https://arxiv.org/pdf/2412.13059
1. Abstract
고해상도 3D 의료영상(CT/MRI) 생성을 목표로 하는 논문으로, Patch-Volume Autoencoder + BiFlowNet 구조를 도입해서, 병변이나 장기의 디테일(local)과 전체 구조(global) 둘 다 잘 유지하여 generation 품질향상을 목표.
2. RELATED WORK
2.1 GAN 기반 approaches
기존 연구들이 pseudo-3D, sliding-window 방식으로 boundary 문제를 간접적으로 완화한 반면,
본 논문은 Patch-Volume Autoencoder의 two-stage 학습(patch-wise → volume-wise, patch-wise로 훈련된 디코더를 volume-wise에서 고정)과 joint decoder를 통해 구조적 수준에서 boundary-free 3D generation을 달성
2.2 Medical Generative Models for Downstream Tasks
ControlNet을 결합해 pretrained 3D MedDiffusion을 고정시키고, 경량 conditional branch만 fine-tuning하여 controllable generative adaptation을 구현, volume-wise를 통해 boundary artifact 없는 generation이 가능.
ControlNet: 다른 유형의 조건,task-specific condition을 주입. zero conv에서 추가 condition만 학습. segmentation mask, modality, anatomical region 등 다양한 downstream 활용 가능.
3. Method

MedDiffusion 에서는 Patch-wise training과 Volume-wise training 으로 나눔. 조그만한 (64x64x64) patch를 복원하는 모델을 만들고, 그 모델을 1단계로 전체 volume (256x256x256) 을 다루는 모델을 제작.
3.1 Patch-Volume Autoencoder
효율적인 3D 의료 영상 생성을 위해 고해상도 3D 볼륨을 압축된, 의미 있는 잠재 공간으로 매핑하는 새로운 압축 프레임워크.
Patch-wise Training
Patch-wise Training 아키텍처의 흐름은 다음과 같다.
1. 원본 볼륨 512 512 512를 우선 작은 패치의 N개의 64 64 64로 분할
2. Patch Encoder에 3D Conv 통과하여 patch token으로 압축
3. M: 패치 안에서 생긴 토크 개수(예: downsample 비율이 4면 M = (64/4)³ = 16 ³)
C: token 채널(특징)차원
4. vector quantization
Codebook C: 각 token zi를 가장 가까운 코드로 치환
result - quantized된 patch


작은 패치를 압축하고 재구성함으로써 전체 볼륨 처리에 대한 메모리 제약을 극복
Volume-wise Training
1. patch-wise단계에서 훈련된 patch decoder를 joint decoder로 미세 조정. 이 단계에서는 Encoder와 Codebook의 파라미터는 고정하고 decoder만 학습. Encoder와 Codebook을 재사용하는 것.
the parameters of the patch encoder E and the codebook C are initialized from patch-wise training stage and kept frozen during this stage
2. quantized된 latent들을 재배치하여 하나의 volume latent zi를 만듬. 하나의 저해상도 volume latent를 만드는 과정
3. Joint Decoder 학습
Joint Decoder Dj는 전체 volume latent를 받아 한번에 복원 볼륨 출력
which is then decoded by the joint decoder DJ to produce the final reconstruction X˜ = DJ (Z˜) ∈ R H×W×D at once.
중요한 점은, Patch Encoder과 Codebook은 고정되고 Decoder만 학습됨. 즉, patch decoder이 joint decoder로 파인튜닝.
4. Boundary Artifact 제거
Patch-wise에서는 patch들이 독립적으로 복원. boundary 끊어지는 artifcats발생 가능. volume-wise에서는 Joint Decoder를 통해 전체 latent를 한번에 복원하므로 patch들의 boundary artifcats 발생 방지. 연속성 있는 reconstruction 가능
Artifact-free reconstruction. The second stage fine-tunes the joint decoder, enabling seamless full-volume reconstruction without patch boundary artifacts
3.2 BiFlowNet Architecture
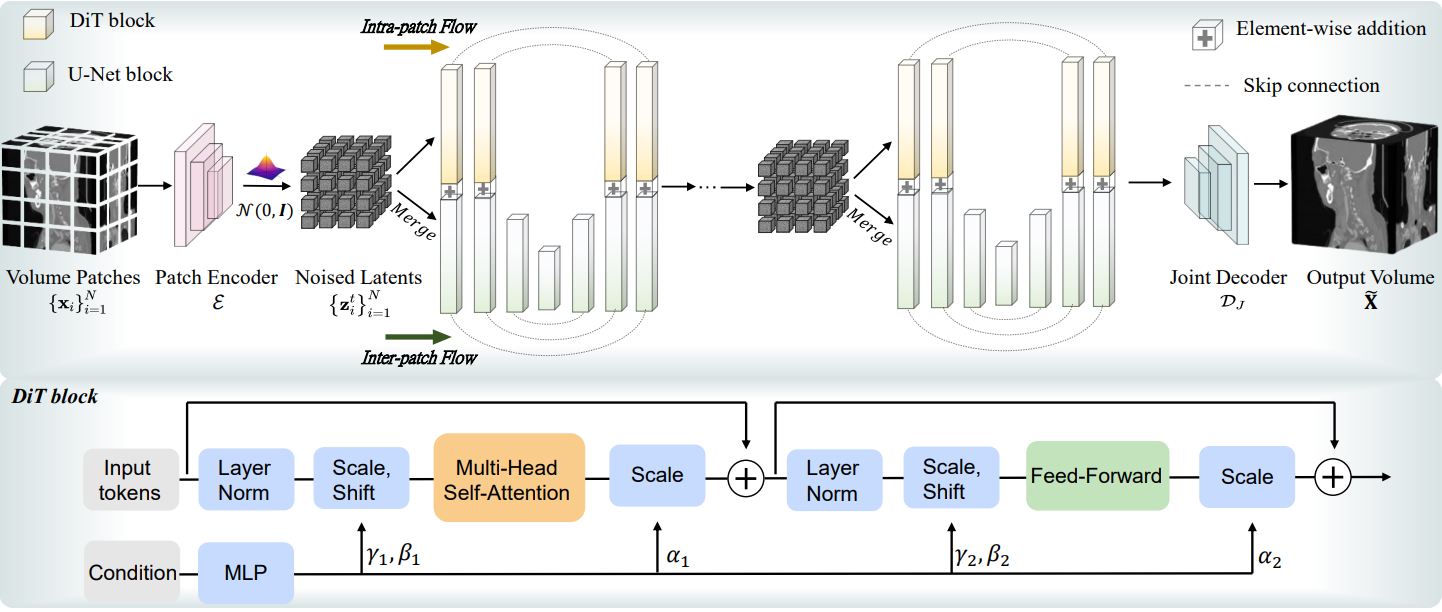

zt는 latent space 상의 3D 볼륨 표현이고, c는 class condition
의료 영상은 local(혈관,boundary,질감)과 전역적인 특징이 동시에 중요하기에 단일 backbone으로는 치우치기 쉬움,
BiFlowNet은 Intra-patch flow을 통해 patch 내부 local 복원, Inter-patch flow을 통해 볼륨 전역 global 구조 유지
U-Net형태의
We opt standard 3D U-Net as the backbone to eliminate computation overhead raised from high-resolution 3D images.
Intra-patch Flow
개별 작은 패치(ex.64)의 세밀한 detail 을 복원하는 데 초점
높은 모델 capacity가 필요하기 때문에 상대적으로 더 깊고 복잡한 구조를 채택
미세 조직, 경계(boundary), 병변 구조 등 세부 특징을 잘 보존
블록 구성은 LayerNorm -> Multi-Head Self-Attention → FFN의 표준 Dit.
이후 time Embedding 및 class embedding을 거친 Condtion MLP가 주입됨.
-> patch단위의 noise local적인 복원 유리
Inter-patch Flow
여러 패치가 모여 이루는 전체(ex.256) 의 consistency 확보
3D U-Net 블록 기반으로 설계
인접 패치 간 관계를 학습하여 연결성을 강화하고, 전역 anatomical structure를 자연스럽게 유지
패치 경계에서 발생할 수 있는 artifact를 줄이고, 장기나 혈관 같은 전체볼륨 수준의 consistency를 연속적으로 이어지도록 보장
3D Conv Encoder에 Decoder, skip connection 형태로 downsample로 global, upsample로 local복원,
-> patch boundary를 넘어서는 global 연속성 확보.
3.3 ControlNet for Downstream task
기존 의료용 diffusion model 연구는 대부분 task-specific training을 해야 했고 task마다 diffusion model 전체를 다시 학습해야하기에 비용 크고 비효율적,

1. segmentation mask같은 추가 task-specific condition 학습.
2. ControlNet encoder로 latent space.
3. zero conv 통해 pretrained BiFlowNet에 연결.
This trainable copy accepts taskspecific condition as input and its output is connected to the pre-trained diffusion model via zero convolutions
'Paper_Review' 카테고리의 다른 글
| [jslim] paper review (0) | 2025.09.28 |
|---|---|
| [sbpark] paper review(9/20) (0) | 2025.09.20 |
| [gmkim] Paper Review (0) | 2025.09.19 |
| [yjlee]Paper Review (0) | 2025.09.06 |
| [jslim] Paper Review (1) | 2025.08.30 |