1. DDPM - Denoising Diffusion Probablistic Models (2020)
https://arxiv.org/abs/2006.11239
Denoising Diffusion Probabilistic Models
We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound
arxiv.org
Introduction.
- Diffusion model은 finite time 이후 데이터와 일치하는 샘플을 생성하도록 variational inference로 학습되는 Markov chain
- Diffusion은 sampling의 반대 방향으로 데이터에 점진적으로 노이즈를 추가함.
- 본 연구에서는 DM이 높은 품질의 샘플을 생성할 수 있음을 보이고자 함.
Diffusion models and denoising autoencoders.
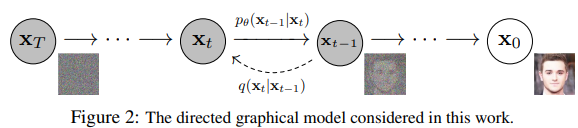
1) Forward process
- 원본 데이터 X0에 점진적으로 노이즈 추가. (스텝이 진행될수록 증가).
- Closed form으로 X0 + noise를 직접 샘플링할 수 있음.
2) Reverse process: DM은 노이즈 ε을 예측함.
- DM은 이미지를 복원하지 않고 노이즈를 예측하는데, 이 때 Parameterization 사용.
- Reverse process에서 ε 예측은 denoising score matching과 같으며,
sampling 과정은 annealed Langevin dynamics와 동일한 형태로 나타난다.
3) Data scaling, reverse process decoder
- model이 연속출력을 만들고 pixel 값 0~255 구간에 맞추어 decoding 하여 likelihood 계산
4) Simplified Objective
- Variational bound 대신에 MSE (노이즈 예측) 사용


Algorithm 1: Training
- 노이즈 ε를 예측하는 네트워크 εθ를 학습시키는 과정
- 데이터 X0를 샘플링한 후, Random하게 step t 선택하고, Gaussian noise 생성.
- Forward process로 step 3 수행함.
Algorithm 2: Sampling (이미지 생성)
- 에서 시작하여 모델이 학습한 역과정을 따라 점진적으로 노이즈를 제거하며 이미지 생성.
- t=T->1까지 반복하며 네트워크가 노이즈 예측
- 예측된 노이즈를 기반으로 μ 계산
Algorithm 3: Sending
- 데이터를 노이즈가 섞인 중간 표현들을 차례대로 보내어 점진적으로 정보량을 늘려나감.
Algorithm 4: Receiving
- step 3를 통해 선명한 형태의 X0을 복구함.
2. ViT - An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
https://arxiv.org/abs/2010.11929v2
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
Introduction.
- Transformer은 Pre-training(사전 학습) → Fine-tuning(미세 조정) 전략으로 높은 성능과 확장성을 보여왔음.
- 순수 Transformer로만 구성된 모델은 거의 없었으나, 이미지를 patch 단위로 쪼개고, patch를 token처럼 처리하면 NLP Transformer을 그대로 사용할 수 있음.

Method.
1) Vision Transformer (ViT)
- Image → patch → token 의 과정으로 transformer 입력을 만든다.
- ViT는 CNN과 다르게 Inductive biase가 거의 없음.
(CNN: 주변 Pixel -> 확장 / ViT: global -> patch 사이를 self-attention)
따라서, ViT는 충분한 Dataset을 요구한다. (충분하지 않을 경우 generalization 성능 떨어짐)
2) Fine-tuning and higher resolution
- Pre-training 보다 더 높은 해상도에서 Fine-tuning
- positional embedding을 2D interpolate하여 조정할 수 있음.
Experiments.
- Pre training datasets: ImageNet(1.3M), ImageNet-21k(14M), JFT-300M(300M)
- Model: ViT(Transformer), ResNet(CNN), Hybrid(CNN+Transformer)
| 작은 데이터 (ImageNet) | CNN (ResNet) | ViT는 inductive bias가 없어 overfitting하기 쉬움 |
| 중간 데이터 (ImageNet-21k) | 비슷함 | |
| 매우 큰 데이터 (JFT-300M) | ViT | self-attention으로 인해 정보 통합에 유리함 |
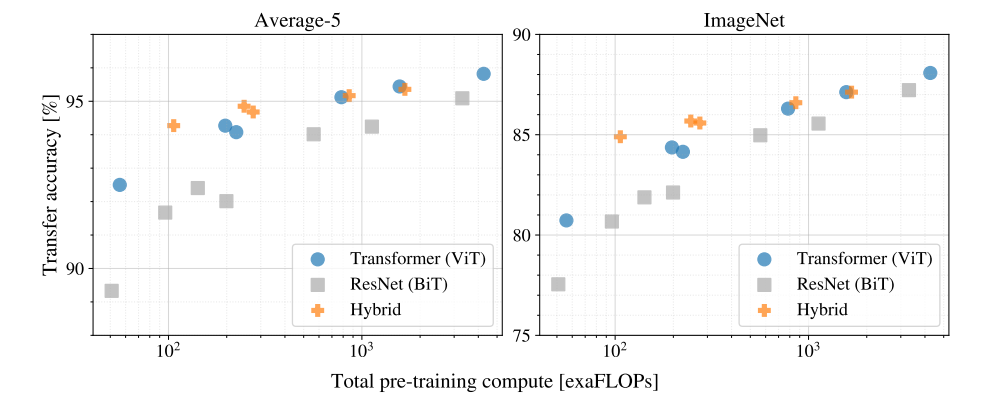
- ViT(Transformer)와 ResNet(CNN)을 비교했을 때, 같은 연산량일 때 ViT가 더 높은 성능을 보임.
- Hybrid(CNN+Transformer)와 ViT(Transformer)을 비교했을 때, 작은 모델일 때는 Hybrid가 약간 더 좋음. (초기에 CNN이 local feature 도움)
- Hybrid(CNN+Transformer)와 ViT(Transformer)을 비교했을 때, 큰 모델일 때는 차이가 거의 사라지며 ViT 단독으로도 충분함.
→ 충분한 데이터가 주어지면 ViT는 스스로 최적 표현을 학습하여 Inductive Bias가 필요없어짐.
3. AlexNet - ImageNet Classification with Deep Convolutional Neural Networks (2012)
https://papers.nips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
Introduction.
- CNN(Convolutional Neural Network)은 inductive bias를 가지며 대규모 이미지 데이터 학습에 적합하다.
- AlexNet은 대용량 GPU 연산, ReLU 비선형 활성화 함수, Data Augmentation, Regularization을 결합하여 대규모 CNN 학습을 현실화하였다.
Architecture.

- input: 224 x 224x 3 RGB image
- layers: 8 learned layers
- Parameters: 60M
- Neurons: 650,000
- Output: 1000-way softmax for 1000 classes

- 5개의 Convolutional layers & 3개의 Fully Connected Layers
| Conv1 | 11×11, stride 4, 96 filters → ReLU → LRN → Max Pool |
| Conv2 | 5×5, 256 filters → ReLU → LRN → Max Pool |
| Conv3 | 3×3, 384 filters (convolution+ReLU) |
| Conv4 | 3×3, 384 filters (convolution+ReLU) |
| Conv5 | 3×3, 256 filters → Max Pool |
| FC6 | 4096 → ReLU → Dropout |
| FC7 | 4096 → ReLU → Dropout |
| FC8 | 1000 → Softmax |
- ReLU가 모든 합성곱 및 연결층에 적용된다.

- GPU 1은 주파수/방향에 민감하게, GPU 2는 색상에 민감하게
Reducing Overfitting.
- AlexNet은 60M parameters로 과적합 위험이 매우 크다.
1) Data Augmentation
· Random cropping + horizontal flip: 위치/구도 변화에 대한 robustness 확보
· RGB PCA color : 조명/색감 변화에 대한 invariance 확보
-> 같은 사진을 회전/뒤집음/바꾸어서 120만장의 데이터를 수십억 장처럼 활용할 수 있음. (데이터 증강)
2) Drop out (at FC Layer)
· 학습 시 무작위로 뉴런의 50%을 비활성화, 뉴런 간 co-adaption 방지
-> 특정 패턴만 학습하지 않고 일반적으로 배울 수 있게 됨.
∴ 충분히 큰 데이터와 CNN, GPU, 적절한 학습 기법을 결합하면 사람이 특징을 설계할 필요 없이 모델이 데이터로부터 특징을 학습하는 end-to-end 학습 방식이 효율적임.
4. ResNet - Deep Residual Learning for Image Recognition (2015)
https://arxiv.org/abs/1512.03385
Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with
arxiv.org
Introduction.
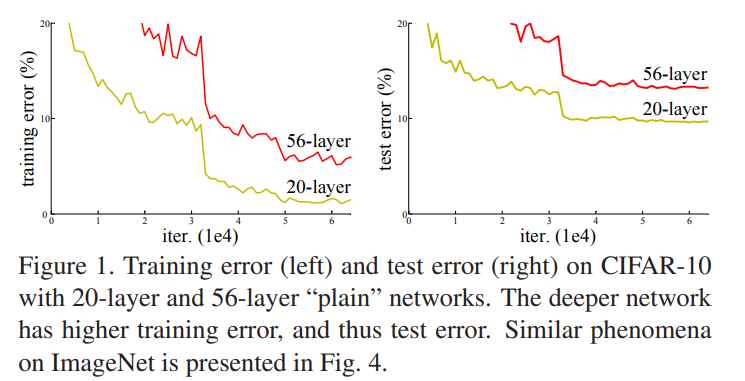
- Deep Convolutional Neural Network (VGG, GoogLeNet)는 classfication 등에서 뛰어난 성과를 냈으나, depth가 늘어날수록 학습이 어려워지며 Figure 1. 결과처럼 training error가 발생하는 문제가 발생함. (네트워크가 Identity Mapping 을 표현하기 어려워 발생하는 문제.)
- 본 연구는 이러한 문제를 해결하기 위해 Residual Learning을 제시하여 deep network에서도 효율적인 학습이 가능한 구조를 모색하고자 하였음.
Deep Residual Learning.
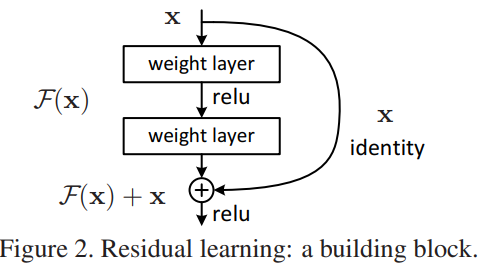
- 복잡한 함수를 직접 근사하는 대신에, 입력 대비 오차를 줄이는 방향으로 학습을 단순화시킴.
=> 기존의 네트워크가 학습하려는 mapping H(x)를 직접 학습하는 대신,
residual F(x) = H(x) - x 학습, output y = F(x) + x
- Network Archituecture

[Plain net, ResNet
- layer에서 생산되는 map 크기 같으면, layer의 filter 개수 동일 & feature map 1/2 이면, filter 개수는 2배로 늘림]
① Plain network: 깊어질수록 훈련 오차 증가
② Residual network: 깊어질수록 훈련오차, 검증오차 모두 감소

Experiments.
1) ImageNet Classification
Dataset: 1.28M training images, 50k validation images, 1000 classes.
Architecture: 18, 34, 50, 101, 152-layer ResNet 실험 수행
50층 이상에서는 bottleneck 구조(1×1 → 3×3 → 1×1) 사용으로 파라미터 효율 향상.
결과
동일 깊이의 plain network 대비, Residual Network는 훈련 오차와 검증 오차 모두 낮음.
-> 34-layer plain network는 top-5 error 10.02%, ResNet-34는 7.40%깊이를 152층까지 늘려도 degradation 현상이 발생하지 않음.
- 연산량: ResNet-152 (11.3 GFLOPs) < VGG-19 (19.6 GFLOPs) → 더 깊지만 효율적임.
2) CIFAR-10 Classification
- Dataset: 50k train / 10k test images, 10 classes.
- 목적: state-of-the-art 성능보다는 “깊이에 따른 학습 안정성” 분석에 초점.
- 구조:
- 각 stage는 3×3 conv 2층씩 구성, 총 6n+2개의 conv layer.
- ResNet에서는 각 두 층 사이에 identity shortcut 연결.
- 결과:
- plain network는 56층 이상에서 training error 급증,
- ResNet은 110층까지 안정적으로 수렴, error 지속 감소.
- ResNet-110: 파라미터 수 1.7M, test error 6.43%
- 추가 분석:
- residual layer의 output 분산(std)이 plain보다 작음 → “필요한 변화만 미세 조정”하는 구조임을 시사.
- 즉, residual block은 입력 특징을 유지하면서 필요한 부분만 보정하는 학습 패턴을 보임.
'Paper_Review' 카테고리의 다른 글
| [sbpark] paper review CCTV 영상을 활용한 강우량 산정기법 개발 (0) | 2026.02.01 |
|---|---|
| [sbpark] paper review (0) | 2025.12.29 |
| [jekim] Paper review (1) | 2025.11.08 |
| [jyhan] paper review (0) | 2025.11.08 |
| [jekim] Paper review (0) | 2025.11.03 |