataset(Brain, Hippo, Prostate, Liver, Heart, Pancreas, Vessel, Spleen).
- MRI/CT, organ/tissue/tumour segmentation task 포함.
- dataset 크기 불균형 해결: 가장 큰 dataset 크기를 기준으로 나머지 augmentation으로 balancing.
(3) Preprocessing
- Spacing normalization: voxel 크기 차이를 줄이기 위해 median spacing으로 resample.
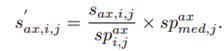
- Augmentation: translation, rotation, scaling 적용 → 모델의 강인성 향상.
4. Experiments
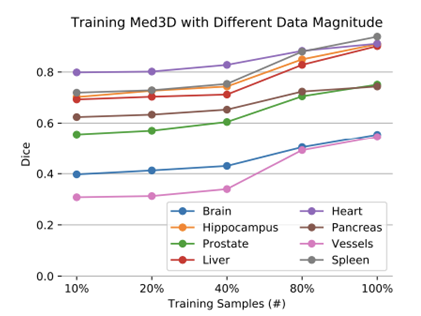
(1) Training Data Magnitude
- 데이터 크기가 많아질수록 Dice score 상승.
- 10~20% 데이터에서는 overfitting으로 성능 급락.
- 100% 사용 시 최고 성능 달성 → 데이터 크기의 중요성 입증.
(2) Training Set Variety
- 하나의 dataset만 학습한 경우보다, 여러 dataset을 함께 학습하면 성능 향상.
- 다양한 장기·조직 dataset이 서로 보완적 정보를 제공 → 일반화 성능 증가.
(3) Downstream Task: Lung Segmentation
- Med3D encoder를 feature extractor로 사용.
- Decoder: 3D transposed conv + conv layers → voxel 단위 segmentation.
- 결과: 사전학습 feature가 lung segmentation에 잘 transfer됨을 확인.
(4) Downstream Task: Pulmonary Nodule Classification
- Med3D encoder + GAP(Global Average Pooling) + 1×1×1 conv layer → classification head.
- Pulmonary nodule은 작은 구조지만 Med3D feature가 여전히 유효.
- Transfer learning으로 작은 데이터셋에도 좋은 성능 달성.
(5) Downstream Task: Liver Segmentation
- Stage 1: coarse segmentation으로 ROI 추출 (Med3D encoder + 1×1×1 conv).
- Stage 2: crop된 ROI를 fine segmentation (Med3D encoder + 3D DenseASPP decoder).
- 결과: 정밀한 간 segmentation 가능, multi-scale context 효과 확인

5. Results
- Med3D 사전학습 모델은 데이터 크기와 다양성이 성능 향상에 중요한 역할을 함을 실험으로 입증.
- 여러 downstream task(lung segmentation, nodule classification, liver segmentation)에서 효과적인 transfer learning 성능 확인.
- Dice score가 baseline 대비 전반적으로 상승, 특히 작은 dataset에서 효과 큼.
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
1. 배경
- 기존 객체 탐지 파이프라인은 Region Proposal + CNN 기반 분류/회귀의 조합.
- R-CNN / Fast R-CNN은 성능은 좋았으나, Region Proposal (예: Selective Search) 단계가 느려서 실시간 탐지 불가능.
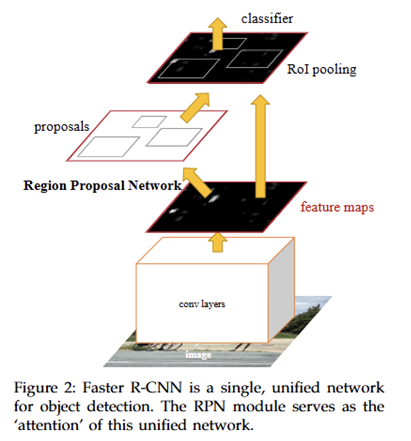
- Faster R-CNN은 Region Proposal Network (RPN)을 제안하여, proposal까지 CNN 안에서 end-to-end 학습/추론하도록 만듦.
2. 방법
- Region Proposal Network (RPN)
- CNN feature map 위에서 작은 네트워크를 sliding-window처럼 적용.
- 각 위치에서 여러 anchor box (다양한 크기/비율)를 기준으로 proposal 예측.
- cls branch → anchor가 물체인지/배경인지
- reg branch → anchor를 GT에 맞게 보정(offset: tx, ty, tw, th)
- 한 grid cell마다 k개의 anchor 배치 (논문: 3 scales × 3 ratios = 9).
- Anchor pyramid 덕분에 multi-scale / aspect ratio 처리가 추가 연산 없이 가능. 기존 image pyramid / filter pyramid 대비 효율적.
- Translation-Invariant 특성 : Anchor가 모든 grid cell에 반복 배치 → 물체가 위치만 바뀌어도 같은 규칙 적용 가능.

Feature 공유 (RPN + Fast R-CNN)
- RPN과 Fast R-CNN이 CNN convolutional feature를 공유 → 연산 낭비 최소화.
- proposal 단계와 detection 단계가 하나의 통합 네트워크로 합쳐짐.
학습 방식
- Alternating training:
1. RPN 학습
2. proposal 고정 후 Fast R-CNN 학습
3. 다시 RPN fine-tuning
4. 다시 Fast R-CNN fine-tuning
'Paper_Review' 카테고리의 다른 글
| [jekim] Paper review (2) | 2025.10.20 |
|---|---|
| [jslim] paper review (0) | 2025.09.28 |
| [jslim] Paper Review (0) | 2025.09.20 |
| [gmkim] Paper Review (0) | 2025.09.19 |
| [yjlee]Paper Review (0) | 2025.09.06 |