https://arxiv.org/abs/2212.08013
FlexiViT: One Model for All Patch Sizes
Vision Transformers convert images to sequences by slicing them into patches. The size of these patches controls a speed/accuracy tradeoff, with smaller patches leading to higher accuracy at greater computational cost, but changing the patch size typically
arxiv.org
FlexiViT: One Model for All Patch Sizes
Abstract
- 기존 ViT는 입력 이미지를 패치로 나누는데, 패치 크기가 속도–정확도 trade-off를 결정함.
- 문제는 패치 크기를 바꾸려면 모델을 다시 학습해야 했음.
- 이러한 패치 의존성의 문제점이 있음에도 패치에 대한 연구가 부족함.(16x16 위주로 사용)
- FlexiViT는 학습 중 패치 크기를 랜덤하게 바꿔 주는 단순한 방법으로, 하나의 모델이 다양한 패치 크기에서 잘 동작하도록 함.
- 분류, 이미지–텍스트 검색, 객체 탐지, segmentation 등 다양한 작업에서 표준 ViT와 비교해 비슷하거나 더 좋은 성능을 보임.
- 따라서 FlexiViT는 추론 시 연산 자원에 맞춰 쉽게 적응할 수 있는 drop-in 개선 방법임.
- 사용 데이터셋: ImageNet-21k dataset
1. Introduction
기존 vit
- 이미지를 patch 단위로 나누어(non-overlapping) token 시퀀스로 처리.
- 이는 CNN이 작은 필터로 겹쳐가며(local, overlapping) 이미지를 처리하던 기존 방식과 큰 차이를 보임.
- Patchify는 ViT에 여러 새로운 가능성을 열어줌 (예: 토큰 drop, task-specific token 추가, multi-modal token 결합 등).
- Patch 크기는 계산량–성능 trade-off를 결정하는 핵심 요소.
- 예시:
- ViT-B/8 → ImageNet Top-1 85.6%, 156 GFLOPs, 85M params
- ViT-B/32 → Top-1 79.1%, 8.6 GFLOPs, 87M params
- 두 모델은 파라미터 수는 비슷하지만, patch 크기에 따라 정확도/계산량이 크게 달라짐.
- 그러나 기존 ViT는 학습한 patch size에서만 잘 작동 → patch 크기를 바꾸려면 모델을 다시 학습해야 함
- (ex. 8x8로 학습 후 32x32로 추론 불가)
FlexiVIT 제안
To overcome this limitation, we propose FlexiViT -> 이탤릭체 사용하기도?
학습할 때부터 patch size를 랜덤하게 바꾸어가며 학습 → 하나의 모델이 다양한 patch size에서 잘 작동.
이미지 자체의 resize는 x.patch embedding을 하는 weights만 resize.
- Patch embedding / positional embedding을 patch 크기에 맞게 adaptive resize.
- 추가 개선:
- 최적화된 resizing 연산 (PI-resize 등)
- Knowledge distillation 기반 학습 → 성능 향상
- 다양한 downstream task 성능 검증
- Classification, Transfer learning, Panoptic & Semantic Segmentation, Image-Text Retrieval, Open-world Recognition
- 대부분의 경우, 기존 fixed-patch ViT와 성능이 비슷하거나 더 우수.
- Transfer learning에서 유용
- 큰 patch size로 저렴하게 fine-tuning → 작은 patch size로 inference 시 높은 성능 유지
- → “학습은 저렴, 추론은 robust 가능
→ 기존 vit에 비해 연산 효율성 + 성능 유지 + 다양한 응용에 유리.
2. Related work
기존 ViT 효율화 연구들은 주로 patchification을 활용해 성능과 계산량을 조정하는 데 집중해왔다.
- 일부 연구는 학습 중 토큰을 무작위로 제거하거나, 중요도가 낮은 토큰을 선별적으로 제거하여 연산을 줄인다.
- 또 다른 연구는 입력 해상도를 조정하여 pretraining 속도를 높이거나 self-supervised 학습의 데이터 증강으로 사용한다.
- Neural Architecture Search(NAS) 계열은 “supernet”을 학습해 다양한 구조(subnet)를 추출하는 접근을 시도하며, SuperViT는 멀티스케일 patch를 ViT에 동시에 주고 토큰을 랜덤 드롭하여 sequence 길이를 줄인다.
-> 이미지 자체를 rescaling하면서 다양한 scale로 나눔. patch size는 동일.
- Matryoshka Representation Learning은 출력 벡터를 meaningful한 subvector로 나누는 방식을 제안한다.
그러나 이러한 접근들은 대부분 특정 해상도나 구조에 고정되어 있으며, 기존 pretrained 모델을 활용하기 어렵다.
3.1 Background and Notation
기존 ViT
입력 이미지와 패치 크기 p를 h와 w로 각각 나눠서 토큰 생성, 각 패치에 positional embedding 추가, Transformer encoder로 전달.
- 가 작으면 → 토큰 수↑, 연산량↑, 정확도↑
- p가 크면 → 토큰 수↓, 연산량↓, 정확도↓
Note that there are only two parts of the model where the parameter vectors depend on the patch size: the patch embedding weights ωk and the position embedding π.
-> Patch embedding weight과 Positional embedding은 패치 의존성을 가짐.
FlexiViT은 이러한 패치 종속성을 없애고 하나의 모델이 여러 patch size를 동시에 다룰 수 있게 하는 게 목표.
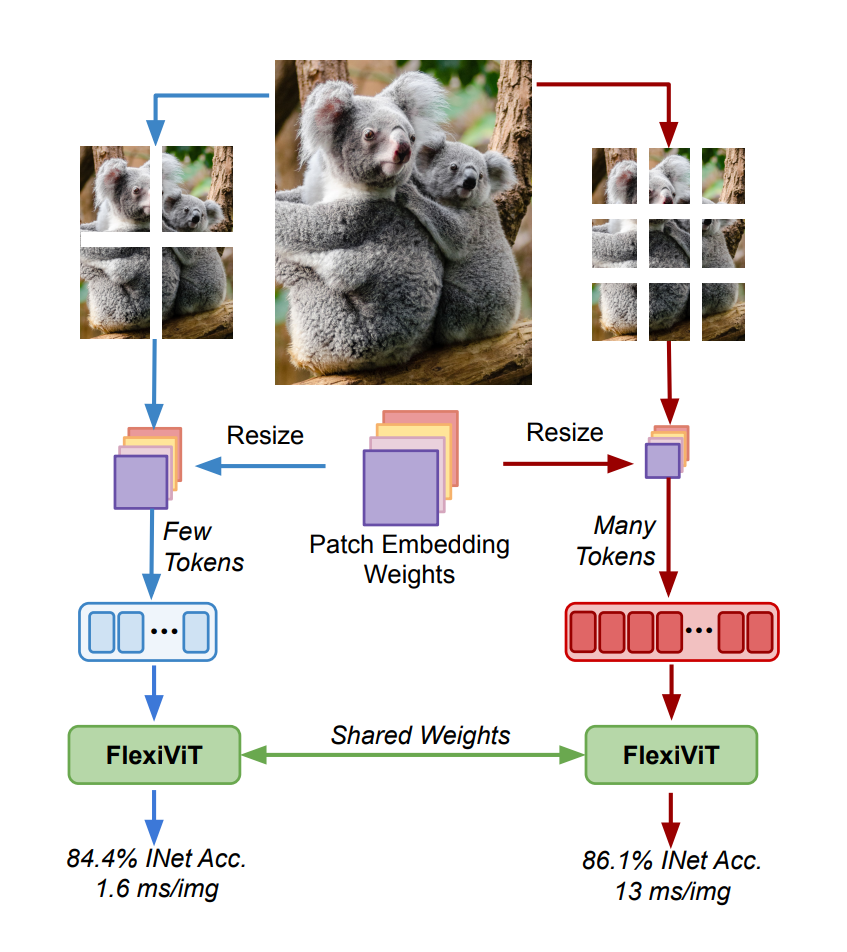
ViT에서 dimension은 아래 이미지처럼 x와 w(오메가)의 내적으로 생성됨.
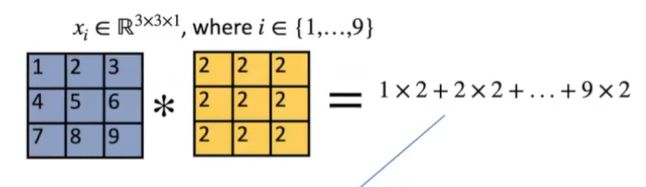
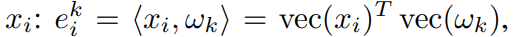
기존의 ViT에서 imput size를 다르게 가져간다면? ( 5x5로 patch size가 달라졌다고 가정)

기존의 3x3으로 학습된 weight는 그대로 fix되어 있기에 그대로 가져와서 input patch와의 내적으로 임베딩 계산.
bilnear interpolation(상하좌우 평균 등 활용) 형태로 5x5가 되어도 inference 수행 가능.
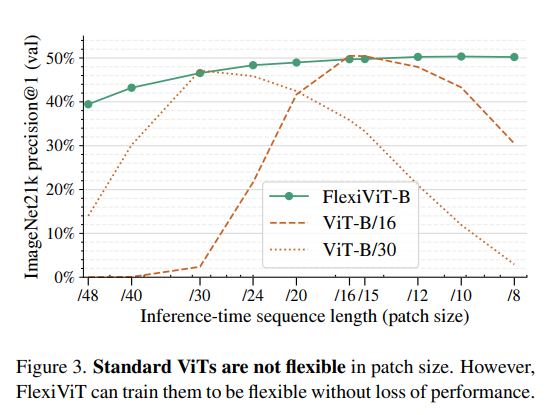
3.2 Standard ViTs are not flexible
아래에서 ViT의 결과는 각 patch size를 제외하고는 성능이 굉장히 떨어지는 것을 볼 수 있음.
즉, 기존 ViT는 학습한 patch size에서만 성능이 좋음.
추론할 때 patch size를 바꿔주면(embedding/positional embedding 단순 bilinear interpolation) → 성능 급격히 하락.
ViT는 즉 고정된 패치 사이즈 추론이 필요하기에 패치 사이즈에 종속됨.
3.3 Training Flexible ViTs

- 학습 시 patch size를 8부터 48까지의 미내배치에서 랜덤하게 샘플링해서 사용.
- 미니배치 내에서 동일한 size로 patch들이 잘리게 됨. patch size가 logit에 들어가 출력.
- 실험 결과: FlexiViT-B는 ViT-B/16, ViT-B/30과 동일 성능을 내면서, 다른 patch size에서도 훨씬 강인한 성능 보임.
초기이미지크기 32 x 32 지정. patch size도 매번 resizing.
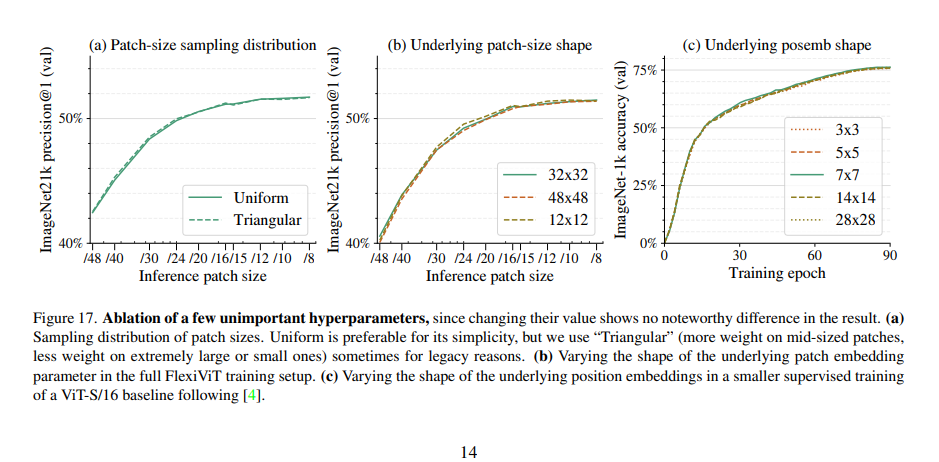
여러 실험 결과 큰 차이는 x.
이후, Positional Embedding동 들어가는 patch size에 따라서 resize가 됨. 여기서 7x7 고정 및 여러 실험도 큰 차이 x.
- Underlying parameter shape
- ω , π를 기준 크기(예: 32×32, 7×7)로 학습 → forward pass 시 on-the-fly resize.
- 다양한 patch size 샘플링
- 이미지 해상도를 240×240으로 고정
- 가능한 patch size: {240, 120, 60, 48, 40, …, 8}
- 학습 iteration마다 균등분포에서 랜덤 선택 ω
-> 코드에서 위 두가지 개선만이 적용
3.4 How to resize patch embeddings
- 위 코드에서 resize는 bilnear interpolation으로 적용 시 magnitude가 거대해지는 문제 발생
- 즉, patch embedding과 입력 패치를 단순 bilinear resize하면, 토큰 크기(norm) 크게 달라져 성능 저하.
- 기존 ViT에서 patch size변환 시 성능 떨어지는 이유도 이에 있음.
- 이미지 해상도를 240×240으로 고정
If we resize both the patch and the embedding weights with bilinear interpolation, the magnitude of the resulting tokens will differ greatly
PI-resize (Pseudo-Inverse Resize) 이용하여 해결
- resize 연산을 수학적으로 선형변환으로 정의
- pseudo-inverse 행렬을 사용해 embedding weight를 변환
- 업샘플링 시 토큰 표현 완벽히 동일, 다운샘플링 시에도 근사적으로 보존
- 단순 bilinear resize 시 내적 값의 스케일이 깨지는 문제

이러한 극적인 변화가 ViT의 비유연성과 학습을 방해하는 inductive bias의 원인이다.
이에 대한 해결책으로 LayerNorm 모듈을 사용하여 임베딩 직후 토큰을 정규화하는 것을 제시.
그러나 이 접근방식 사용 시 패치 임베딩 보존 x.
선형변환으로 표현되는 선형 resize

벡터가 들어왔을 때 interpolation(보간)을 했을 때는 p를 p*로 resize하는 매트릭스로 정의.

다중채널 입력 o의 채널 크기를 독립적으로 조정.
학습과 크기가 달라진 패치의 토큰이 원래 패치와 부합하도록 가중치를 찾는 목적함수 생성필요.
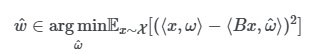
기존 x와 w(오메가)에 대한 내적 수행한것과 새롭게 resize한 x와 w의 차이가 최소화되는 w^을 찾아야함.


Bx와 W^이 같아야하는데, P = 위 공식으로 치환되고, Bx = Px, Pw = W^이 되고, Bx,x^ = x,w가 된다.
즉, bilinear interpolation을 위한 행렬에 transpose를 w에 곱하면 효과적으로 w^ 생성.
이를 통해 모든 x에 대해 패치 임베딩을 정확히 일치시킬 수 있음.
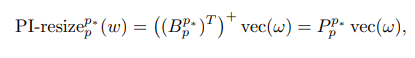
w를 새롭게 resizing, 목적인 p행렬을 w벡터에 곱하는 것. 이는 bilinear resize의 B의 inverse에 해당한다.
또한 패치 임베딩의 가중치를 resize한다.

PI-resize가 다른 resize 기법들보다 안정적 → 성능 저하 완화
차이점 -> 이미지와 패치임베딩을 똑같은 비율로 resizing.
vanila resize -> weight에 bilinear interpolation. norm의 차이로 성능 저하
Area heuristic -> 2x2에서 두배가 늘어났을 경우 area전체에 4분의1을 하여 성능 보완.
저자들의 bilinear interpolation의 역행렬에 pseudoinverse를 구해서 그것의 weight를구하는 Pl-resize의 경우 성능 유지가 잘됨.
학습때부터 고정된 이미지 크기에 대한 다양한 패치 사이즈를 미니배치단위로 적용함.
3.5 Connection to Knowledge Distillation
기존 popular technique Knowledge Distillation
- 큰 teacher 모델 → 작은 student 모델 모방 학습
- 성능 향상은 있지만, teacher와 student 아키텍처 차이가 크면 어렵다.
FlexiViT 활용
- Teacher = 강력한 ViT-B/8
- Student = FlexiViT-B
- Teacher embedding weight를 PI-resize, position embedding을 bilinear resize → student 초기화

random patch size에서 student 출력이 teacher 출력을 모방하도록 학습
- Teacher 초기화 + distillation → 큰 patch size에서도 정확도 크게 향상
- Random init 대비 성능 현저히 우수

3.6 FlexiViT’s Internal Representation
- 질문: FlexiViT는 patch size가 다르면 내부 표현도 달라질까?
- 분석 방법: CKA(Centered Kernel Alignment)
- 서로 다른 patch size에서 얻은 레이어 표현 유사도 측정
- 결과
- 초반 레이어~Block6 MLP 전까지: 표현이 유사
- Block6 MLP에서 diverge했다가, 마지막 블록에서 다시 수렴
- CLS token은 patch size가 달라도 항상 잘 align
> 내부 표현은 patch size마다 달라지지만, 최종 출력은 일관되게 맞춰짐.

학습 시 다양한 패치 단위로 맞춘 후 다양한 task로 fine tuning을 하였을 때 비교대상을 8과 16의 vit와 진행했고 작거나 큰 패치 사이즈에서 우위를 보는 경우들을 볼 수 있고, 하나의 학습에서 다양한 패치를 학습시켜서 추론했는데도 성능이 떨어지지 않음을 보임. classification는 분류 및 segmentation(panoptic).
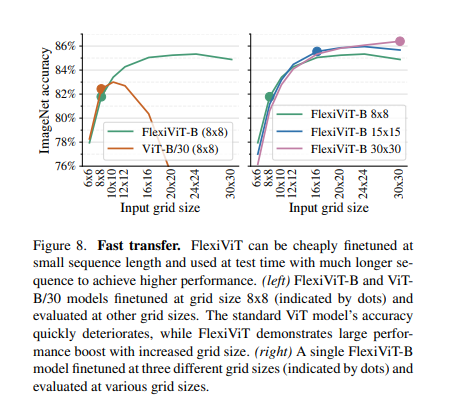
FlexiViT can be cheaply finetuned at small sequence length and used at test time with much longer sequence to achieve higher performance.
8x8로 싸게 학습, 추론할때는 input sequnece길이를 늘려서 ViT에 비해 성능을 더 좋게 만들 수 있음.
즉, 큰 패치사이즈를 써서 학습 비용을 줄이고, 추론할때는 패치사이즈가 더 작게 선택하여 예측 수행.
ViT에 대비한 FlexiViT의 장점.
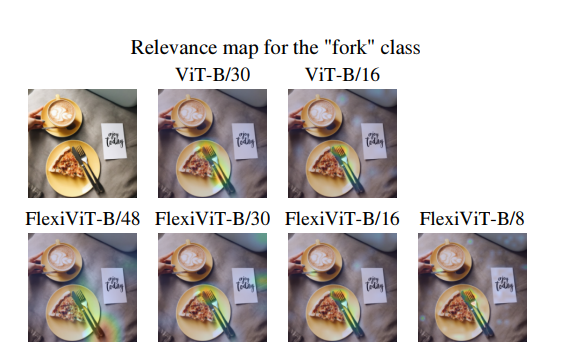
FlexiVit는 패치 사이즈가 작아질수록 더 많은 영역에 attention, 더 많은 영역 포착, 토큰 개수 증가.

패치사이즈가 달라져도 유사헥 attention 수행하는 모습.
https://arxiv.org/abs/1606.06650
3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation
This paper introduces a network for volumetric segmentation that learns from sparsely annotated volumetric images. We outline two attractive use cases of this method: (1) In a semi-automated setup, the user annotates some slices in the volume to be segment
arxiv.org
3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation
기존 Unet 구조
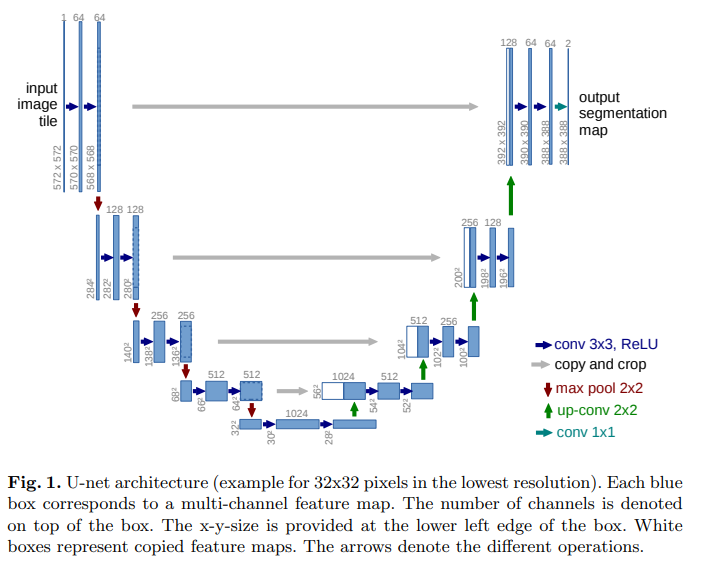
- Contracting Path - 입력 이미지의 Context 포함
- Bottleneck(병목)
- Expansive Path - Expansive path는 입력 이미지의 Localization을 포함
-> 둘을 concat하여 전체 context와 Localization을 모두 고려하는 네트워크를 만들겠다는 의미.
기본 unet 구조 shape
Contracting Path (context 맥락 추출)
- 각 Contracting step마다 3x3 Convolution을 두번씩 반복
- 해당 연산간 ReLU 연산이 포함
- 각 Down Sampling마다 채널의 수는 2배씩 증가
- 2x2 Max pooling으로 인해 feature map의 크기는 절반으로 줄어듬
- 첫번째 3x3 Convolution layer 지나면 572 -> 570 으로 feature map의 크기감소
- 이후 conv에서 570 -> 568로 줄어듬.
- 위와 같은 패딩이 없는 3x3 Convolution layer를 1번 지날때 마다 feature map의 크기는 -2만큼 감소
- 패딩 줄시 feature map 크기 유지
Conv1 shape
- 입력: [1, 572, 572]
- Conv3×3 → [64, 570, 570] (−2)
- Conv3×3 → [64, 568, 568] (−2) ← skip connection 1
- MaxPool 2×2 → [64, 284, 284]
Conv2 shape
- Conv → [128, 282, 282]
- Conv → [128, 280, 280] ← skip connection 2
- MaxPool → [128, 140, 140]
-> downsampling 반복
Bottleneck(병목)
- Contracting path와 Expanding path를 연결하는 중심부분
- 입력 이미지의 가장 추상적이고 고수준의 표현을 학습
- Conv → [1024, 30, 30]
- Conv → [1024, 28, 28]
Expansive path
- 입력 이미지의 가장 추상적이고 고수준의 표현을 학습
- 이미지의 공간차원을 점차적으로 확장시켜나가며 세밀한 localization 학습
- 각 Expanding step마다 2x2 Up-Convolution을 반복하며, 해당 연산간 ReLU 연산을 포함
- 각 Up-sampling마다 채널의 수는 2배씩 감소하지만, 크기가 2x2 Up Convolution으로 인해 feature map의 크기가 2배씩 증가
conv1 shape [C, H, W]
- Up-Conv: [1024, 28, 28] → [512, 56, 56] -> 디코더 feature map 채널 수 줄어듬.공간 크기는 upsampling으로 2배 증가(stride = 2)
- skip connection [512,64,64]를 crop 하여 [512,56,56] 으로 맞춘 뒤 concat
- Conv → [512, 54, 54]
- Conv → [512, 52, 52] conv 수행
conv2 shape
- Up-Conv: [512, 52, 52] → [256, 104, 104]
- kip connection [256,136,136] crop 하여 [256,104,104] 으로 맞춘 뒤 concat
- 각 Up-sampling마다 채널의 수는 2배씩 감소하지만, 크기가 2x2 Up Convolution으로 인해 feature map의 크기가 2배씩 증가 -> [512,104,104] input shape 만들고 아래 conv 수행
- Conv → [256, 102, 102]
- Conv → [256, 100, 100]
3,4 도 반복 수
최종 output -> [segmetation class, 388,388]
segmetation class -> 최종 클래스(label)개수
Skip Architecture (resnet과 차이)
- 그림의 회색 화살표 - 인코더 단계에서 나온 feature map을 → 같은 해상도의 디코더 단계로 concat
- 디코더가 업샘플링한 coarse feature와 Concat하여 추상적인 context와 세밀한 local정보 동시 활용 정밀한 segmentation 효과
- skip connection crop 이유 -> unet의 인코더는 padding x. conv마다 해상도가 2씩 줄어서 upsampling 시 해상도가 인코더 디코더의 skip connection이 일치하지 않음. 인코더의 skip을 2분의 1 crop하여 맞춘 뒤 concat.
3D Unet
기존 unet의 문제점은 2d, 의료 영상의 대부분의 데이터는 3차원 구조이고 형태는 [D,H,W]와 같은 구조임. 깊이, 너비, 높이.
때문에 기존 unet은 3차원 이미지 구조에서 특정 슬라이스를 잘라와 2차원 형태로 변호나 후 학습 진행. -> 3차원 정보 손실
-> 3D unet 등장.

2d unet과 유사한 구조이지만 깊이가 더 얕음. 3D 연산이기에 과도한 연산량 방지.
3D Unet shape
Input: [3, D, H, W]
-> 의료 3차원 이미지,영상 보통 채널 = 3
Conv → [32, D, H, W]
Conv → [64, D, H, W] 형태
- Conv1 → [32]
- Conv2 → [64]
- MaxPool ↓
- Conv3 → [64]
- Conv4 → [128]
- MaxPool ↓
- Conv5 → [128]
- Conv6 → [256]
- MaxPool ↓
- Conv7 → [256]
Bottleneck
-
- Conv → [256]
- [256 + 256 = 512]
- Conv → [256]
- Up-conv upsampling → [128] 채널 수 감소
- Conv → [128]
- Conv → [64]
- Conv → [3] (segmentation class 수)
- context local 정보 결합
Introduction
medical 분야에서 3D 데이터(volumetric data)는 많이 존재합니다. 하지만 이러한 데이터를 annotate하는 것은 매우 어려운 일입니다. 왜냐하면 컴퓨터 화면에서는 오직 2D 단면만 시각화.
이웃하는 단면들은 서로 거의 동일한 정보를 갖고 있기 때문에 이를 하나하나 annotation하는 것은 매우 비효율적.
즉, 3D 데이터의 전체 단면에 대해서 annotate하는 것은 매우 효율적인 방법이 아니며 크고 질 좋은 데이터셋을 만드는 것이 어려움.
3D 데이터의 전체 단면이 아닌 일부 단면에 대해서만 annotate된 데이터를 필요로 하는 네트워크를 제시합니다. 3D U-Net은 아래의 그림과 같은 두 가지 방법으로 사용될 수 있음.

(a) Semi-automated segmentation : 사용자가 segment될 각각의 volume의 몇 개의 단면만 annotate합니다. 그리고 네트워크는 dense segmentation을 예측. 즉, sparsely annotated slices로 부터 dense annotated slices를 예측하도록 학습
(b) (b) Fully-automated segmentation : 사용자 개입 최소화, 네트워크는 representative training set의 annotated 단면으로 학습을 하고 non-annotated volumes을 예측, 흔히 이루어지는 segmentation task , Fully-annotated volumes로 학습한 후, non-annotated volumes을 예측
nnunet
,
'Paper_Review' 카테고리의 다른 글
| [jyhan] paper review (0) | 2025.11.01 |
|---|---|
| [jekim] Paper review (2) | 2025.10.20 |
| [sbpark] paper review(9/20) (0) | 2025.09.20 |
| [jslim] Paper Review (0) | 2025.09.20 |
| [gmkim] Paper Review (0) | 2025.09.19 |