1. A2FSeg Adaptive Multi-modal Fusion Network for Medical Image Segmentation (MICCAI 2023, pp673-681)
https://link.springer.com/chapter/10.1007/978-3-031-43901-8_64
Abstract.
- MRI는 Multi-modal brain tumor segmentation에서 중요한 역할을 하지만, 임상 진단에서 특정 모달리티가 누락되는 경우가 흔하며, 이러한 결손이 분할 성능의 저하를 초래함
- 뇌종양 분할을 위한 단순하지만 효과적인 적응형 다중모달 융합네트워크(A2Fseg)를 제안함 → 누락된 모달리티를 처리하여 분할 성능 향상에 기여
1) Simple average fusion
2) Attention 메커니즘을 기반으로 한 Adaptive fusion
- 모달리티 누락 환경에서도 추가적인 데이터 수집 없이 다양한 영상 조합에 적응가능하며, 실제 병원 데이터 환경과 유사한 조건을 반영할 수 있음.
Keywords.
- Modality-adaptive fusion, Missing modality, Brain tumor segmentation, Incomplete multi-modal segmentation
*모달리티 → 의료 영상 모달리티. MRI/CT/PET/X-ray 등,
MRI 내에서 T1(기본)/T1Gd(조영제)/T2(수분 함량 높은 부위 강조)/FLAIR(CSF 신호 억제)로도 모달리티가 구분됨.

2. Few Shot Medical Image Segmentation with Cross Attention Transformer (MICCAI 2023)
https://arxiv.org/abs/2303.13867v1
Few Shot Medical Image Segmentation with Cross Attention Transformer
Medical image segmentation has made significant progress in recent years. Deep learning-based methods are recognized as data-hungry techniques, requiring large amounts of data with manual annotations. However, manual annotation is expensive in the field of
arxiv.org
Abstract.
- 딥러닝 기반 Medical Image Segmentation은 높은 성능을 보이지만 대량의 수작업 라벨링 데이터를 필요로 하나, 전문적인 지식이 필요한 고비용 작업이기에 대규모 데이터 확보에 한계가 있음.
ð 새로운 질환이나 organ에 대한 의료영상데이터가 적은 경우 일반화하기 어렵다는 단점
- Few-shot learning을 통해 소수의 예시만으로도 새로운 병변을 학습하고 분할할 수 있도록 하고자 함.
- Cross Masked Attention Transformer 기반의 새로운 프레임워크인 CAT-Net 제시
ð Support image와 Query image의 상관관계를 학습하여 support prototype과 query feature 향상시킴
ð Iterative refinement 하도록 구조 설계
- 데이터가 적은 상황에서 뛰어난 일반화 성능을 보임.
‣ Support set과 Query set을 입력한 후 Cross-Attention module을 통해 특징을 서로 비교하며, 유사한 공간 패턴을 강조함.
‣ Transformer 기반 구조로 global context를 효율적으로 포착하고, Meta-learning 전략을 통해 다양한 질환 도메인으로 확장


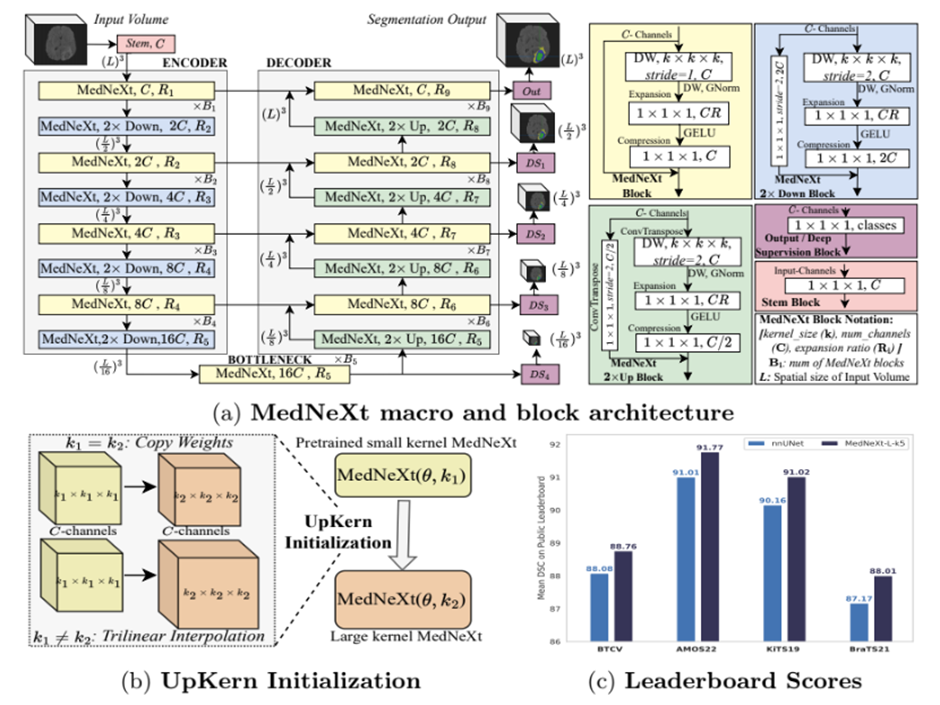
3. MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
https://arxiv.org/abs/2303.09975
MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
There has been exploding interest in embracing Transformer-based architectures for medical image segmentation. However, the lack of large-scale annotated medical datasets make achieving performances equivalent to those in natural images challenging. Convol
arxiv.org
Abstract.
- 의료영상분야에서는 Annotated data set의 부족으로 인해 Natural images 분야에서 Transformer가 달성한 수준의 성능을 내기 어려움
- ConvNets(Convolutional Networks)은 상대적으로 적은 데이터로도 높은 성능을 안정적으로 학습할 수 있음.
- 데이터가 제한된 의료환경의 특수한 문제에 최적화된 합성곱기반 구조 설계
ð MedNeXt
1) ConvNeXt 기반 3D 인코더 – 디코더 네트워크 설계
2) Residual ConvNeXt 업샘플링 및 다운샘플링 블록
3) 소형 커널 네트워크 업샘플링 -> 커널 크기 점진적 확대
4) Depth, Width 유연하게 조정하여 작은 GPU에서도 훈련가능
'Paper_Review' 카테고리의 다른 글
| [jekim] Paper review (0) | 2025.11.03 |
|---|---|
| [jyhan] paper review (0) | 2025.11.01 |
| [jslim] paper review (0) | 2025.09.28 |
| [sbpark] paper review(9/20) (0) | 2025.09.20 |
| [jslim] Paper Review (0) | 2025.09.20 |