
- 논문 작성일: 2024.06.30
- 논문 리뷰 작성일: 2025.03.10
- 제출된 학회: NeurIPS 2024
Abstract
확산 생성 모델(diffusion generative models)의 샘플 품질을 향상시키기 위한 새로운 접근법으로 최대 엔트로피 역강화학습(IRL) 원리를 활용한다.
- IRL과 Diffusion Model의 결합: 역강화학습(IRL)이 전문가 시연에서 학습한 보상 함수를 기반으로 정책을 훈련시키는 것처럼 훈련 데이터에서 추정된 log probability density를 사용하여 Diffusion Model을 훈련한다.
- 에너지 기반 모델(EBM) 활용: log probability density를 표현하기 위해 energy-based models (EBM)을 사용함으로써 확산 모델과 EBM의 훈련 문제로 접근한다.
- Minimax 문제 설정: DxMI는 두 모델이 데이터 분포에 수렴할 때 평형에 도달하는 minimax 문제로 공식화된다.
- 엔트로피 최대화의 역할: 엔트로피 최대화는 Diffusion Model의 탐색을 촉진하고 EBM의 수렴을 보장한다.
- DxDP(Diffusion by Dynamic Programming) 알고리즘: DxMI의 서브루틴으로 제안된 새로운 알고리즘으로 원래 문제를 최적 제어 공식으로 변환하여 확산 모델 업데이트를 효율적으로 만든다. 여기서의 가치 함수(value functions)는 시간에 따른 역전파(back-propagation)를 대체한다.

⇒ DxMI로 단 4~10 단계만으로 고품질 샘플을 생성할 수 있으며 MCMC(Markov Chain Monte Carlo) 없이 EBM을 훈련시킬 수 있어 EBM 훈련을 안정화시키고 이상 탐지(anomaly detection) 성능을 향상시켰다.
1. Introduction
Generative modeling과 모방 학습의 연결성
- 모방 학습자가 전문가의 시연을 모방하는 행동을 생성하듯이 생성 모델은 훈련 데이터와 유사한 샘플을 합성한다. 생성 모델링에서 모방해야 할 전문가는 근본적인 데이터 생성 과정에 해당된다.
Diffusion Model과 행동 복제
- Diffusion Model은 가우시안 노이즈를 반복적인 추가 개선을 통해 변환하여 샘플을 생성함
- Diffusion Model의 훈련은 본질적으로 행동 복제(behavioral cloning)의 한 예에 해당하며 각 상태에서 전문가의 행동을 모방함
- 훈련 중에 Diffusion Model은 노이즈와 데이터 사이를 보간하는 사전 정의된 확산 궤적을 따르도록 최적화됨
Diffusion Model의 한계점
- 행동 복제는 Diffusion Model의 주요 한계인 느린 생성 속도의 원인
- 행동 복제 정책은 상태 분포가 전문가의 시연에서 벗어날 때 신뢰할 수 없으며 훈련과 생성 사이의 격차가 커질수록 확산 모델의 샘플 품질이 저하됨
- Diffusion Model은 일반적으로 1,000단계 이상의 확산 궤적을 따르도록 훈련되지만 실제 생성 시에는 계산 부담으로 인해 더 적은 단계를 사용하게 되어 훈련 단계와의 분포 차이가 발생하게됨
IRL을 통한 해결책
- Diffusion Model의 느린 생성은 IRL(inverse reinforcement learning)을 통해 해결할 수 있음
- 행동 복제와 달리 IRL은 먼저 궤적을 설명하는 보상 함수를 추론함
- Diffusion Model에 적용할 경우에 IRL은 학습된 보상을 사용하여 샘플러를 안내함으로써 더 빠른 생성 궤적을 찾을 수 있게 함
2. Preliminaries
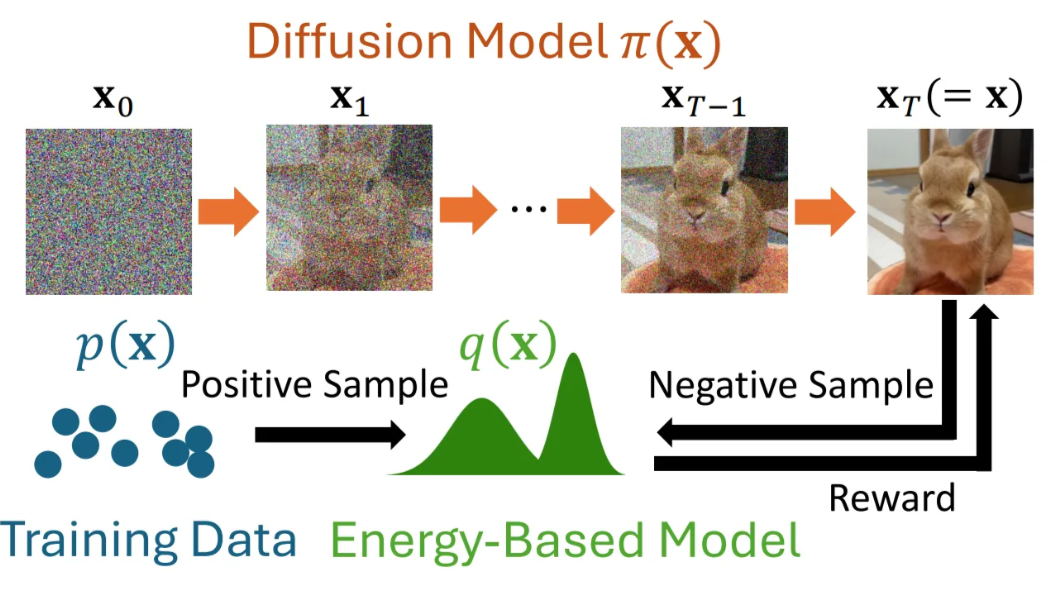
Diffusion Models
$$
\mathbf{x}_0 \sim \mathcal{N}(0, I) \quad \text{and} \quad \mathbf{x}_{t+1} = a_t \mathbf{x}_t + \mu(\mathbf{x}_t, t) + \sigma_t \epsilon_t \quad \text{for} \quad t = 0, 1, \dots, T - 1
$$
- 논문은 DDPM과 같은 이산 시간 확률적 Sampler에 초점을 맞춤
- 확산 모델은 다음과 같은 반복 과정을 통해 샘플 $x₀, x₁, ..., x_T\in\mathbb{R}^D$를 생성:
- $\epsilon_t\sim\mathcal{N}(0, I)$이고 $\mu(x, t)$는 신경망 출력
- $a_t\in\mathbb{R}$와 $\sigma_t\in\mathbb{R}$ : 상수 계수
- 확산 모델의 생성 과정은 보상이 없는 T-horizon 마르코프 결정 과정(MDP)으로 해석 가능
- $s_t = (x_t, t)$ : 상태
- $a_t = x_{t+1}$ : 행동
- $p(s_{t+1} | s_t, a_t) = \delta_{(a_t, t+1)}$ : 전이 역학
- ⇒ 보상 함수가 정의되면 강화 학습으로 훈련 가능
Energy-Based Models (EBM)
$$
q(\mathbf{x}) = \frac{1}{Z} \exp\left( -\frac{E(\mathbf{x})}{\tau} \right), \quad E : \mathcal{X} \to \mathbb{R}
$$
- 에너지 기반 모델 $q(x)$는 에너지 함수 $E(x)$를 사용하여 확률 분포를 표현
- $τ > 0$ : 온도 파라미터
- $\mathcal{X}$ : 데이터의 컴팩트 도메인
- $Z = \int_\mathcal{X}\exp(-\frac{E(x)}{\tau})dx$ : 정규화 상수
- EBM 훈련의 표준 방법은 데이터 $p(x)$와 EBM $q(x)$ 사이의 KL 발산 최소화
- $KL(p,||,q)$의 기울기 계산에는 MCMC 샘플링이 필요하나, 계산 비용이 많이 들고 하이퍼파라미터에 민감함
- 본 논문의 알고리즘은 MCMC 없이 EBM을 훈련하는 대안적 방법 제공
- EBM은 최대 엔트로피 역강화학습(IRL)과 깊은 연관이 있음
- 최대 엔트로피 IRL에서 $x$는 행동(또는 행동 시퀀스)에 해당
- $E(x)$는 전문가의 행동 비용을 나타냄
- 전문가는 $q(x)$를 따라 행동을 생성한다고 가정
- 이는 비용을 최소화하면서 행동의 엔트로피를 최대화하는 최대 엔트로피 원칙을 구현
3. Diffusion by Maximum Entropy Inverse Reinforcement Learning
3.1 Objective: Generalized Contrastive Divergence
Objective
$$
\min_{\color{green}{q \in \mathcal{Q}}} \max_{\color{orange}{\pi \in \Pi}} KL(\color{blue}{p(\mathbf{x})} | \color{green}{q(\mathbf{x})}) - KL(\color{orange}{\pi(\mathbf{x})} | \color{green}{q(\mathbf{x})})
$$
- $q(x)$ : 데이터 분포
- $q(x)$ : EBM
- $\pi(x)$ : Diffusion Model
Contrastive Divergence의 일반화된 형태로 일반적인 Sampler를 포함하도록 확장되었으며 EBM은 확산 모델에 보상 신호로 로그 확률 밀도를 제공한다.
DxMI는 확산 모델과 EBM을 번갈아가며 업데이트하여 Nash equilibrium을 찾는 방식으로 동작
- EBM 업데이트: 에너지 기반 모델은 실제 데이터의 에너지 값을 낮추고 확산 모델에서 생성된 샘플의 에너지 값을 높이는 방향으로 업데이트
- 확산 모델 업데이트: 확산 모델은 EBM에서 예측된 로그 확률 밀도를 보상으로 사용하여 업데이트 → $KL(\pi||q)$를 최소화하는 것
3.2 Alternating Update of EBM and Diffusion Model

- Initializae
- AVR 파라미터 $s_t$를 $\sigma_t$로 초기화
- 에너지 업데이트
- 실제 데이터 의 에너지는 낮추고 생성된 샘플 $x_T$의 에너지는 높이는 방향으로 EBM을 업데이트
- $\gamma$항은 에너지 값이 발산하는 것을 방지하는 정규화 역할
- Value Function 업데이트
- $T-1$부터 $0$까지 역순으로 value function을 업데이트
- 동적 프로그래밍 방식으로 temporal difference learning을 수행
- $\text{sg}[\cdot]$는 stop-gradient 연산자로 해당 부분에 대한 기울기 계산을 중지
- Sampler 업데이트
- 랜덤으로 선택된 시간 단계에서 확산 모델을 업데이트
- reparameterization trick을 사용하여 $x_{t+1}$를 샘플링
- 목적 함수를 최소화
- AVR 업데이트
- Sampler 업데이트
- AVR 파라미터 $s_t^2$를 현재 값과 샘플링된 단계 간 거리의 지수 이동 평균으로 업데이트.
4. Diffusion by Dynamic Programming
- marginal entropy 추정의 어려움: 이산 시간 확산 모델에서는 $\pi(x)$의 로그 확률을 효율적으로 계산하기 어려움
- 시간에 따른 역전파(back-propagation)의 문제: 확산 모델을 통한 기울기 전파는 상당한 메모리를 요구하며 기울기 소실/폭발 문제가 발생할 수 있음
Diffusion by Dynamic Programming (DxDP)이라는 새로운 알고리즘을 제안
4.1 Optimal Control Formulation
- KL Divergence를 직접 최소화하는 대신 data processing inequality에서 얻은 상한을 최소화
- 조건부 가우시안으로 분해된 보조 분포 $\tilde{q}(x₀:{t-1}|x_t)$를 도입 → Diffusion Model의 학습을 최적 제어 문제로 변환
- marginal entropy 계산의 어려움을 conditional entropy로 대체하여 해결
4.2 Dynamic Programming
- Value Function : 미래 비용의 기대 합계
- Policy Evaluation: temporal difference learning을 통한 Bellman residual 최소화
- Policy Improvement: 추정된 가치 함수를 사용한 확산 모델 최적화
- AVR: 보조 분포의 하이퍼파라미터를 체계적으로 결정하는 방법
4.3 Techniques for Image Generation Experiments
- Time-independent value function: 파라미터 수 감소 및 표현 학습 개선
- Time cost: 안정적인 학습을 위해 실행 비용 항을 시간 의존적 함수로 대체
- $\tau$ 파라미터의 독립적 조정: 엔트로피 정규화와 속도 정규화에 대해 다른 값 적용
5. Experiments
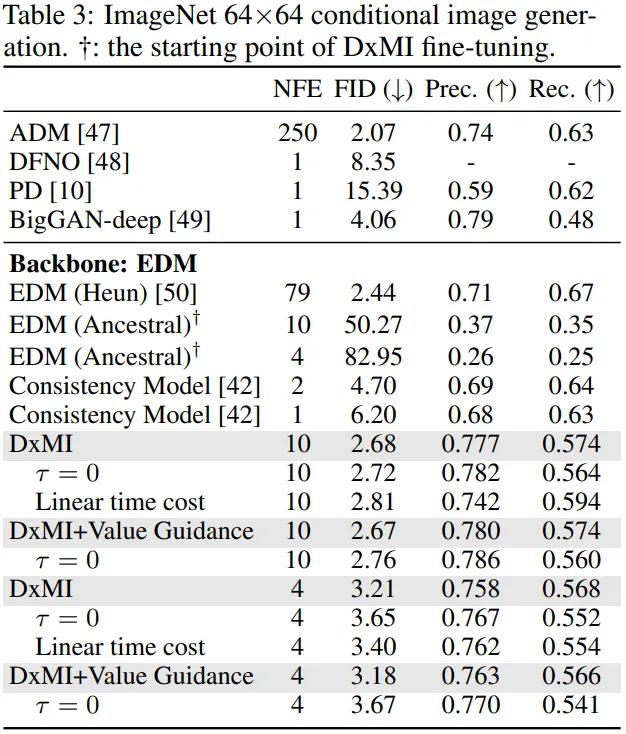
- 3가지 Diffusion Model(DDPM, DDGAN, EDM)을 사용하여 CIFAR-10(32×32), ImageNet 64×64, LSUN Bedroom(256×256)에서 테스트


Energy-Based Anomaly Detection and Localization
- MVTec-AD 데이터셋을 사용하여 DxMI의 Anomaly Detection 성능 확인

6. Conclusion
- DxMI는 diffusion models의 샘플 품질을 향상시키고 EBM을 효율적으로 학습하는 데 기여
- entropy maximization과 dynamic programming을 통해 diffusion models의 탐색과 수렴을 개선
- generative modeling과 anomaly detection 분야에서 유용하게 활용될 수 있으며 여러 하이퍼파라미터 필요에 대한 추가적인 연구는 필요