DDPM: Denoising Diffusion Probabilistic Models (2020)
기존 생성 모델(GAN, VAE, Autoregressive, Flow-based)은 불안정성, 흐릿함, 느린 속도, 제한된 표현력 등의 한계를 지녔다. 선행 diffusion model은 안정적이었으나 고품질 샘플 생성에는 미치지 못했다.
데이터에 점차 단계적인 Gaussian 노이즈를 더하는 forward diffusion를 정의하고, 그 과정을 되돌리는 Gaussian 역과정, reverse Markov chain을 학습한다. 모델을 “주어진 noisy 이미지에서 추가된 노이즈 ε을 예측하는 함수”로 파라미터화하면 학습 목표가 단순한 MSE(denoising)로 바뀌고, 실제로 고품질 샘플을 생성할 수 있다.
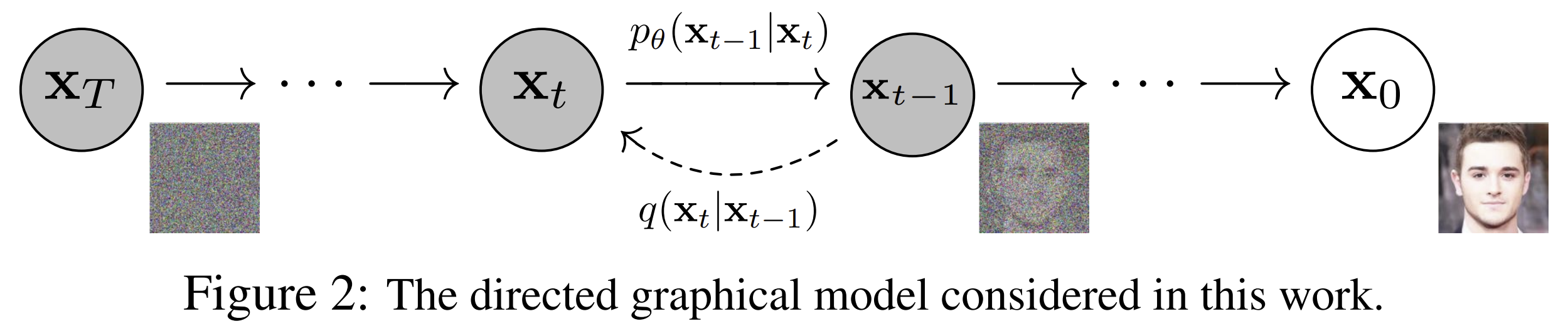
Forwarding (noising) process 정의
원본 x0에 Gaussian noise를 점진 추가하는 Markov chain


Learnable reverse process 모델링
학습 가능한 p_θ로 noise 제거

Simplified loss
Variational lower bound 대신, 네트워크가 실제 추가된 noise ϵ을 예측하도록 단순화
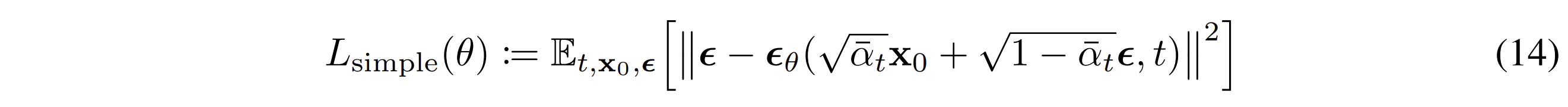

모델 아키텍처 및 학습
- U-Net 기반 구조에 time embedding, residual 및 skip connection 적용
- Linear β-schedule: β_1 = 0.0001 → β_T = 0.02, T = 1000
- Denoising objective로 stochastic gradient descent 수행

LDM: High-Resolution Image Synthesis with Latent Diffusion Models (2022)
기존 Diffusion Model은 고해상도 이미지를 직접 픽셀 공간에서 모델링하는 방식을 택해, 고해상도 계산량이 매우 커 메모리와 학습 시간 문제, 시각적으로 중요하지 않은 저주파 성분까지 학습해야 하는 문제가 있다. 일부 연구는 autoregressive models, GANs, pixel-space diffusion의 multi-scale 접근을 시도했으나 훈련 비용, 모델의 복잡성, 화질 손실 문제가 여전히 남아 있었다.

고해상도 이미지를 직접 생성하는 대신, 압축된 latent space에서 diffusion을 수행하자!!
- 잠재 공간에서의 diffusion: 강력한 사전 학습된 autoencoder의 latent space에 DM 적용
- Perceptual ↔ Semantic Compression 분리: autoencoder로 지각적 무시, latent diffusion으로 의미적 구성 학습
- Cross-Attention 조건부 생성: 텍스트, 레이아웃, 클래스 등 다양한 입력으로 고해상도 합성
- 계산 효율성: 픽셀 DMs 대비 훈련·추론 비용 대폭 절감
Conditioning Mechanisms
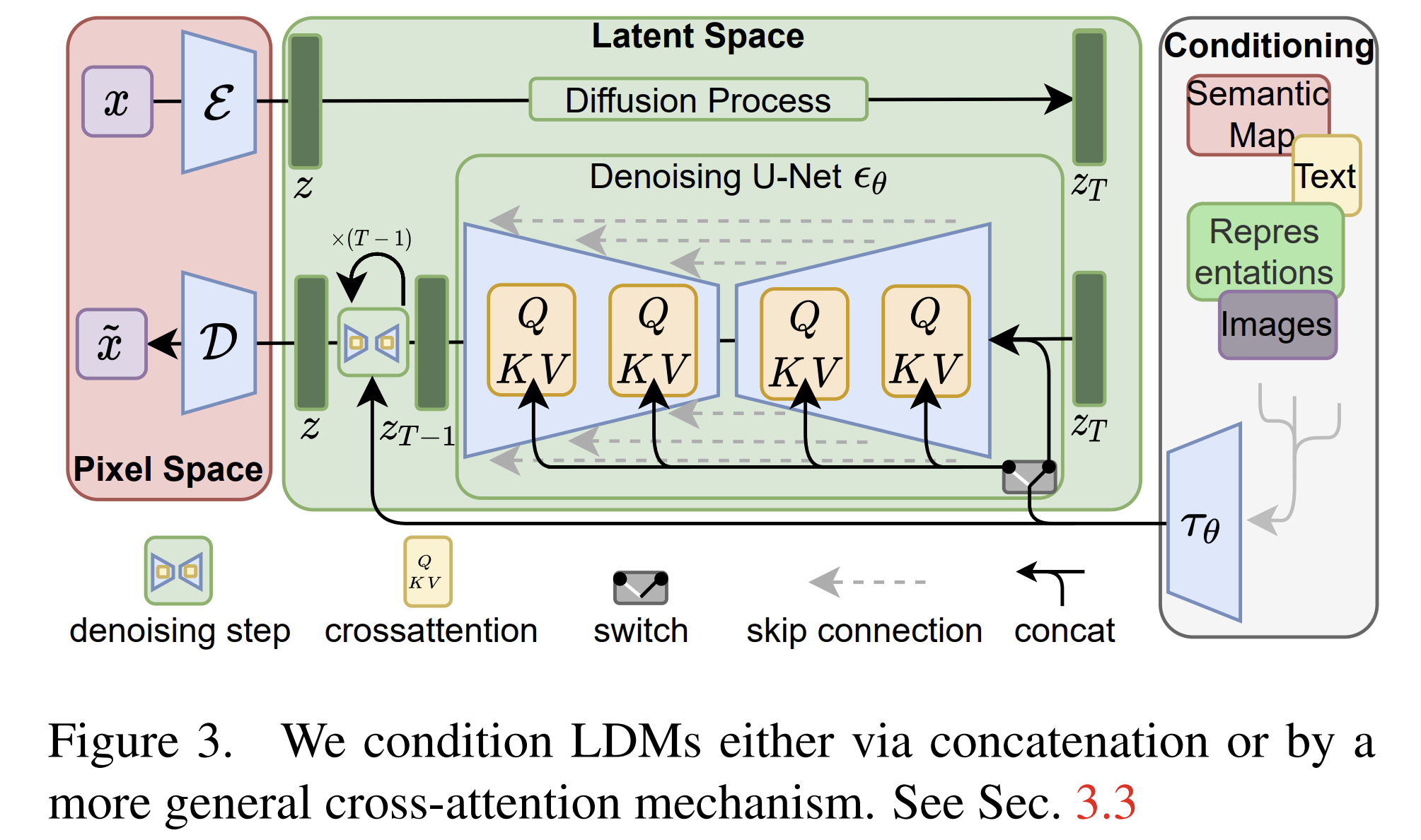
- 토큰 입력(텍스트, 레이아웃 등)을 Transformer로 임베딩
- U-Net 각 블록에 cross-attention 모듈 삽입
- latent vector와 조건 input 정보 상호작용으로 다양한 제어 가능

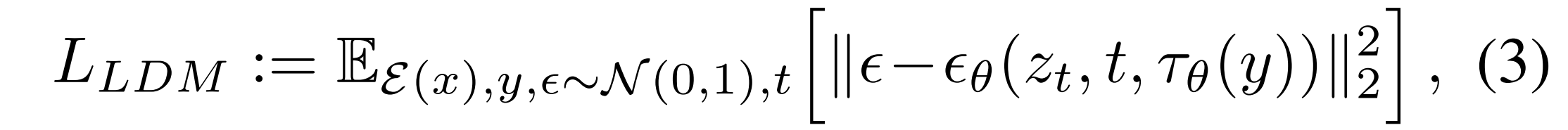
Experiments
Text-to-Image Synthesis

Layout-to-Image Synthesis

Super-Resolution

...
ControlNet: Adding Conditional Control to Text-to-Image Diffusion Models (2023)
Stable Diffusion을 비롯한 text-to-image 모델들은 고품질 이미지 생성이 가능했지만, 여전히 근본적인 한계를 가지고 있었다.
- 텍스트 프롬프트만으로 이미지 생성
- 인물 포즈, 구도, 윤곽선, 깊이 정보 등 공간적 구성 제어의 어려움
- 모델 전체를 fine-tuning 하면 소량 데이터에서 과적합 및 원래 성능 손실 발생
이러한 문제를 해결하기 위한 기존 접근 방식에는 다음의 한계가 존재했다.
- Attention 조작, 단순한 가이드 방식 → 정교한 조건 변환에 한계
- Large model을 조건별로 재학습 → 비효율적, 과적합 위험
ControlNet의 핵심 아이디어는 다음과 같다.
추가 이미지 조건으로 공간을 제어하자!!
다양한 조건의 입력 지원
- Canny Edge Map: 윤곽선 기반 제어
- Human Pose: 사람의 관절 위치 기반 제어
- Depth Map: 깊이 정보 기반 제어
- Segmentation Map: 영역 분할 기반 제어
- Normal Map: 표면 기울기 기반 제어
- User Scribbles: 사용자 손그림 기반 제어
Trainable Copy + Zero Convolution
기존 모델을 보존하면서 조건 제어를 추가하는 구조
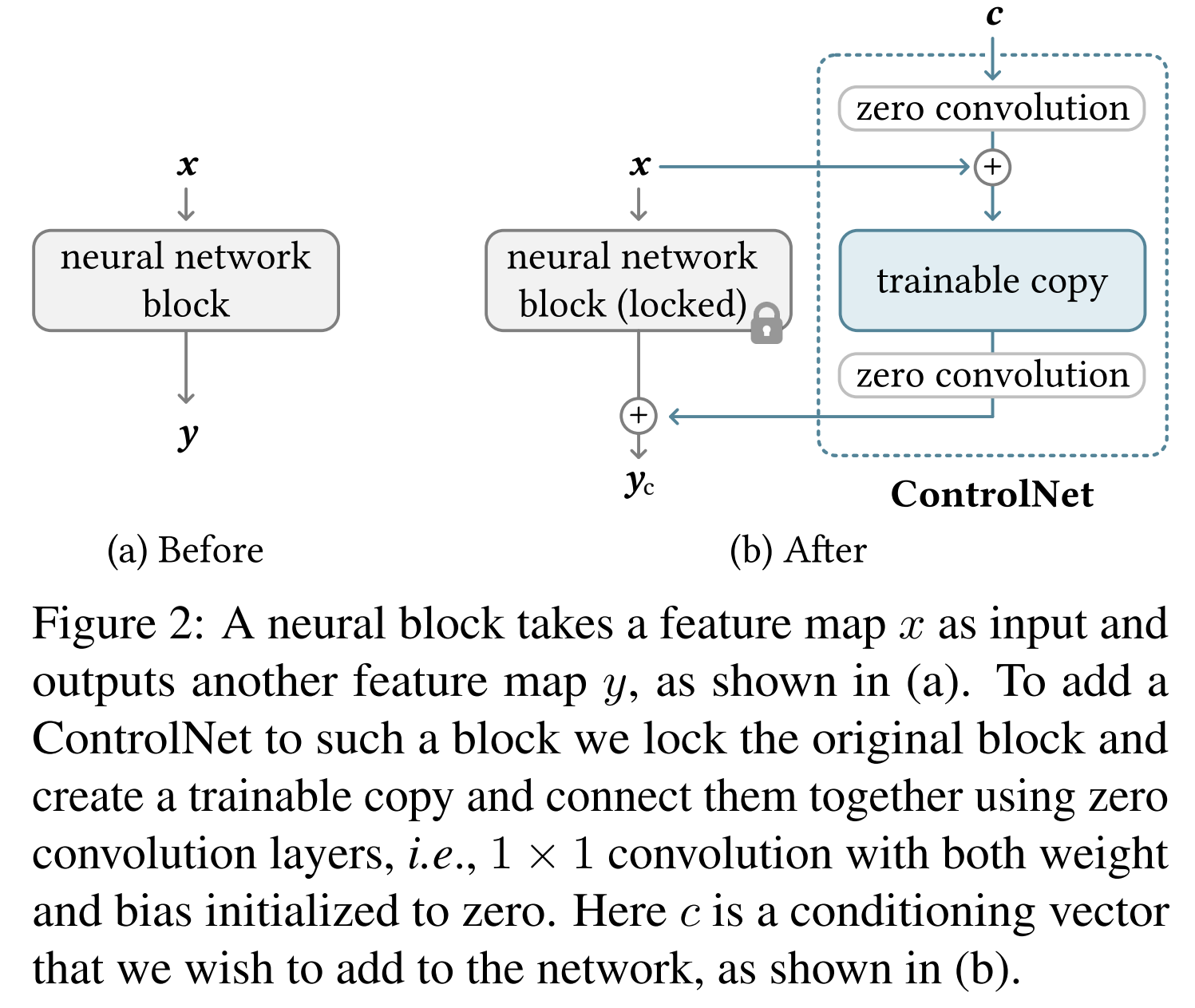
기존 neural block은
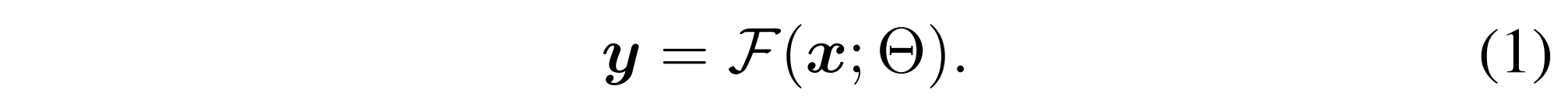
ControlNet은

여기서, Θ는 고정된(frozen) 원본 모델 파라미터, Θc는 학습 가능한 복사본 파라미터, c는 조건 입력 벡터, Z(⋅;⋅)는 zero convolution layer다.
Zero Convolution
ControlNet의 핵심 안전장치
class ZeroConvolution(nn.Module):
def __init__(self, input_dim, output_dim):
super().__init__()
self.conv = nn.Conv2d(input_dim, output_dim, 1)
# weight와 bias를 모두 0으로 초기화
nn.init.zeros_(self.conv.weight)
nn.init.zeros_(self.conv.bias)
def forward(self, x):
return self.conv(x)
첫 번째 학습 단계에 모든 zero convolution이 0을 출력하므로 ControlNet의 출력이 원본 모델과 동일하여 해로운 노이즈가 학습 초기에 영향을 미치지 않는다.
Stable Diffusion과 통합
Stable Diffusion U-Net 구조에서 Encoder 12개 + Middle 1개 블록만 복사하고, 각 복사된 블록에 zero convolution 연결
class ControlNetBlock(nn.Module):
def __init__(self, original_block):
super().__init__()
# 원본 블록 고정
self.locked_block = original_block
for param in self.locked_block.parameters():
param.requires_grad = False
# 학습 가능한 복사본 생성
self.trainable_copy = copy.deepcopy(original_block)
# Zero convolution 레이어
self.zero_conv1 = ZeroConvolution(...)
self.zero_conv2 = ZeroConvolution(...)
def forward(self, x, condition):
# 원본 출력
locked_output = self.locked_block(x)
# 조건부 출력
condition_input = x + self.zero_conv1(condition)
trainable_output = self.trainable_copy(condition_input)
control_output = self.zero_conv2(trainable_output)
return locked_output + control_outputTraining
일반적인 diffusion model과 동일한 denoising objective를 사용한다.
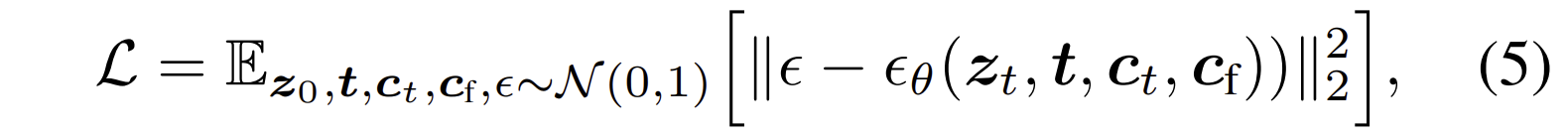
여기서,
- z_t: noisy image
- c_t: text prompts
- c_f: task-specific condition
- ϵ_θ : noise를 예측하도록 학습된 image diffusion algorithm
50% Empty Prompt Training
# 학습 중 50% 확률로 빈 프롬프트 사용
if random.random() < 0.5:
text_prompt = "" # 빈 문자열
else:
text_prompt = original_prompt
모델이 조건 이미지의 의미론적 정보를 더 잘 인식할 수 있도록
Sudden Convergence Phenomenon
점진적으로 학습하지 않고 특정 시점에 갑자기 조건을 정확히 따라가는 특이한 현상
MAISI: Medical AI for Synthetic Imaging
의료 영상 분석 분야가 다른 일반 컴퓨터 비전 분야와 달리 지니는 독특한 한계점들
- 데이터 희소성 (Data Scarcity)
- 높은 인간 주석 비용 (High Annotation Costs)
- 프라이버시 문제 (Privacy Concerns)
여기서, MAISI의 아이디어는
더보기대규모 foundation model을 활용한 고해상도 3D CT 영상의 조건부 생성
기존 접근법이 소규모 데이터셋을 이용해 특정 태스크용 모델을 구성하여 제한적 생성 능력을 보여주었다면, MAISI는 대규모 foundation model을 기반으로 다양한 조건 제어하여 범용적 생성 능력을 추구한다.

- Volume Compression Network (VAE-GAN): 고해상도 3D 의료 영상을 효율적인 잠재 공간으로 압축
- Latent Diffusion Model: 압축된 잠재 공간에서 조건부 3D 의료 영상 특징 생성
- ControlNet Integration: 127개 해부학적 구조를 조건으로 하는 정밀한 제어 생성