1. DDPM - Denoising Diffusion Probabilistic Models (2020)

이미지에 가우시안 노이즈를 추가하는 diffusion 과정, 이의 reverse인 denoising 과정으로 이루어짐
markov chain : markov 성질을 가지는 이산 확률 과정
markov 성질 : 특정 상태의 확률이 직전 과거의 상태에만 의존, 이산확률 과정 : 이산적인 시간에서의 확률적 현상
ddpm에서 노이즈 이미지는 이전 이미지의 상태에만 의존하여 diffusion 하거나 denoising함 => markov chain

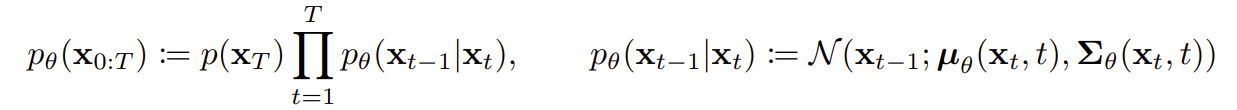

2. LDM - High-Resolution Image Synthesis with Latent Diffusion Models (2022)
latent space에서 dfiffusion model 사용
1. data space와 perceptually equivalent 하면서 lower-dimensional인 latent space를 찾는 autoencoder 학습
2. 찾은 latent space에서 diffusion model을 학습
데이터의 중요하고 의미 있는 정보에 집중, 낮은 computing cost



3. ControlNet - Adding Conditional Control to Text-to-Image Diffusion Models (2023)
텍스트만으로는 복잡한 레이아웃이나 형태를 정확하게 제어하기 어려움 => 이미지를 입력으로 원하는 이미지를 생성

기존의 네트워크를 복사한 후 condition 학습 (Encoder 부분만 복사해서 사용)


t-step 마다 노이즈 이미지 zt와 prompt embedding, time embedding이 input으로 주어지고 노이즈를 제거한 다음 step의 이미지를 output으로 출력하는 Unet 구조에 Control Net을 적용하면 기존 encoder 부분을 복사해 condition을 embedding하는 부분과 decoder 부분은 0으로 초기화한 zero convolution으로 쌓아 Control Net 부분만 학습
4. MAISI
diffusion 모델을 기반으로 고해상도 3D CT 영상 합성
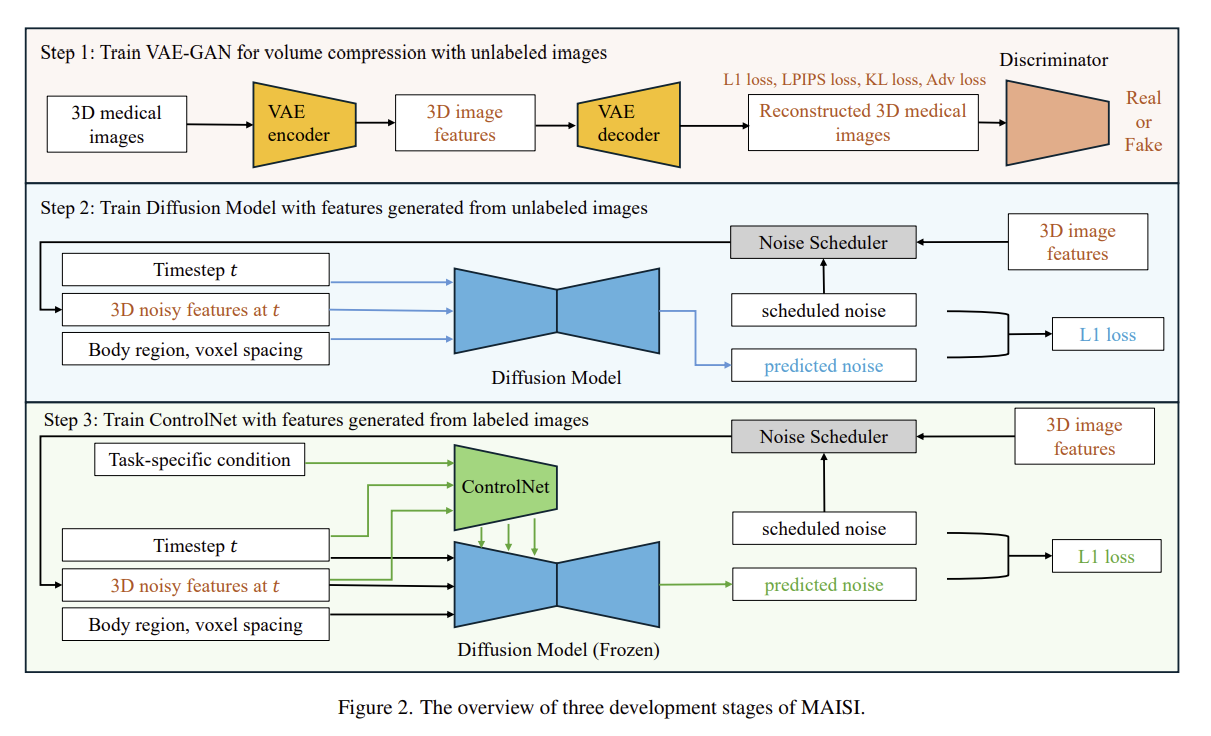
Volume Compression Network : latent space로 압축하기 위해 VAE-GAN 구조 사용
Latent Diffusion Model : 새로운 3D 영상 합성
ControlNet : 세밀한 조건 제어
5. 3D-LLDM
이해한 과정만 대략적으로 정리
1. label과 volume에 대한 인코더 디코더 각각 학습
2. label과 volume에 대한 diffusion model 각각 학습
3. real label을 통해 volume에 대한 diffusion model에 control net 추가해서 학습
4. label에 대한 diffusion model과 디코더를 사용해 label 생성, 생성한 라벨을 volume diffusion model의 control net의 입력으로 사용, 디코더를 통해 volume 생성
6. ViT (Vision Transformer) - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (2020)

이미지를 고정된 크기의 patch로 나누고 각각의 patch를 linearly embedding 하고 position embedding을 해서
transformer 인코더에 input 값으로 넣음
transformer의 input 값은 1차원 시퀀스 이므로 HxWxc 형태의 이미지를 Nx(P^2*C) 형태로 변환해야함
H : 높이, W : 폭, C : 채널 수, N : 시퀀스 수, P^2 : 패치의 크기 N=(HW)/P^2
변환한 이미지 데이터를 patch embeddingd을 통해 D차원의 벡터로 변경
데이터 제일 앞에 class token 추가, class token의 맨 마지막 hidden state는 이미지 전체를 대표하는 특징 벡터 -> 분류에 사용

Xclass : classification token, XNpE : patch로 나눈 각각의 이미지 시퀀스, Epos : positional Encoding(이미지 순서)


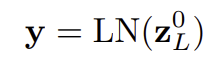
7. MAE (Masked AutoEncoder) - Masked Autoencoders Are Scalable Vision Learners (2022)

이미지를 patch로 쪼갠 후 일부에 마스킹을 함, 이를 통해 정보 과잉을 막을 수 있음
(공간적 중복이 많은 인접한 patch 정보 제거, center bias 문제 방지)
인코더에는 마스킹 되지 않은 patch만 입력 (sub set)
디코더에는 마스킹 되지 않은 patch와 마스킹 된 patch 모두 입력 (full set)
각 마스크 patch의 pixel value 예측

마스킹 비율이 75% 일때 결과가 가장 좋음
'Paper_Review' 카테고리의 다른 글
| [yjlee]Paper Review (0) | 2025.09.06 |
|---|---|
| [jslim] Paper Review (1) | 2025.08.30 |
| [eschoi] [논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2025.08.30 |
| [eschoi] [논문리뷰] Generative Adversarial Nets (1) | 2025.08.29 |
| [dhkim] [논문 리뷰] GAN - Generative Adversarial Nets (2014) (3) | 2025.08.22 |