Concept.
Adversarial Nets
생성모델(Generative Model) G: 실제 데이터의 분포를 흉내
판별모델(Discriminative Model) D: 데이터를 실제 데이터인지, G가 생성한 데이터인지 구별.
G의 goal: D의 실수(실제 데이터와 생성 데이터를 구별하지 못하도록 하는 것)를 최대화
D의 goal: 실제 데이터와 G의 생성 데이터를 정확히 구별
minimax game: 반대되는 목표를 가진 두 플레이어로 봄(D는 손실을 최소화 vs G는 손실을 최대화)
Markov Chain: 컨셉상으로는 '현재 상태가 다음 상태를 결정하는데에 모든 정보를 가지고 있다'. Boltzmann Machine, Restricted Boltzmann Machine(RBM), Deep Belief Network(DBN) 같은 생성모델들은 Markov chain monte carlo(MCMC)라는 방법을 써왔음 -> 근데 이 방법이 느리고 학습도 어려움.
-
배경.
generative model은 데이터 분포 자체를 학습해서 새로운 샘플을 만드는게 goal
그러나 본 논문 발표 당시에는 discriminative model이 더 좋았음. 왜냐?
gen model 학습 시에는 maximum likelihood estimation(MLE)같은 확률적인 method를 사용하는데, 확률 분포의 적분이 계산 불가능인 경우가 많다. 그래서 근사를 해야하는데 근사 계산량 자체도 크고 학습이 느리고 부정확해지는 원인이 되었음.
또한 ReLU같은 piecewise linear함수는 discriminative model에서 쓰기 좋음. 근데 generative에서는 쓰기 어려움
문제를 정리하면?
확률 계산, Markov chain, 근사
directed graphical model & undirected graphical model(both are has latent variable)은 unnormalized potential function의 곱으로 나타나야함. 근데 모든 상황에 대해 다루기에(리소스적으로) 부담이 되기 때문에(=정확히 계산하기도 불가능). 그래서 MCMC로 근사계산을 해야하는데 여러 문제가 있었음.
대안으로 Deep Belief Network(DBN) 시도. 맨 위층은 undirected layer(RBM) + 아래쪽 여러 층은 Directed layer
층별로 하나씩 학습하는 Layer-wise pretraining이라는걸 시도해서 빨라지긴 했으나, RBM의 단점인 partition function의 학습어려움 + directed model의 단점인 inference가 어렵다는 점을 모두 가짐.
여러 모델들은 log-likelihood를 최대화하는 방식으로 학습하는데 DBN, DBM은 partition function const때문에 계산이 어려움. 그래서 Score-matching, NCE같은 대안적 criteria가 나왔으나 여러 문제가 있었음.
그런 점에서 GAN은 노이즈 분포를 고정하지 않고 D를 별개로 학습시켜 G를 계속 압박하기 때문에 학습둔화 문제는 적게 나타남
(NCE는 데이터vs고정노이즈를 계속 구별하는데, 학습 초반에는 빠르지만 금방 쉬워짐. 전형적인 노이즈들 때문에...)
확률분포를 수식으로 정의하지 않고, noise(~sample) generative machine 자체를 학습하는 생성 모델의 idea
이 분포의 확률이 얼마다! 라고 하기는 어렵지만 샘플을 그릴 수는 있다...
-> backpropagation으로 모델을 직접 학습시킬수있다(partition f를 쓸 필요가 없음)
Markov chain 기반 모델들은 feedback loop가 필요함(샘플을 만들기 위해서는 이전 출력을 다시 입력으로 넣어야함)
근데 이러한 구조에서는 ReLU가 문제(y=x파트 때문에 무한히 커짐). GAN은 피드백 루프가 없어서 ReLU의 장점을 그대로 살릴 수 있다
-
algorithm.
GAN은 상기한대로 generative vs discriminative 구도의 프레임워크.
여기서 사용한 디테일은 아래와 같음
G: random noize(z)를 input -> MLP를 통과 -> 샘플 생성
D: MLP로 진짜인지 가짜인지 판별
이 과정에서 그동안 쓰이던 backpropagation & dropout 그대로 사용가능
approximate inference & MCMC같은 느리고 반복적인 그런게 없다 -> 샘플링은 forward propagation 한 번으로 끝
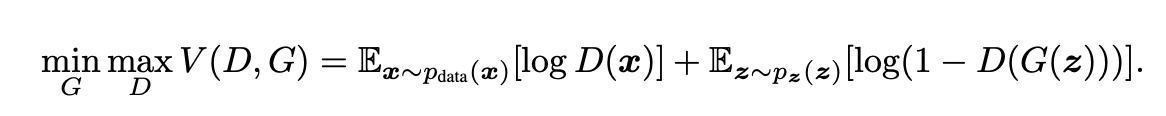
실제데이터 x에 대해 D(x) 로그 확률값의 평균 + 노이즈 z기반 가짜 샘플에 대해 D가 가짜라고 판단할 확률의 로그 평균
로그를 쓰면 -> 곱연산을 합연산으로 바꿀 수 있음 + vanishing gradient 방지(grad가 0에 가까운 상태가 되면 학습이 스탑. 근데 log가 그라디언트를 더 크게 만들어줘서 더 잘 흘러가게 만들어줌)
enough capacity에서는 D(x)=1/2로 수렴. 왜냐? D는 더 이상 진짜와 가짜를 구별할 수 없음(p_g=p_data; G가 만든 분포 = 실제 데이터 분포)
근데 이걸 practical하게 하긴 어려운게 계산량이 너무 크고 데이터셋이 유한해서 overfitting 발생함. alternating training 방법으로 D를 k번 업데이트하고 그 다음 G를 1번 업데이트하는 방법을 씀.
(알고리즘 pseudo code)

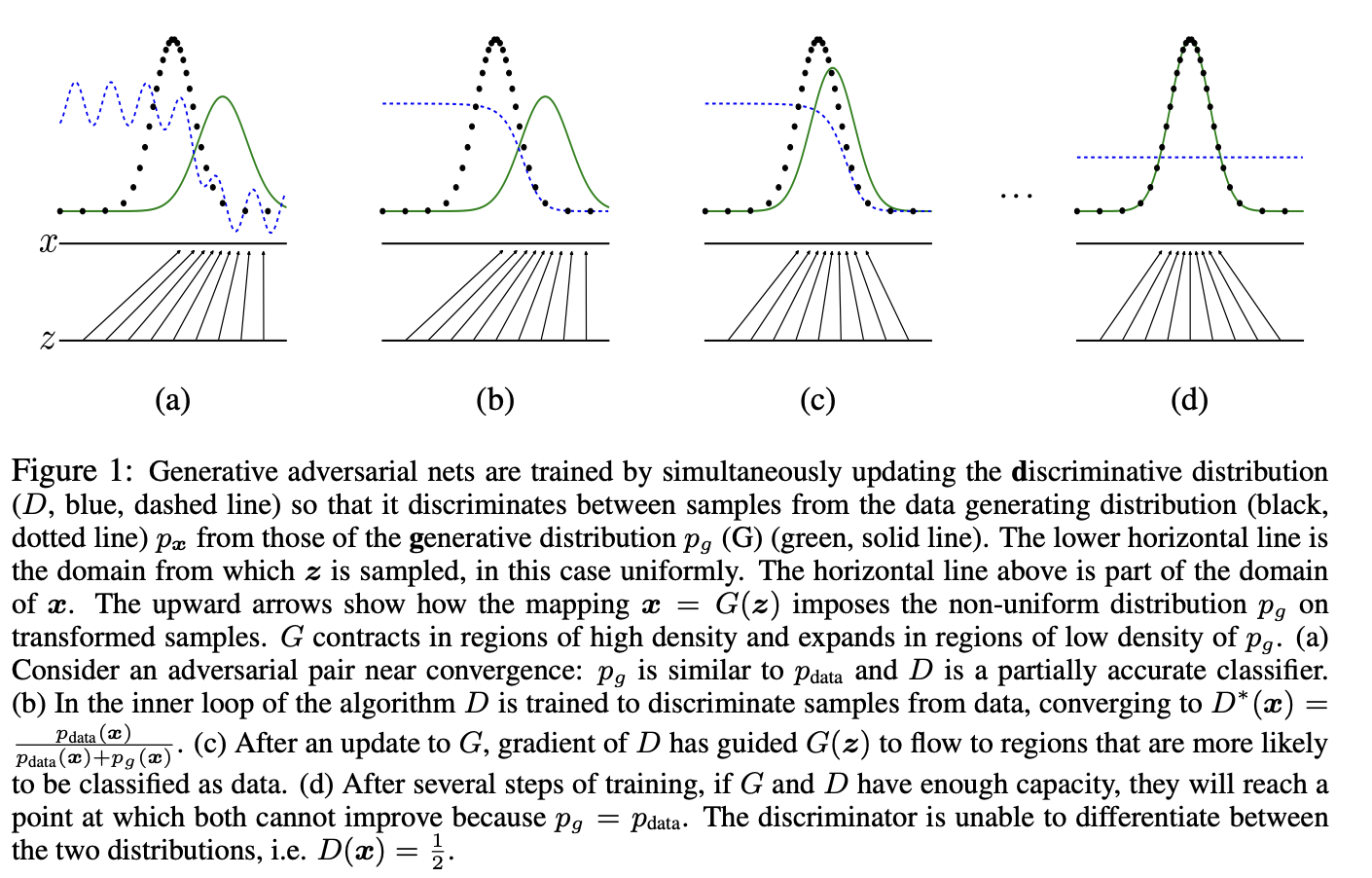
(a) G와 D는 초기에 미숙함 -> 경쟁 시작
(b) D가 점점 진짜/가짜를 잘 구분함
(c) D의 피드백으로 G가 더 진짜 같은 샘플을 만듦
(d) 결국 G의 분포 = 데이터 분포 → D는 진짜/가짜를 전혀 구별 못함(D=0.5)
-
prop 1.
G를 고정한 상태에서 최적 D는
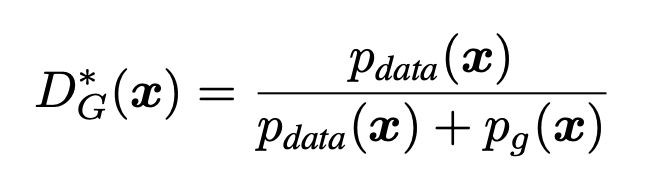
근데 여기서 p_g=p_data -> D*_G(x)=1/2. 즉 C(G)=-log4 ~ Theorem 1
prop 2.
G와 D가 충분한 capacity에 있고, D가 G에 대해 매 스텝에서 최적값에 도달할 수 있다면 G는 점진적으로 p_g->p_data에 수렴.
-

MNIST와 TFD에서 좋은 성능을 보임
-

Training : 싱크로나이징만 잘되면 굳. 근데 Helvetica scenario에 대한 설명이 나와있는데 아직 잘 이해하지 못함.(더 공부해보겠습니다)
Inference: 무언가를 더 넣어야함...
Sampling: forward pass만 하면 ok
Evaluating p(x): 확률 분포를 명시적정의하지 않음. parzen window로 근사해야.
Model design: 임의의 differentiable f 쓸 수 있음. 설계하기 good
-
결과적으로.
Markov chain 필요없음
학습에 backpropagation의 gradient계산만 하면 학습 가능
잠재변수 추론 안 해도 ok
'Paper_Review' 카테고리의 다른 글
| [gmkim] Paper Review (0) | 2025.08.30 |
|---|---|
| [eschoi] [논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2025.08.30 |
| [dhkim] [논문 리뷰] GAN - Generative Adversarial Nets (2014) (3) | 2025.08.22 |
| [hsgo] 8/9(토) 논문 리뷰 (2) | 2025.08.08 |
| [nyyoon] 논문리뷰 - X-Recon: Learning-based Patient-specific High-Resolution CT Reconstruction from Orthogonal X-Ray Images (0) | 2025.03.15 |