transformor모델은 점차 standard가 되어가는 중.
Computer Vision에서 Attention은 CNN과 결합(feature map과 결합하거나 convolutional만 대체)해서 사용한다.
그럼 CNN없이 Attention모델만 쓸 수 있지 않을까?
이미지를 token화해서 Transformer모델에 넣으면?
-
업계에서는 Resnet같은 CNN기반 모델이 dominant하다.
specialized attention patterns 때문에 현재 hardware에 맞게 모델이 scaleup되고있지 못하다.
그렇다면 이미지를 split하여 patch화하고, linear embedding을 통해 token화하여 transformer모델에 넣는 아이디어를 제시한다.
-
related work
attention 모델을 image에 쓰려는 시도는 있어왔다.
그러나 모든 픽셀을 attention하기에는 계산량이 너무 많다.
그 동안의 연구에는 여러 아이디어가 있어왔는데,
local attention: 주변 픽셀끼리만 어텐션
sparse transformers: 희소하게 일부만 연결
block wise attention: 블록으로 나누어 어텐션
axial attention: 가로/세로 축으로 어텐션
그 중 가장 ViT와 비슷한건 2 X 2로 나누어 셀프어텐션한 연구. 작은 resolution에만 가능하다는 한계가 있다.
CNN의 feature map에 self attention한 경우도 있다.
pixel 단위로 Transformer모델에 넣되, 연산량을 줄이기 위해 해상도와 색공간을 줄여 비지도학습 한 경우도 있다.
-

- model pipeline
이미지 분할
linear projection of flattened patches(벡터화, token화)
patch에 position embedding & learnable [class] embedding
transformer encoder에 들어감
> multi head attention
> MLP
이 과정을 L번 반복
나와서 MLP Head로 가서 최종 Class 분류 도출. (학습때는 hidden layer 있는 MLP쓰고, fine-tuning때는 단순 선형분류 한다)
-
idea
H X W 이미지, C는 채널수
이 이미지를 P X P크기 patch로 나눔 -> 패치 갯수 N = HW/P^2
class embedding은 이미지 전체를 표현하는 vector (z_L)^0 = x_class.
Q. Embedding할 때 2D로 해야하는거 아닌가?
A. 2D로 하나 1D로하나 크게 차이 없더라. (뒤에서 설명할예정)
-
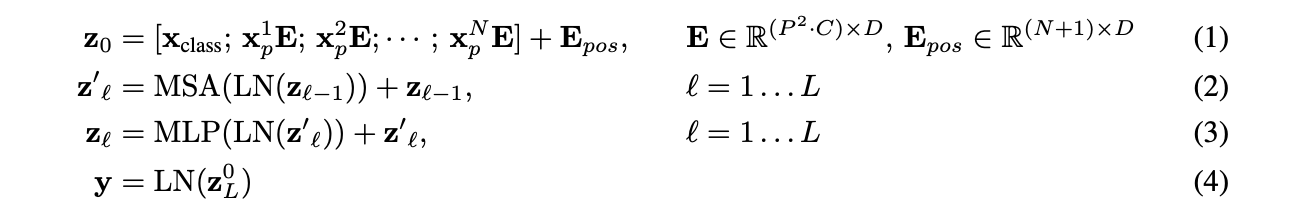
(1) input
x_class: learnable class token
X_num * E: 각 패치의 embedding
E_pos: 위치 embedding
(2) self-attention
z^(l-1)을 layer norm으로 정규화
multi head self attention모델에 넣고 출력 vector 받음
입력 z_(l-1)을 residual로 더함
(3) MLP
z'_l을 layernorm
MLP통과
다시 residual 더함
(4) result
Layer norm해서 출력
-
transformer는 CNN과 달리 이미지 특화구조가 없지 않느냐.(위치, 구조, 각 픽셀간의 관계 등...)
position embedding을 통해 해결
-
이미지를 CNN에 넣고 hidden layer에서 나온 feature map을 patch로 나누어 transformer에 input하는 Hybridㅂ 방식도 있다.
fine-tuning할 때 D X K짜리 레이어만 바꾸면 된다(마지막 분류 레이어. D는 transformer 모델의 출력벡터 크기, K는 downstream 클래스 수)
fine-tuning할 때는 resolution이 큰게 좋다. (original보다 커도 상관없음)
-
Exp.
pretrain할 때는 ImageNet, ImageNet-21k, JFT 등 썼다...
downstream fine-tuning 평가 할 때는 ImageNet CIFAR-10/100, Oxford-IIIT Pets, Oxford Flowers-102 등 썼다. 전처리 Kolesnikov(2020) 방법 따름.

파라미터 수에 따라 모델을 3가지로 나눔
-
패치 크기가 작을수록 토큰 수가 많아져서 계산 량이 많아지더라.
-

사전학습에서 좋았다. natural, Structured task group에서 performance가 좋았다.
데이터 크기가 클 때 좋았다
CNN은 적은 데이터에서 좋았다. 큰 데이터에서는 transformer가 더 놓았다.
ViT는 적은데이터에서 오히려 overfitting이 나더라.
-
linear projection을 막 해도 될까? (4.5)
되더라. 위치 임베딩 있기도 하고, 심지어 2D를 스스로 학습해서 2D 임베딩을 굳이 할 필요가 없더라.
ViT는 local Self Attention하더라
-
왜 좋을까.
무라벨데이터를 많이 학습하는(self-supervised pre-training) 방법... 굳
일부 patch를 가려서 스스로 복원하는 task도 해봤는데... 굳
'Paper_Review' 카테고리의 다른 글
| [jslim] Paper Review (1) | 2025.08.30 |
|---|---|
| [gmkim] Paper Review (0) | 2025.08.30 |
| [eschoi] [논문리뷰] Generative Adversarial Nets (1) | 2025.08.29 |
| [dhkim] [논문 리뷰] GAN - Generative Adversarial Nets (2014) (3) | 2025.08.22 |
| [hsgo] 8/9(토) 논문 리뷰 (2) | 2025.08.08 |