1. LDM - High-Resolution Image Synthesis with Latent Diffusion Models (2022)
https://arxiv.org/pdf/2112.10752
Abstract.
- Denoising autoencoders(노이즈가 섞인 input에서 원래의 깨끗한 데이터를 복원하도록 학습된 신경망) 구조를 사용한 DM(Diffusion model) & LDM(Latent Diffusion model)은 Text-to-image(텍스트 입력 -> 이미지 변환), Inpainting(이미지 제거/복원/확장), Super-resolution(저해상도->고해상도)에 활용된다.
- DM은 이미지의 픽셀 공간에서 노이즈를 제거하며 이미지를 생성하지만, LDM은 Autoencoder의 latent space에서 확산을 수행하여 빠르고 저렴한 비용으로 사용가능하다.
Introduction.
- DM은 likelihood-based models (mode-covering) 으로, imperceptible details에도 capacity를 과도하게 사용한다는 문제 등으로 인해 Training과 Inference 모두 비용이 크다.
- DM의 접근성을 높이고 Resource consumption을 줄이는 것, 즉 성능을 해치지 않으면서도 학습과 샘플링의 computational complexity를 줄이는 것이 필요하다.
- Departure to Latent space: DM은 아래 그림의 Perceptual compression, Semantic compression의 과정을 거침.
Perceptual compression에서는 high frequency의 세부정보를 제거하며, Semantic compression에서는 data의 의미론적/개념적 구성을 학습
Perceptual compression에서는 형태와 윤곽을 남기는 작업이 진행이 되는데, 이 작업은 계산량이 많이 들기 때문에,
LDM에서는 Semantic compression 단계의 latent space에서 diffusion이 일어난다.
- LDM: Autoencoder을 학습하여 low-dimensional 공간을 확보하고, 이 공간을 활용해 diffusion model을 학습한다. LDM에서는 Autoencoder 단계를 한 번만 학습해도 다양한 image-to-image, text-to-image의 작업 탐색이 가능하다.

Related work.
- Generative Models for Image Synthesis (Generative Adversarial Networks, GAN)
: high resolution images, good perceptual quality이지만 최적화 어려움
- Likelihood-based methods
: 최적화 안정적임
- Variational autoencoders(VAE) & flow-based models
: high resolution image를 효율적으로 합성할 수 있으나 GAN 만큼의 quality는 x
- Diffusion Probabilistic Models(DM)
: UNet 기반의 neural backbone 으로 높은 생성 기능을 가지나, 느린 추론 속도와 높은 학습 비용으로 인한 단점 있음
: LDM - latent space에서 동작하므로 학습 비용이 낮으며, quality의 손상없이 추론 속도 향상됨
Method.
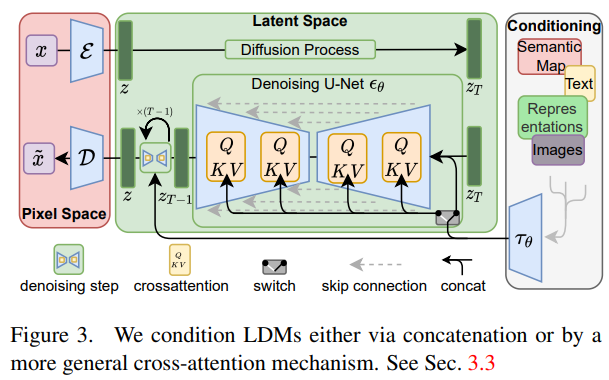
- Perceptual Image Compression
Perceptual loss + patch 기반 adversarial objective로 학습된 autoencoder 사용. -> Bluriness 방지
image x → encoder e → z → decoder d → x bar
- Latent Diffusion Models
1) Diffusion model: 정규분포된 변수를 점진적으로 denoising하여 데이터 분포 p(x) 학습 /
L_DM=Ex,ϵ∼N(0,1),t∥ϵ−ϵθ(xt,t)∥22
각 Denoiser ϵθ(xt,t), t=1…T는 입력 Xt의 디노이즈된 버전을 예측하도록 학습된다.
2) Generative modeling of Latent Representations: Encoder e와 Decoder d로 구성된 perceptual compression model을 통해, high frequency의 details가 제거된 low dimensional의 latent space 에 접근할 수 있다.
latent space는 high-dimensional pixel space와 비교했을 때 데이터의 중요한 요소에 집중하기 쉽고, 차원이 낮아 계산적으로 효율성이 뛰어나다.
- Conditioning Mechanisms
Conditional denoising autoencoder ϵθ(zt,t,y)를 사용하여 구현할 수 있으며, text/semantic map/images 등 조건 입력 y를 통해 생성 과정을 제어하는 것이 가능해진다.
UNet backbone에 cross-attention mechanism을 추가하여 DM을 유연한 조건부 이미지 생성 모델로 확장할 수 있다.
다양한 형태의 조건 입력 y를 전처리하기 위해 τθ(domain specific encoder) 를 도입한다.
Experiments.
1) On perceptual compression tradeoffs
- downsampling factors f ∈ {1, 2, 4, 8, 16, 32} 일 때,
ⅰ) small downsampling factors (ex. LDM - {1,2}): 학습 속도가 느려짐 (Pixel 공간에서의 diffusion과 차이 거의 x)
ⅱ) big downsampling factors: quality가 저하되는 문제가 생김.
→ LDM {4~16}에서 efficiency와 faithful results를 확인할 수 있었다. LDM - 4, LDM - 8에서 가장 최적의 조건을 제공한다.

2) Image generation with latent diffusion
LDM을 CelebA-HQ, FFHQ, LSUN Churches, Bedrooms에서 unconditional models 256x256 생성으로 학습하였을 때 pixel based diffusion보다 높은 efficiency, 동등하거나 더 높은 quality를 보였음.
3) Conditional latent diffusion
① Transformer encoders for LDMs (text-to-image)
텍스트 조건의 LDM 학습 -> 텍스트를 BERT tokenizer + transformer encoder → cross-attention으로 UNet에 주입
learning a language representation + visual synthesis
② Convolutional Sampling beyond 256^2 (image-to-image)
4) Super-Resolution with latent diffusion
- LDM은 low resolution image를 입력에 직접 결합하여 조건으로 주는 방식을 통해 super-resolution 모델로 학습될 수 있음.
5) Inpainting with Latent diffusion
- Inpainting은 이미지의 일부가 손상되었거나 바꾸고 싶은 경우, 마스킹된 영역을 새로운 내용으로 채우는 작업
- Pixel 기반 대비 최소 2.7배 빠른 속도, 1.6배 향상된 FID

Limitations & Societal impact.
- 전반적으로 뛰어난 성능을 보이나 LDM은 Latent space의 expressiveness에 의존하기 때문에, 1단계 모델의 품질에 의해 결과가 크게 좌우된다.
- Autoencoder가 inductive biase와 reconstruction artifacts를 유발할 수 있다.
- pixel 기반 DM보다 계산 비용이 줄었음에도 순차적인 Denoising 단계가 필요하므로, GAN같은 단일 생성 모델보다 샘플링 속도가 느리다.
Conclusion.
- LDM은 계산 요구량을 크게 줄이면서도 flexibility와 generative quality의 측면에서 저하되지 않 High-resoltion diffusion model을 실용적인 수준으로 만든다.
2. ControlNet - Adding Conditional Control to Text-to-Image Diffusion Models (2023)
https://arxiv.org/pdf/2302.0554
Abstract.
- ControlNet 신경망 구조는 사전학습된 text-to-image diffusion models을 제어하여 추가적인 encoding 조건을 지원한다.
- 핵심설계는, 사전학습된 large diffusion models의 강력한 능력을 보존하며,
소규모의 학습가능한 가중치를 추가하여 제어가 가능하도록 하는 것이다.
- Knowledge of large diffusion model을 trainable copy와 locked copy로 복제
→ Trainable copy: 네트워크 능력 보존
→ Locked copy: 과제 특화 조건 학습
- Zero convolution: layer를 0으로 초기화하여 trainable copy를 locked copy에 고정 (training이 original model을 망가뜨리지 않도록)
- ControNet은 Image generation을 제어하여 edge-to-image, depth-to-image, normal-to-image를 가능하게 함.
Introduction.
- Text-to-image diffusion model로, 우리는 text prompt를 입력하여 image를 생성할 수 있으나,
spatial composition과 layout, pose, shape, form을 정확히 표현하는 것은 text prompt만으로는 어려울 수 있다.
- 사용자가 원하는 이미지 구성을 위해 추가 이미지를 제공하도록 하는 것은 이미지 생성 과정의 조건 중 하나가 된다.
- text-to-image translation models는 conditioning images -> target images 로의 mapping 학습
- Large text-to-image diffusion model을 end-to-end way 신경망 구조인 ControlNet으로 적용하고자 함.
Related work.
- Fine tuning Neural Networks
· 신경망을 파인튜닝하는 방법: 추가적인 학습 데이터를 사용하여 계속하여 학습시킴 but overfitting, mode collapse, catastrophic forgetting 문제 발생 가능
=> HyperNetwork: 작은 네트워크가 큰 모델의 가중치 조정. 스타일 변경 가능하나 구조복잡, 제어에 제한
=> Adapters: 기존 네트워크에 module layer 삽입. parameter은 적으나 성능의 유지가 어려울 때가 있음
=> Additive Learning/Side-Tuning: 원본에 추가 신경망 학습. 원본 보호되나, 외부 혼합이 불안정할 수 있음
=> LoRA: parameter 변경을 low-rank 형태로 제한. 망각 방지, 효율적이나 구조 변화가 필요할 수 있음
=> Zero-initialized layers: 새로 추가되는 레이어를 처음에 영향 0으로 시작함. 원본 능력을 보호함.
- Image diffusion
DM: Image를 noise->image 또는 image->noise 로 변환시키는 likelihood-based model
| LDM (Latent Diffusion Model) | 고해상도 이미지를 latent 공간에서 처리 → 연산비용 감소 |
| Stable Diffusion | large-scale implementation of latent diffusion |
| GLIDE / Disco Diffusion | 텍스트 guidance 강화 모델 |
| Imagen | latent 공간 없이 직접 픽셀에서 diffusion |
- Image-to-Image translation: conditional image -> target image로 변환
Method.
1) ControlNet

- 공간적으로 국소화된 task-specific image diffusion models. (large pretained text-to-image dffusion)
- Network block = 하나의 신경망 단위를 구성하기 위해 묶이는 신경망 layer의 집합
- 사전학습된 neural block에 ControlNet을 추가하기 위해,
원본 block의 parameter lock / 원본 block 복제(trainable copy)하여 parameter c 부여

- 첫번째 학습 단계에서 zero convolution layers는 0으로 초기화되어 있기 때문에, yc = y가 됨.
따라서, 학습 시작시 harmful noise가 영향을 미칠 수 없게 됨.
2) ControlNet for Text-to-Image Diffusion
- ControlNet이 large pretrained diffusion model에 'conditional control'을 추가하는 방법
: ControlNet 구조는 U-Net의 Encoder 단계에 적용됨.

3) Training
input image = z0
noise 추가 = zt (t는 횟수)
text prompt = ct (t는 시간단계)
L(Entire diffusion model의 학습 목표 함수 =
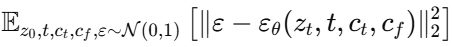
- 학습과정에서 text prompt ct의 50%를 empty strings로 대체하여 ControlNet이 입력된 조건의 이미지의 의미를 직접 인식할 수 있는 능력을 증가시켜준다.
- 학습과정에서 zero convolution은 network에 noise를 추가하지 않으므로, 모델은 high-resolution image를 예측할 수 있어야 한다.

4) Inference
| CFG Resolution Weighting | 해상도에 따라 ControlNet 영향 비율을 조절 → 과도 제어 or 제어 부족 방지 |
| Multiple ControlNets | ControlNet은 여러 개를 동시에 더해도 됨 → 조건 합성 자연스럽게 가능 |
Experiments.

- ControlNet-lite: zero convolution을 Gaussian weights로 초기화된 일반 convolution layer로 대체, 각 블록의 trainable copy를 single convolutional layer로 대체
- 실제 사용자 행동에서 나타날 수 있는 4가지 프롬프트 설정
1) no prompt
2) insufficient prompt: conditioning image의 객체를 충분히 설명하지 못함
3) conflicting prompt: conditioning image의 의미를 바꿈
4) perfect prompt: 필요한 내용의 의미를 정확히 설명

Conclusion.
- ControlNet은 다양한 조건의 입력에서도 선명하고 안정적인 출력을 생성하며,
데이터가 많아질수록 능력이 확장된다. 프롬프트 없이도 이미지 내의 의미 구조를 해석 가능하여 Stable diffusion을 control한다.
3. MAISI - Medical AI for Synthetic Imaging
https://arxiv.org/pdf/2409.11169
Abstract.
- 의료 영상 분야에서 foundation model이 발전하며, 데이터 부족 문제를 해결하기 위해 synthetic data generation의 중요성이 커지고 있으나, 여러 organ을 동시에 포괄하며 전신 수준의 영상을 합성하는 것은 어려운 과제임.
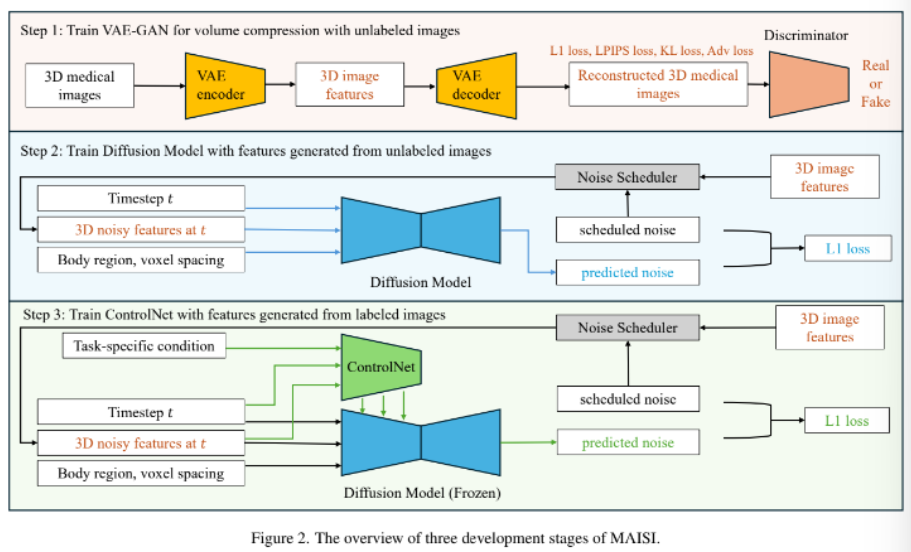
- MAISI: 전신 3D CT image를 다양한 해상도에서 합성할 수 있는 의료 AI model.
3D-VAE-GAN을 사용해 CT volume을 압축된 latent로 변환후 LDM을 이용해 Latent 공간에서 새로운 CT volume 생성
+ ControlNet 방식의 보조 인코더를 통합해 해부학적 정확도를 강화함.
Introduction.
- 의료 기반 ML(Machine Learing) 모델을 만드는 과정의 구조적 문제점
1) Data scarcity: 특정 암이나 희귀질환에서는 충분한 학습 데이터 확보가 어려움
2) High human annotation costs: 세밀한 3D 주석은 전문지식을 요구하며 이에 대한 비용이 매우 큼
3) Privacy-concerns: 의료영상은 민감한 개인정보이므로 병원간 데이터 공유-대규모 수집이 제한됨
→ Generating synthetic data가 이러한 문제를 해결할 수 있는 전략이 될 수 있으나
1) High solution 3D volume generation이 많은 양의 data를 다루어야 함.
2) Fixed 된 output volume dimension과 voxel spacing은 해부학적 구조가 달라지는 실제 임상 환경과 맞지 않음.
3) 한 번 훈련된 모델은 대상의 데이터나 organ이 바뀌는 경우 일반화가 잘 되지 않음.
→ 이러한 문제를 해결하기 위해 MAISI 제안
Related work.
- Medical image synthesis는 현실적인 의료 영상을 합성하는 것을 목표로 활발히 진행되어 왔다.
1) GAN in medical image synthesis: GAN은 MRI/CT 합성, Modality 변환, anomaly 탐지 등의 의료 영상 작업에서 사용되어 왔으나, Unrealistic 하거나 less diverse 한 output의 한계가 존재한다.
2) DM in medical image synthesis: Diffusion model은 high-resolution image synthesis, 안정적인 합성, condition 하에서도 유연하게 작동한다는 점을 바탕으로 주목받고 있다.
Methodology.
- Step1: Volume compression Network(VAE-GAN)이 CT/MRI volume으로 구성된 dataset 학습
- Step2: LDM이 Step1. 에서 수집된 dataset의 CT volume을 이용해 학습(latent space에서 anatomical structure 생성)
- Step3: ControlNet이 MAISI 프레임워크에 통합되어 Step2. 에서 학습된 LDM에 추가 조건을 주어 다양한 작업 지원
1) Volume compression Network
- CT volume x ∈ RH×W×D(H=높이, W=너비, D=깊이)이 주어졌을 때,
인코더가 x를 downsampling 하여 z = E(x) ∈ Rh×w×d 를 생성한다.
2) Diffusion model
- Step1에서 얻은 latent representation z 위에서 diffusion 수행
- Body region (i_top, i_bottom) + voxel spacing s 를 조건 cp 로 사용
- 다양한 해부학적 범위와 출력 크기를 가진 CT volume 생성 가능
3) Additional conditioning mechanisms
- ControlNet을 통해 Segmentation 등 추가 조건 cf 주입
- LDM은 고정(frozen), ControlNet만 학습하여 task-specific 합성 가능
Experiments.
1) Datasets and Implementatioin Details
| Step 1: Volume Compression Network (VAE-GAN) | CT 37,243 train / 1,963 val + MRI 17,887 train / 940 val | 고해상도 CT/MRI → latent 공간 압축 | 다양한 장기(머리-목 / 흉부 / 복부 / 뇌) 포함하여 일반화 가능 latent 확보 |
| Step 2: Latent Diffusion Model (LDM) | CT 10,277 volume | latent 공간에서 해부학 구조 생성 | 입력 조건: body region + voxel spacing → 유연한 해상도 & 범위 생성 가능 |
| Step 3: ControlNet | Step2 데이터 subset + Segmentation |
생성 과정에 추가 조건 제어 | segmentation-based synthesis, tumor inpainting 지원 가능 |
2) Evaluation of MAISI VAE
- MAISI VAE model의 foundation model로서의 능력을 보여주기 위해, out-of-distribution datasets(학습과정에서 보지 않은)ㅇ에서 테스트를 진행한다.
- Table 1의 결과를 통해 model의 cost-effectiveness와 practicality 확

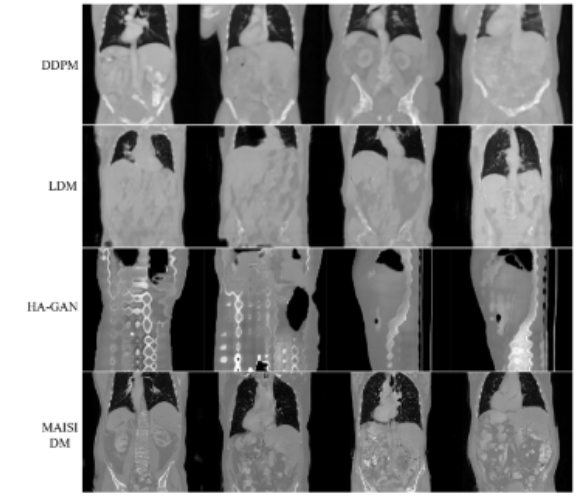
3) Evaluation of MAISI Diffusion Model
- 기존의 방법들(DDPM, LDM, HA-GAN)을 포함한 방법들과 비교하여 수행
- Fidelity(정확도)

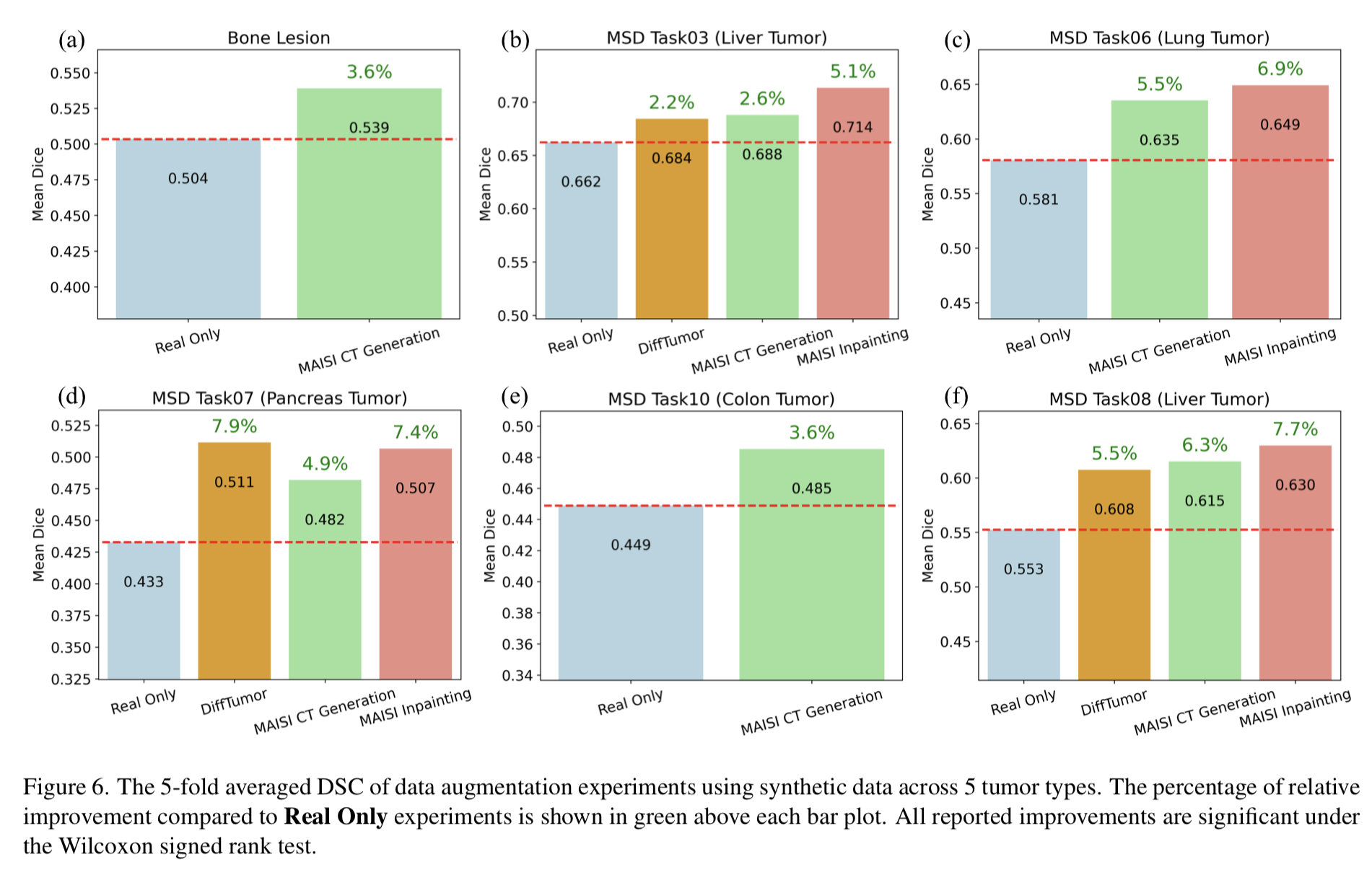
4) Data Augmentation in Downstream Tasks
- Auto3DSeg(의료 영상 Seg. model 학습을 위한 solution)을 사용하여 MSD Task 03(간 종양), Task 06(폐 종양), Task07 (췌장 종양), Task 10(대장 종양), bone lesion dataset에 대해 모델 학습하였음.
① MAISI CT Generation으로 표기된 task는 5가지 종양을 포함한 127개의 해부학적 구조 mask를 기반으로 하는 조건부 생성
→ 각 종양에 해당하는 환자의 종양 mask를 증강시켜 합성 데이터를 생성할 수 있도록 함.
② MAISI Inpainting은 간/췌장/폐 종양을 동시에 지원하는 종양 인페인팅 모델 학습
4. MAE(Masked AutoEncoder) - Masked Autoencoders Are Scalable Vision Learners
https://arxiv.org/abs/2111.06377
Introduction.
Masked Autoencoder (MAE) 라는 새로운 자기지도학습(Self-Supervised Learning) 방법을 제안한다.
핵심 전략은 이미지 패치의 대규모 랜덤 마스킹(약 75%) 후, 보이는 패치만으로 인코딩하고,
가벼운 디코더로 전체 이미지를 복원하는 것

• 비대칭 Encoder–Decoder 구조: Encoder는 보이는 패치만, Decoder는 복원 전담
• 연산량 3~4배 절감, 더 큰 ViT 모델 학습 가능
• ImageNet-1K만 사용해 ViT-Huge 87.8% 달성 → 기존 self-supervised 방법보다 우월
• 다양한 downstream task에서 supervised pre-training 보다 성능 우수
Method.
1) Patch Tokenization
• 이미지를 16×16 patch 단위로 나눔 (ViT 구조 그대로)
2) Random Masking (Uniform Sampling)
• 패치 중 75%를 랜덤하게 제거
• 남은 25% 패치만 Encoder에 입력
• Block-wise masking보다 random masking 성능이 더 높음

3) Asymmetric Encoder - Decoder
Encoder: 보이는 patch만 입력하여 효율을 상승시킴
Decoder: Encoder token + mask token를 다시 원래 순서대로 복원함.
Experiments.
- Downstream Fine-tuning 결과
Model Training Data Fine-tuned Acc (ImageNet-1K)
| ViT-L Supervised | ImageNet-1K | ~82% |
| ViT-L + MAE Pre-training | ImageNet-1K | ~85-86% |
| ViT-H + MAE Pre-training | ImageNet-1K | 87.8% (SOTA at 당시) |
=> Label 없이 pre-training 만으로 supervised보다 representation 학습이 뛰어남
'Paper_Review' 카테고리의 다른 글
| [sbpark] paper review (0) | 2025.12.29 |
|---|---|
| [jekim] paper review (0) | 2025.11.15 |
| [jyhan] paper review (0) | 2025.11.08 |
| [jekim] Paper review (0) | 2025.11.03 |
| [jyhan] paper review (0) | 2025.11.01 |