1. ViT(An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale) (2020)
NLP에서 Transformer의 성공에 영감을 받아, 자연어 대신 이미지를 Transformer에 적용.
어떻게? 이미지를 패치로 분할, 패치들의 선형 임베딩 시퀸스를 Transformer의 입력으로 제공 (이미지 패치가 NLP에서의 토큰(단어)과 동일하게 취급), 그 결과 병렬 처리를 통한 학습시간 단축이 있었고 대규모 데이터셋을 사전 학습시키고, 작은 데이터셋을 대상으로 전이 학습시켰을 때 여러 이미지 벤치마크에서 SOTA에 근접하거나 능가하는 성능 달성.

Transformer는 1차원 token Embedding 시퀸스를 받음, 2차원 이미지(3D Tensor)를 처리하기 위해, 2차원 패치를 flatten한 시퀸스(1D Vector)로 변환함.

input예시, 224 x 224 x 3의 image, patch size: 16 일 시 patch의 개수는 196, 각 벡터의 크기는 patch size와 차원 수로 768, 최종 input은 (196,768) 형태의 시퀀스.
Transformer는 모든 층(layer, L)에서 고정된 잠재 벡터 크기 D를 사용, flatten된 시퀸스를 D 크기로 맞춰주기 위해 행렬 E를 곱함 (선형 투영), 패치 임베딩 시퀸스.
패치 임베딩 시퀸스 맨 앞에, 학습 가능한 Embedding 하나 추가(CLS 토큰, 클래스 토큰이라고 함), 추후 이 Embedding의 출력이 최종 이미지 표현 y로 사용됨.

위치 정보를 보존하기 위해 패치 임베딩에 위치 임베딩을 더함, 이 결과가 Encoder의 입력으로 사용,
이때, 패치 임베딩과 CSL 토큰을 포함한 각 시퀸스들이 쌓여 행렬(N+1, D의 크기)을 만들고
각 위치별로 대응하는 위치 임베딩 벡터들도 쌓여서 같은 크기의 행렬이 되어 연산이 가능하다.
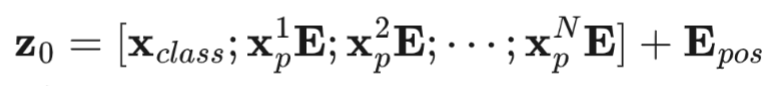

Encoder는 MSA(Multi-Head Self-Attention)와 MLP 블록이 번갈아 배치된 구조로 되어 있음
(각 블록 앞에는 LN(LayerNorm), 블록 뒤에는 잔차 연결(residual connection)이 배치)
-> LN은 한 샘플 내 feature 차원별로 평균과 분산을 정규화, 출력 분포를 일정하게 유지, 기울기 폭주/소실 방지
Multi-Head Self Attention(MSA) Q, K, V 선형 투영 (원 논문 hidden size,임베딩 차원 = 768)하여 벡터와 가중치 행렬을 곱하고 Head분할, 12개의 Head면 768/12 = 64차원의 정보씩 12개의 관점으로 보겠다는 의미
차원 재배열을 하는데, 이 패치 수와 Head의 차원을 재배열하여 각 Head별로 패치의 정보를 담는 구조로 변환.
Q와 K의 내적을 dimension으로 나누는 이유는 수치적 안정성과 학습 효율성을 위함. softmax함수의 편향 및 팽팽해지는 현상 방지.
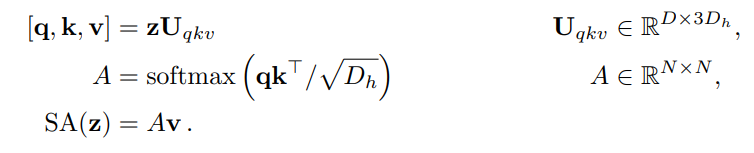
Softmax는 Q와 K를 곱한 값은 값들의 상대적 중요도를 나타냄 하지만 이 값들은 임의의 실수 값으로, 범위도 넓고(매우 크거나, 작음) 또한 음수일 수 있음. 각 점수가 0과 1 사이의 값으로 변환되고, 전체 점수들의 합이 1이 되어 확률처럼 해석하기 위함이고, 변환된 가중치를 V에 곱하면, 값들(V) 중에서 더 중요한 것에 더 큰 가중치를 주어 합산(Weighted Sum)하는 역할을 함. Softmax는 attention논문에서 보았던 exp()로 양수로 만들어주는 내부 과정 또 수행한다.
최종출력은 Residual Connection을 거친 후, 이전처럼 Layer Normalization을 거쳐 차원 유지 후 MLP, 여기서 MLP는 더 풍부한 표현의 역할, 논문에서 활용한 GELU활성화 함수를 통해 모델에 비선형성 도입 등의 역할. 참고로 GELU는 0에서 급격히 변화해 미분이 어려운 ReLU에 비교해 부드러운 비선형성으로 기울기 흐름을 개선한다. 음수 값에 민감한 attention에 효과적이기도. 경험적으로 다양한 벤치마크 데이터셋에서 ReLU보다 우수한 성능도 나타냈다.
이후 마지막 L번째 층의 MLP이후 Residual Connection을 거친 후 Encoder output에서 CLS토큰을 가져와 분류기 head에 입력해 최종 예측을 수행한다.
CLS토큰은 학습 초기에는 아무 의미가 없지만 분류head는 CLS위치의 벡터만 가지고 이 안에 input 전체 정보를 요약하며 모델이 loss를 줄이고자 한다. 즉, learnable하여 input이미지를 대표하는 벡터가 된다.
이전 MLP-Head의 결과로 logitts 값이 출력되고 이를 softmax에 적용해 클래스별 추론 진행.
2. Attention Is All You Need (2017)
Input 문장은 단어 단위로 쪼개져 Word Embedding을 통해 Vector로 변환됨.
Word Embedding Vector에는 순서 정보가 없기 때문에, 위치를 알려주기 위해 Positional Encoding을 더해 최종 입력을 만듦.
각 단어 벡터에서 Query(Q), Key(K), Value(V) 벡터를 생성.
특정 단어(Query)가 다른 모든 단어(Key)와 얼마나 관련 있는지 내적(dot product) 으로 유사도를 계산.
유사도가 큰 Key일수록 그 단어의 Value가 더 크게 반영되도록 가중치(weight) 를 부여.
이때, 유사도가 음수가 되거나 값의 범위가 들쭉날쭉해 학습이 불안정해지는 걸 방지하기 위해 Scaling (1/√dₖ) 과정을 거침.
이후 Softmax를 통해 모든 가중치를 0~1 사이로 정규화하고, 합이 1이 되게 만듦.
최종적으로 가중합(weighted sum) 을 구해 해당 단어의 출력 벡터를 얻게 됨.
→ 즉, Attention = Query와 Key의 내적을 기반으로 Value들의 가중합을 만드는 과정.
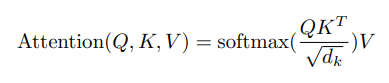
단일 Attention만으로는 다양한 관계를 충분히 학습하기 어려움.
그래서 여러 개의 head를 두어 다양한 관점(문장 구조, 명사, 관계, 강조 등) 에 집중하게 함.
병렬적으로 여러 Attention을 수행한 후 결과를 합쳐 더 풍부한 표현을 얻음.
head의 개수(예: 8개)는 실험적으로 정한 값.

Self-Attention은 처음에는 단순히 단어 간 유사도만 반영하지만,
레이어가 여러 층 쌓이면 단어 하나하나가 점점 맥락(Context) 을 반영한 표현으로 바뀜.
따라서 Encoder를 여러 층 쌓으면 문맥 이해가 깊어지고, Decoder는 이를 바탕으로 문장을 생성할 수 있음.
Encoder: 일반적으로 Mask를 쓰지 않음 (입력 전체 문장 사용).
Decoder: 미래 단어를 미리 보는 것을 방지하기 위해 마스크(Mask) 사용.
Softmax에 들어가기 전, 아직 생성되지 않은 단어 위치에 -∞(매우 큰 음수) 를 더함.
exp(-∞) ≈ 0 이므로, 미래 단어의 가중치는 0이 됨.
따라서 학습 시에는 N-1번째 단어까지만 보고 N번째 단어를 예측하도록 강제.
실제 번역 시에도 입력으로 지금까지 생성된 단어들만 활용하게 됨.
3. MAE(Masked Autoencoders Are Scalable Vision Learners) (2021)
거대 모델을 학습하기 위해서는 수억, 수십억개의 라벨링 데이터가 필요한데 이를 일일이 labeling 수행하는 것은 비효율적이다. 이를 위해 Self-Supervised Learning이 연구되었고 이는 주로 Vision보다는 NLP에서 사용되었던 경향,
- Pretext Task 목표 task가 아닌 label이 없는 데이터를 활용
- 정의된 새로운 task로 Pre traing 진행
- 위에서 학습한 모델을 가져와 weight를 freeze시킨 후 풀고자 하는 Downstream task transfer learning을 수행
-> Masked patch reconstruction 자체를 pretext task로 삼아서 pre-trained weight으로 삼아서 fine-tuning
(비전 트랜스포머를 어떻게 self-supervised-learning해서 성능을 올릴까에 대한 논문)
-> 풀고싶은 특정 task에 국한되지 않고 common feature를 추출해낸다는 장점
NLP와 Vision의 architecture 차이
NLP |
Vision | |
| 토큰의 의미 | 하나의 토큰이 의미론적 단위, 정보 밀도 높음 | 하나의 토큰(패치)은 위치 기반 시각 정보, 공간 중복성(Spatial Redunancy)가 큰 신호 |
| 정보 구조 | 토큰 간 관계는 문맥/의미 중심 | 토큰 간 관계는 공간적·형태적 패턴 중심 |
| 마스킹 시 영향 | 의미론적으로 중요한 단어가 가려지면 전체 문장 해석에 큰 영향 | 일부 패치가 가려져도 나머지 패치로 공간 구조 복원이 가능 |
| 복원 난이도 | 가려진 단어의 의미를 문맥으로 정확히 추론해야 함 (의미 추론 중심) | 가려진 픽셀 패턴·형태를 주변 패치로 유추 (시각 패턴 복원 중심), 픽셀 간의 상관성 따짐. |
| 전이학습 특징 | 언어의 의미 이해가 다른 NLP task에 직접 도움 | 시각적 패턴 이해가 detection, segmentation 등 공간 기반 task에 도움 |
NLP ( High semantic information)
BTS는 7명으로 이루어졌고 대한민국 국적의 가수이다
BTS는 oooo 어졌고 ooo 국적의 가수이다.
Vision (Low semantic information)
위 문장은 주변 단어 ,문장이 Masking되면 해석에 큰 영향을 주는 걸 볼 수 있다. Vision에서는 하나의 토큰이 image patch, 각 patch는 위치 기반 시각 정보를 담고 있으며, 안에 들어있는 픽셀들은 서로 상당히 비슷하다.
이를 spatial redundancy라 부르고 주변 패치의 정보만으로도 해당 패치의 모양이나 색을 꽤 정확하게 유추 가능한 특징
AutoEncoding
- Encoder–Decoder 구조로 representation 학습
- Encoder: 입력 → Latent representation
- Decoder: Latent + mask token → 복원
MAE : input에 noise를 가하고, 이를 다시 복원하는 구조, 즉 원래 이미지에 Mask를 가하고 Mask된 이미지를 복원
Masked image encoding
- Masking에 의해 망가진 이미지로부터 표현을 추출하는 방법.
- 이전연구인 BEiT 에서 사용하였고 Token단위를 사용했지만 MAE는 픽셀 단위로 재구성하는 방법 사용
- BEiT는 Tokenizer을 따로 가져와야 한다는 점, 확정이 어렵다는 한계점
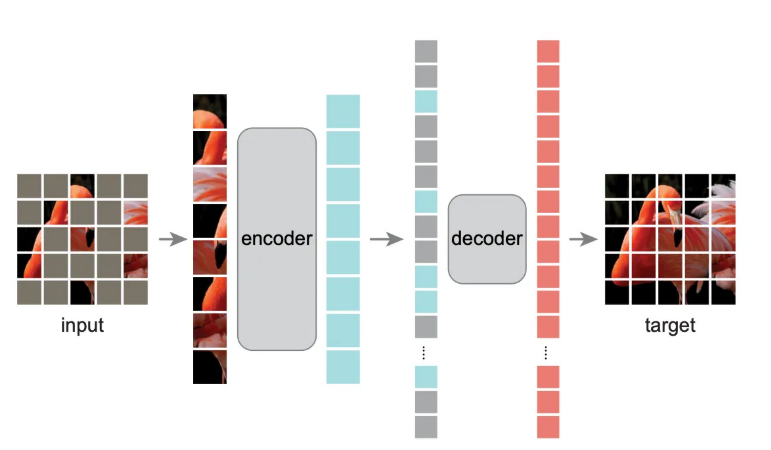
input
- image를 n x n patch로 나눔 (Vit의 기본 16x16 patch)
- 그림에서 회색 블록이 마스킹된 patch이고, 컬러 블록은 visible patch
- 한 번에 전체 패치의 75%를 random masking -> uniform distribution 사용으로 (bias 방지)
encoder
- Vit의 encoder 구조를 그대로 사용
- visible patch(25%)만 input으루 입력받고 masking(75%)은 여기서 사용하지 않음 → 연산량 절감
- 인코더는 크고 무거운 구조로, 보이는 패치에서 의미 있는 표현(latent)을 추출
- image representation 생성
image representation
- 이미지의 의미 있는 특징(semantic feature)을 압축적으로 담은 벡터.
- CNN에서의 feature map과 비슷하지만, MAE/ViT에서는 패치 단위 토큰 시퀀스로 표현.
- 원본 픽셀 데이터 → 고차원 의미 공간으로 변환된 형태.
- 이 representation을 이용해 디코더에서 마스크된 부분 복원(사전학습 단계), Downstream task(분류, 검출, 분할 등)에서 입력으로 활용.
decoder
- encoder 출력 뒤, mask token을 붙여서 전체 image를 복원할 준비를 함 (visible patch + mask token)
- Lightweight Transformer 구조: 얕고 폭이 좁음, pretraining cost를 줄이고자 함이 목적
- 모든 image 위치에 대한 픽셀 값을 예측
- pre-traing 과정에서만 image reconstruction task를 수행하기 때문에 encoder와 무관한 독립적 decoder design
Target & Loss
Target: 원본 이미지의 마스킹된 픽셀.
Loss: Predicted image vs. Original image (마스크 영역만 MSE Loss 계산).
Visible patch에 대해서는 Loss 없음.
4. 3D-LDM(LDM3D: Latent Diffusion Model for 3D) (2023)
(change detection task 수행하며 보완 예정)
텍스트 프롬프트와 노이즈가 추가된 잠재 벡터를 입력으로 받음.
KL-Autoencoder 학습: RGB 이미지와 깊이 맵을 함께 latent 공간으로 압축/복원 가능하도록 학습 (채널 구조 수정 포함)
Diffusion 모델은 주로 2D convolution layer로 구성된 U-Net backbone 아키텍처를 사용. latent 공간에 노이즈를 추가한 뒤 U-Net을 통해 복원하는 과정을 텍스트 프롬프트가 CLIP + cross-attention을 사용하여 다양한 layer에 매핑.
output: latent 벡터를 decoder로 복원해 RGBD 6채널 출력 → RGB 이미지 + depth map 생성
change detection
https://competitions.codalab.org/competitions/17094
Conditional Diffusion Models for Medical Image,
'Paper_Review' 카테고리의 다른 글
| [gmkim] Paper Review (0) | 2025.09.19 |
|---|---|
| [yjlee]Paper Review (0) | 2025.09.06 |
| [gmkim] Paper Review (0) | 2025.08.30 |
| [eschoi] [논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2025.08.30 |
| [eschoi] [논문리뷰] Generative Adversarial Nets (1) | 2025.08.29 |