Scalable Diffusion Models with Transformers
DiT = Diffusion + Transformer
Introduction
diffusion model에서 아키텍쳐 선택의 중요성, 향후 생성 모델링 연구를 위한 경험적 기준선 제시를 목표
U-Net inductive bias가 diffusion model의 성능에 중요하지 않으며 Transformer와 같은 표준 디자인으로 쉽게 대체될 수 있음을 보여줌
결과적으로 diffusion model은 확장성, 견고성, 효율성과 같은유리한 속성을 유지하는 것 뿐만 아니라 다은 도메인의 학습 레시피를 상속함으로써 아키텍쳐 통합의 최근 추세로부터 이점을 얻을 수 있음
transformer를 이용한 새로운 diffusion model인 DiT 제시
기존 convolution 계열보다 시각적 인식에 더 효율적으로 확장할 수 있음을 이용한 ViT를 참고
Diffusion Transformer Design Space

noised latent 생성

Patchify
ViT 기반
DiT의 입력 z=(IxIxC)를 T(=(I/P))^2)개의 토큰으로 변환
input인 noised latent representation에서 patch size로 분할
P를 절반으로 줄이면 T는 4배가 됨
p=2,4,8로 설정
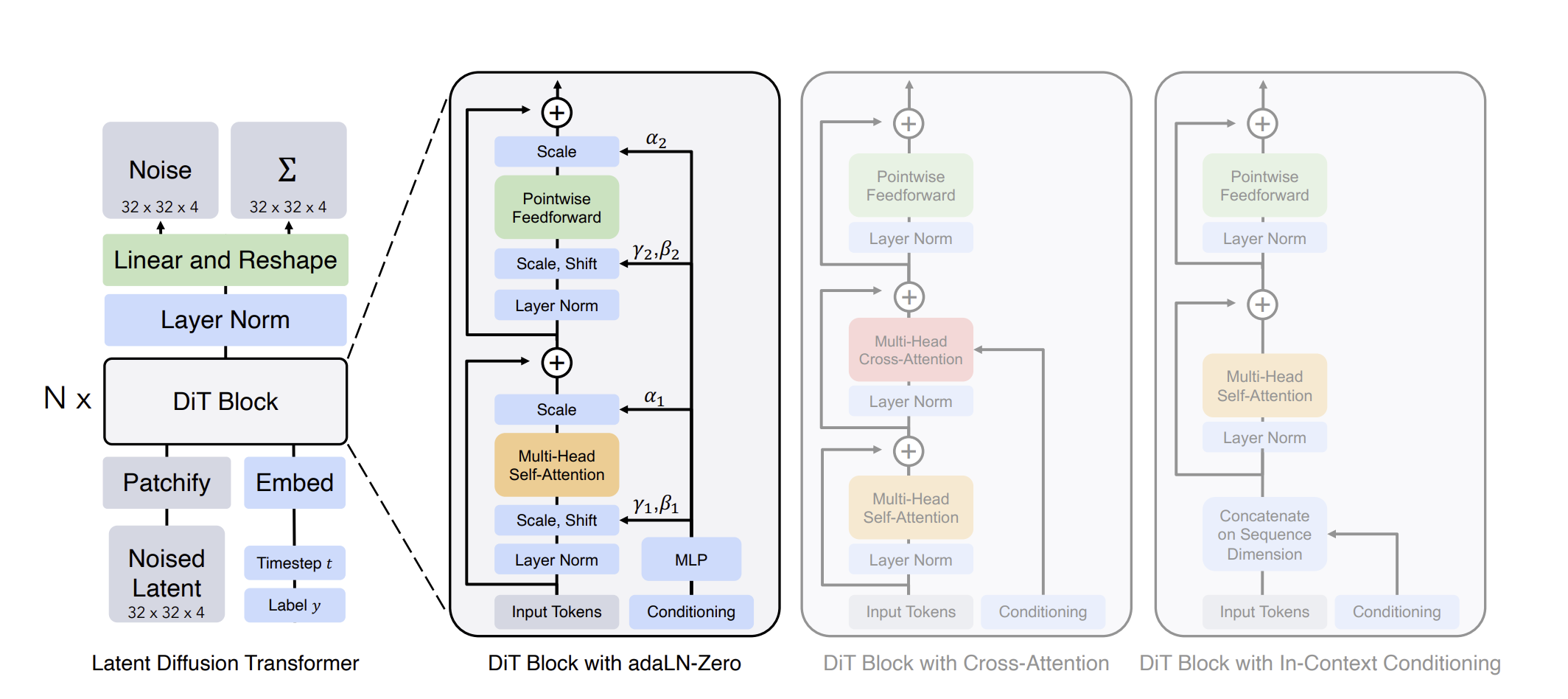
DiT Block Design
conditioning 종류 3가지
1. In-context conditioning
condition도 데이터처럼 다룸 (벡터 임베딩 t, c를 두개의 추가적인 토큰으로 입력 시퀀스에 추가)
condition에 대응하는 출력은 사용하지 않음
2. Cross-attention block
노이즈-데이터 혼합을 query, condition을 key value로 사용
이 두개를 바탕으로 가중치를 구함
timestep embedding과 class embedding을 각각 하나의 토큰처럼 취급해서 image token sequence와 분리된 상태로 transformer에 넣음
cross-attention을 추가해 image token이 class label을 참고하면서 정보를 주고 받음
전체 연산량 약 15% 증가
+ Self-Attention VS Cross-Attention
Self-Attention : query, key, value 모두 같은 sequence (ex)image token)에서 가져옴
imgae token들이 서로를 참고하면서 어떤 관계가 있는지를 학
Cross-Attention : query/ key,value를 다른 sequence에서 가져옴
image token들이 조건 정보를 참고하면서 학습
ex) 강아지 라벨을 참고해 이미지 생성
+ Layer Normalization
표준화
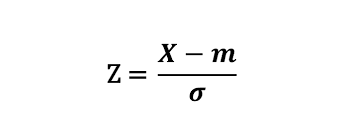
여기에 γ(scale)를 곱하고 β(shift)를 더함 (이때 γ, β는 learnable parameter)

3. adaLN
γ, β를 condition을 활용해 구함
class 정보 벡터인 class embedding을 MLP에 통과시켜 γ, β 를 만들어 냄
=> condition 정보가 layer norm의 γ, β 를 직접 조절
LN이 condition에 따라 adaptive하다 => adaLN한 condition을 MLP에 넣어서 전체 feature에 broadcasting하는 방식
single label conditioning에는 좋음 ex) MNIST처럼 한 class label을 쓰는 conditioning에 적합
variable length conditioning은 고려하지 않음 ex) 자연어 처리 같은 가변 길이 입력에는 적합하지 않음
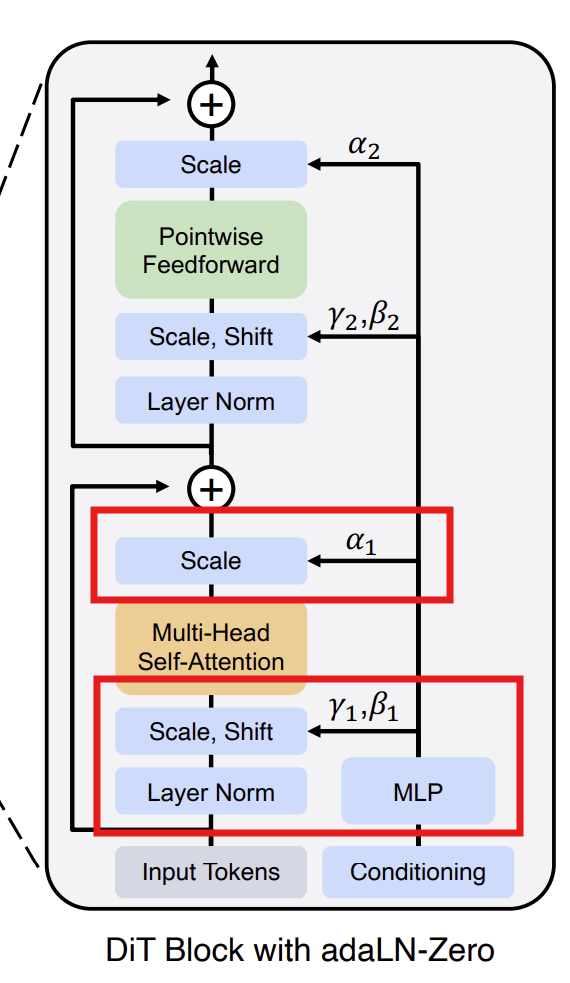
4. adaLN-Zero
attention 직후에 α(scale)를 곱하는 구조가 추가 됨
scale을 곱한 후에 residual connection을 취하는 방식
scale을 0으로 초기화 해서 zero처음 scale=0 => attention 출력 무시, residual connection만 남음=> 처음에는 자기자신을 return하는 함수로 시작

Model size
크기 d의 hidden 차원을 갖는 DiT block을 N개 쌓는 방식으로 모델 사이즈 결정
ViT를 따라 표준 transformer config인 jointly scale N, d, attention heads 를 사용

transformer decoder
layer norm, linear and reshape를 적용한 후 각 patch size바다 기존 channel size의 2배가 되는 output을 출력
output = noise + covariance 이므로 2배가 됨
이후 VAE decoder에 noise 값을 넣어서 실제 이미지 생성
Experiments
GFID-50k : FID (Fréchet Inception Distance) 를 측정하는 표준 설정
FID : 생성 모델이 만든 이미지가 진짜 데이터랑 얼마나 비슷한가를 평가하는 지표
1. 생성 이미지랑 진짜 이미지를 Inception v3 네트워크에 넣음.
2. 그 출력 특징 벡터들의 분포를 각각 정규분포로 근사.
3. 두 분포 사이의 거리를 Wasserstein-2 distance로 계산.
GFID-50k : 5만개의 샘플을 생성해서 계산
=> 생성한 이미지 5만장을 가지고 FID를 계산한 값
값이 낮을수록 진짜랑 더 비슷하다는 뜻.
전체 분포 단위의 평가이므로 전체 분포 유사성 확인
+Inception v3 : 구글이 만든 이미지 분류용 신경망 모델
이미지 특징을 뽑는 역할
+Wasserstein-2 distance : 수학적으로 두 확률 분포가 얼마나 다른가를 재는 거리 척도, 두 가우시안 분포의 평균 차이 + 공분산 차이를 이용해서 계산
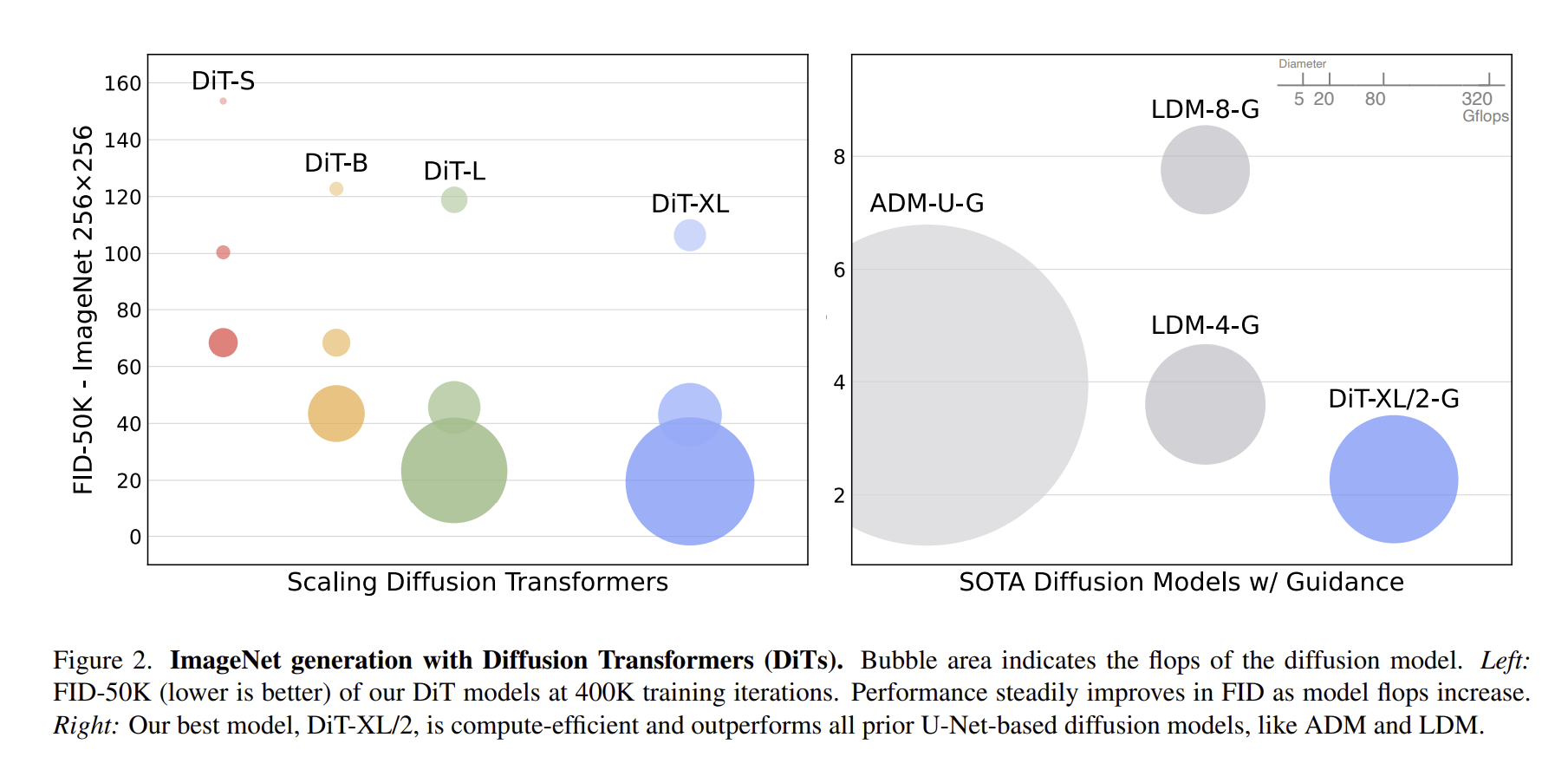
1. DiT block design

가장 큰 Gflops를 가지는 DiT-XL/2 모델에 대해 각기 다른 block 디자인 적용
in-context : 119.4gflops
cross-attention : 137.6gflops
adaLN or adaLN-zero : 118.6gflops
adaLN-zero가 가장 좋은 성능, 이후 실험은 adaLN-zero를 이용
2. Scaling model size and patch size

큰 모델 규모와 작은 패치 사이즈를 갖는 것이 성능이 가장 우수
모델 규모 : 파라미터 수, 레이어 깊이, 차원 수
Visualizing scaling

SOTA diffusion models
256x256 image net

512x512 image net

성능 지표
FID (Frechet Inception Distance)
위에서 설명
IS (Inception Score)
classification에서 이미지 및 그 레이블의 편차의 다양성을 담기 위해 설계된 수치
생성된 이미지가 명확한 분류 결과를 가지는 지, 생성된 이미지들간에 다양성이 있는지를 동시에 평가
1. InceptionV3 모델의 softmax 출력 p(y|x)를 통해 이미지가 얼마나 특정 클래스로 잘 분류되는지 측정
2. 생성된 이미지들의 평균 분포 p(y)와 각 이미지의 (y|x)를 KL Divergence로 비교
IS 가 높음 => 의미있고 다양한 이미지를 생성함
이미지 하나하나가 뚜렷한 객체를 표현하고 있으며, 동시에 다양한 클래스를 포함하고 있음을 의미
MEDMAE: A SELF-SUPERVISED BACKBONE FOR MEDICAL IMAGING TASKS
기존의 많은 모델들은 자연 이미지로 사전 학습 되었으나, 의료 영상과는 많은 차이가 있어 기존 모델을 그대로 사용하면 성능이 저하되는 문제 발생 (domain shif)t
딥러닝 모델이 효과적으로 학습하기 위해 필요한 대규모 라벨링 된 데이터 셋의 부족
=> 라벨이 부족한 의료 데이터 환경에서도 잘 학습하고 다양한 의료 영상 작업에 활용할 수 있는 범용 딥러닝 모델을 만들자
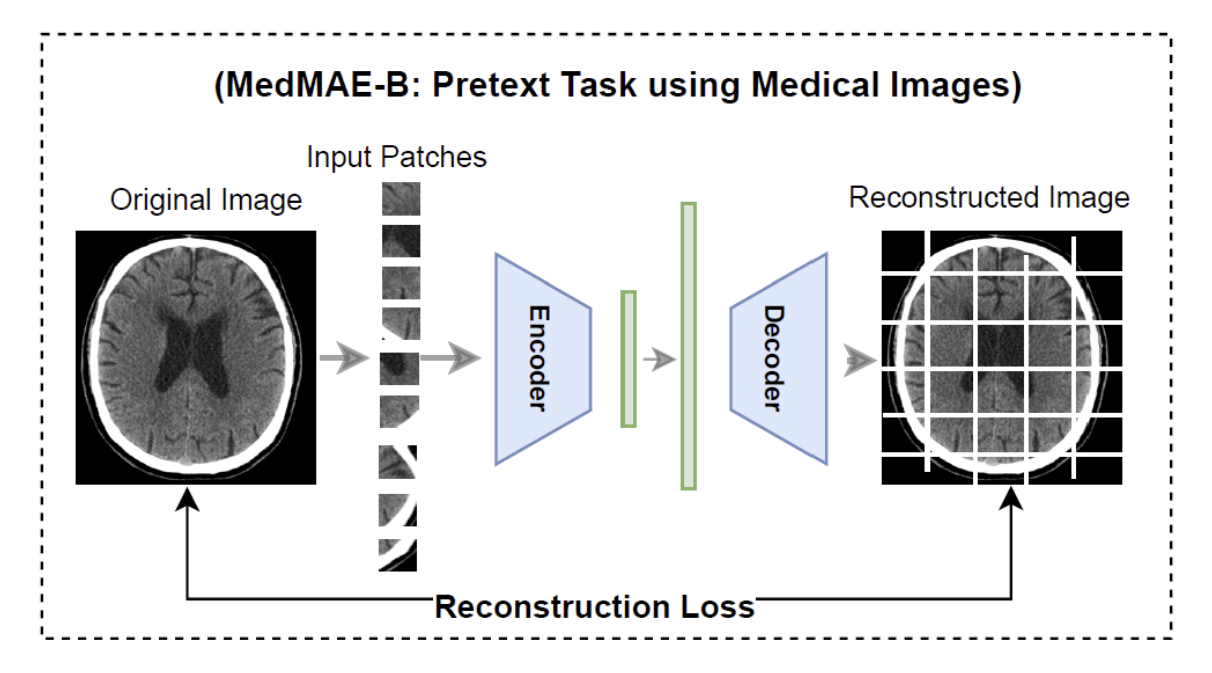
MedMAE 핵심 아이디어
self-supervised learning, SSL (자기 지도 학습)
1. 입력 이미지의 75% 를 마스킹하여 숨김
2. 숨겨진 부분을 복원하는 방법으로 모델 학습
모델이 이미지의 중요한 특징을 스스로 학습하도록 유도하며, 라벨이 없는 데이터에서도 효과적으로 학습할 수 있도록 함
Medical Imaging Dataset
목표 : MedMAE-B를 크고 다양한 의료 영상 데이터셋으로 사전 학습시키는 것
1. latent representations capture :방대한 의료 영상들을 처리 => 의료 영상 도메인의 내재적 특성 학습
2. generalizability, versatility 향상
MedMAE Architecture in pre-training
Encoder : visibile patch만 입력
Decoder : Encoder의 출력 + masekd patch를 사용해서 전체 이미지 재구성
Loss function : 마스크된 영역의 픽셀 단위 재구성
Training Workflow
1. 데이터 준비: 여러 소스의 의료 영상 수집 → 중복/손상된 파일 제거 → 전처리 (크기 조정, 포맷 통일)
2. 사전 학습 : MAE 방식 사용 => 입력 이미지의 75% 마스킹 => 인코더가 특징 추출 => 디코더가 전체 이미지 복원
3. downstream task 에 적용
MAISI: Medical AI for Synthetic Imaging
Introduction
의료 영상 분석은 현대 의료에서 핵심적인 역할
이 분야에서 효과적인 ML model을 개발하는 과정은 아직 많은 어려움
1. 데이터 부족
2. 높은 인적 주석 비용
3. 개인정보 보호 문제
최근 생성 모델의 발전에 따라 gan, diffusion model이 연구중
아직 남은 문제들
1. 고해상도 3D 볼륨 생성의 어려움
2. 고정된 출력 크기와 복셀 간격의 제약
3. 특정 데이터셋과 장기에만 특화된 모델
=> 이러한 문제 해결을 위해 MAISI(Medical AI for Synthetic Imaging) 제안
MAISI : 3개의 3D 네트워크로 구성
볼륨 압축 네트워크 (Volume Compression Network), 잠재 확산 모델 (Latent Diffusion Model), ControlNet
Related work
GAN(Generative Adversarial Networks, 생성형 적대 신경망)
Diffusion model 기반 의료 영상 합성
Methodology
1. 볼륨 압축 네트워크(Volume Compression Network, VAE-GAN) 학습
- 39,206개의 3D CT 볼륨과 18,827개의 3D MRI 볼륨을 사용
- 고해상도 3D 의료 영상을 지각적으로 동등한(latent space로 압축된) 잠재 공간으로 변환
- 메모리 사용량과 연산 복잡도를 줄임
2. 잠재 확산 모델(Latent Diffusion Model) 학습
- 10,277개의 다양한 데이터셋에서 얻은 CT 볼륨 사용
- 압축된 잠재 공간에서 작동
- 신체 부위(body region)와 복셀 간격(voxel spacing)을 조건으로 사용
- 현실적이고 복잡한 3D 해부학적 구조를 유연한 크기로 생성 가능
3. ControlNet 통합
- 학습된 잠재 확산 모델에 추가 조건을 주입
- 분할 마스크, 종양 마스크 등 다양한 조건을 받아들여 생성 과정에 반영
- 다양한 작업(조건부 생성, 영상 인페인팅 등) 지원
- 각 작업마다 기초 모델 전체를 재학습할 필요가 없음
'Paper_Review' 카테고리의 다른 글
| [sbpark] paper review(9/20) (0) | 2025.09.20 |
|---|---|
| [jslim] Paper Review (0) | 2025.09.20 |
| [yjlee]Paper Review (0) | 2025.09.06 |
| [jslim] Paper Review (1) | 2025.08.30 |
| [gmkim] Paper Review (0) | 2025.08.30 |