MEDMAE : A SELF-SUPERVISED BACKBONE FOR MEDICAL IMAGE TASKS
Abstract
medical imaging task의 문제는 라벨링이 된 사용가능한 데이터가 너무 부족하다는 것이다. 이를 해결하기 위해 ImageNet 같이 데이터 양이 많은 것을 backbone 모델에 학습하고 이후에 domain shift를 해서 medical에 알맞게 살짝 fine tuning하는 방식으로 사용하는 방법도 제안되었으나 natural image와 medical image의 domain차이가 너무 크다는 문제가 있다. 우리는 이를 해결하기위해 엄청난 양의 unlabel medical dataset으로 masked autoencoder를 self -supervised-learning으로 학습시켜 encoder를 backbone으로 사용하고자 한다.
Introduction
도메인이 다른 것이 문제가 크다. 그래서 우리는 엄청난 양의 unlabel된 medical 데이터와 ViT backbone을 사용하고자한다.
- medical data : x-ray, mri, ct 다양한 데이터를 사용하고 위,폐,뇌 등 다양한 찍힌 곳을 사용한다.
-Backbone : ViT기반
-train method : Masked autoencoder
MAE방식으로 train하는 이유는 self - supervised learning을 하기위해서다
Method
3.1 medical Image dataset
엄청난 양의 데이터를 모아서 2가지를 해결하고자 했다.
1. Capture Latent Representation
2. Boost Generalization and Versatility : 다양한 task에서 사용할 수 있는 backbone을 만들자
이를 성취하기 위해 우리는 엄청난 양의 dataset을 구축해야했다.

(따로 augmentation은 진행하지 않았다)
3.2MedMAE architecture

- Encoder
visible patch(25%)와 invisible patch(75%)로 나누고 visible patch에 postional encoding해서 encoder에 집어넣는다
- Decoder
2가지를 입력으로 받는다. 첫번짼, encoder에서 나온 visible patches이다. 두번째는 learnable한 mask token을 받는다 이때 위치는 가려진 위치로 넣어준다.
- Loss Function MEDMAE
MSE loss 사용한다. 이때 mse loss는 masked된 patch에서만 사용해준다. 이러한 선택은 뛰어난 결과로 이끌었다.
3.3 downstream task
MEDMae가 학습이 완료된 후 디ㅗ더를 제거하고 각각 task에 맞게 뒤에 layer를 붙여 사용했다.
4. Experiments and Results
epochs : 1000
learning param:
- lr = 1e-3
- batch size = 64
- input size = 224 x 224


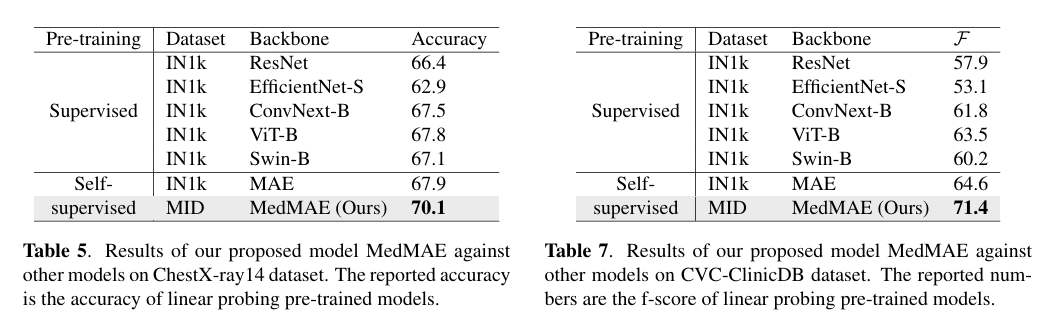
linear probing 만했을 때 나온 결과로 보통 MedMAE를 사용한 우리방식이 좋게 나왔다.
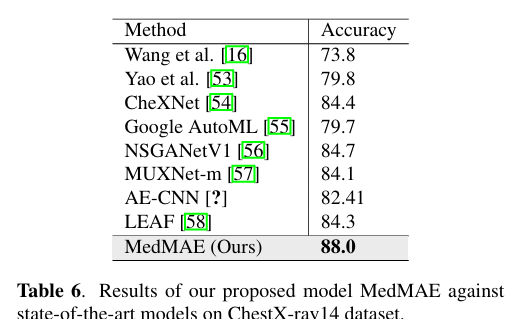
전체적으로 fine tuning 한것도 좋은 결과를 가지고 왔다.
Conclusion
medical image의 부족한 것을 우린 다량의 unlabel 된 medical image dataset을 구축해 ViT기반으로 MAE방식으로 self-supervised learning을 진행해 data의 feature를 잘 뽑아내서 backbone을 만들고자 했다. 그리고 이는 다른 방법들에 비해 매우 뛰어난 성능을 보였다.
생각해볼만한 지점
1. medical image가 부족해서 ssl기법을 사용한건 좋다
2. 지금 비교한 모델들이 모두 imagenet으로 학습했는데 그냥 모델들을 medical image들로 학습시켰다면 ?
3. chest x-ray만 fine tuning한 결과가 있다는점? 다른 데이터 셋은 왜 없을까?
'Paper_Review' 카테고리의 다른 글
| [jslim] Paper Review (0) | 2025.09.20 |
|---|---|
| [gmkim] Paper Review (0) | 2025.09.19 |
| [jslim] Paper Review (1) | 2025.08.30 |
| [gmkim] Paper Review (0) | 2025.08.30 |
| [eschoi] [논문리뷰] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (2) | 2025.08.30 |