μ² Tokenizer: Differentiable Multi-Scale Multi-Modal Tokenizer for Radiology Report Generation
MICCAI 2025
Abstract
- Background: Automated Radiology Report Generation (RRG)은 진단 효율성을 높이는 핵심 기술이나, 고용량 3D CT data 처리 시 발생하는 Information Loss와 Report Evaluation의 객관성 부재라는 난제 존재.
- Proposal: Multi-scale Multimodal LLM인 μ²LLM을 제안함. 핵심 모듈인 μ² Tokenizer를 통해 Differentiable한 방식으로 Visual features를 효율적으로 압축하고 Text Query와 정렬함.
- Method: GREEN-RedLlama Score를 기반으로 한 DPO(Direct Preference Optimization)를 적용하여 모델의 Clinical Accuracy를 전문가 수준으로 보정함.
- Result: 4개의 대규모 Dataset 실험에서 기존 SOTA Model 대비 우수한 성능을 입증하고, 5-stage Prompt Engineering을 통해 고품질의 Explainable Training Data를 구축함.
1. Introduction
- Context: CT 검사량 급증과 Radiologist 부족 현상 심화로 인해, 정확하고 신속한 Radiology Report 작성을 보조할 Automated tool의 필요성 대두.
- Limitations:
- 기존 LLaVA 기반 모델들은 Fixed Dimensions로 Resizing하여 미세 병변이나 장기 경계의 Anatomical Details를 손실시킴.
- High-resolution 원본 사용 시 Computational Cost가 과다하여 Resource Constraint 발생.
- Metrics: BLEU, ROUGE 등 기존 NLP Metrics는 단순 Lexical Similarity에만 집중하여, Clinical Salience를 평가하지 못함.
- Solution: 3D CT의 Spatial/Structural Information을 보존하면서도 Efficiency를 극대화하는 μ² Tokenizer와, Medical Fact를 평가하는 GREEN Score 기반 학습 도입.
2.1 Overview of μ²LLM

제안하는 μ²LLM은 3D CT 영상과 텍스트 쿼리를 입력받아 판독문을 생성하는 End-to-End 프레임워크임.
- Framework Composition:
- Visual Encoder: 3D CT Volume의 고차원 특징을 추출하기 위해 Pre-trained 3D Vision Transformer (예: ViT3D)를 백본으로 사용함.
- LLM: 추출된 시각 정보와 텍스트 질문을 바탕으로 최종 리포트를 생성하는 Decoder 역할 (Llama-3.2-1B 사용).
- Bridge: 이 둘 사이를 연결하는 핵심 모듈이 바로 μ² Tokenizer이며, 고해상도 3D 특징을 효율적인 토큰으로 압축 및 변환하여 LLM에 전달함.
2.2 μ² Tokenizer
기존 LinVT 구조를 기반으로 Linearity 원칙을 유지하되, 3D Medical Imaging 특성에 맞춰 3가지 핵심 요소를 개선함.
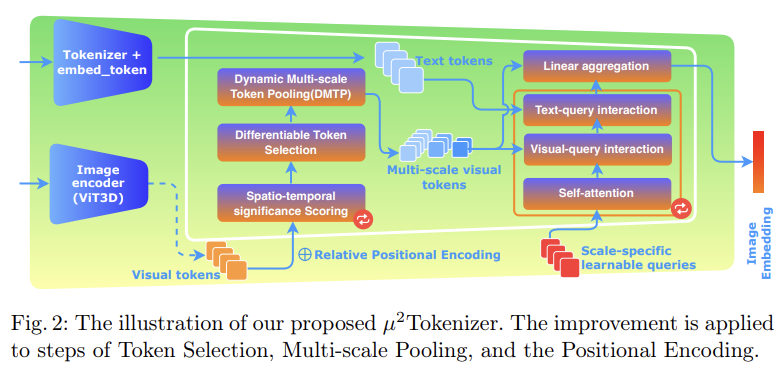
(1) Relative Positional Encoding(RPE)
- Concept: Absolute Positional Embedding 대신 Token 간의 Relative Distance를 학습하여 Structural Relationship을 파악함.
- Formula: Self-Attention 계산 시 Distance Function Pr 추가.

- Effect: Organ이나 Lesion의 위치가 환자마다 달라지더라도(Translation), Local Relationship과 Structural Context를 강건하게 유지함.
(2) Differentiable Token Selection(DTS)
- Concept: 기존 Hard Top-k 방식(Non-differentiable, Information Loss)을 대체하여, 모든 Token의 Weighted Sum을 계산하는 Soft Selection 도입.
- Formula:
- k개의 관점(r)에 대해 각 Token의 Importance Score(α) 산출
- Importance에 따라 모든 Token을 섞어서(Weighted Sum) Representative Token 생성.

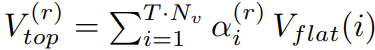
- Effect: Information Loss를 방지하고 과정이 Fully Differentiable해짐에 따라, Backpropagation 시 모든 Token에 대한 Gradient Flow 전달 가능.
(3) Dynamic Multi-scale Pooling(DMTP)
- Concept: Fixed Pooling 대신, Input Data Distribution에 따라 다양한 Kernel Size의 Importance를 스스로 조절하는 Dynamic Pooling 수행.
- Formula:
- Kernel Size s ∈ [1, 2, 4]로 각각 Average Pooling(y_s) 수행.
- MLP g(·)를 통해 각 Scale의 Weight(W_s) 산출.
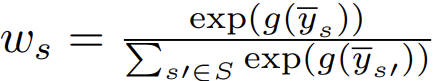
- Weight가 반영된 결과들을 Concatenation.
- Effect: 미세한 병변(Small Scale)과 전체적인 장기 구조(Large Scale) 정보를 상황에 맞게 유동적으로 Integrate함.
2.3 Direct Preference Optimization with GREEN-Score

- GREEN Score: LLM을 Judge로 활용하여 생성된 Report의 Clinical Significant Error 유무를 정량적(0~1점)으로 평가하는 Metric.
- DPO: SFT(Supervised Fine-Tuning)된 모델을 GREEN Score가 높은 방향으로 Align함.
- Formula: 전문가가 선호하는 답변(yw)의 Probability는 높이고, 비선호 답변(yl)은 낮춤.

- Effect: 단순 Text Generation을 넘어, 의학적으로 정확하고 신뢰할 수 있는 표현을 사용하도록 모델을 Optimization함.
2.4 Prompt Engineering
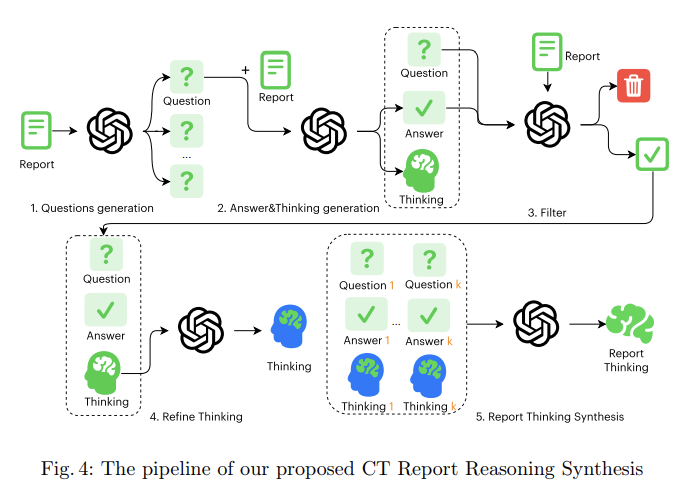
고품질의 Reasoning-rich Dataset 구축을 위해 단일 LLM에게 5-stage Role을 순차 부여함.
(1) Question Generation
- Report 전체를 분석하여 Lesion Attributes, Anatomical Localisation, Diagnostic Certainty, Follow-up 등을 포괄하는 다양한 Question List를 자동 생성함.
(2) Answer & Thinking Generation
- 단순 Answer 도출 전, Report 내 근거 구절 인용 및 Medical Prior Knowledge를 활용한 Thinking Process를 먼저 서술하도록 유도함 (Think step-by-step 기법 적용).
- The resulting tuples—question, answer, and raw reasoning
(3) Filter
- Automatic Quality Gate를 통과시켜 Data Refinement 수행.
- Factual Consistency 검증.
- Non-English Text 및 Vacuous Thinking 제거.
- Pathophysiologic Contradiction(예: "Pneumothorax가 처음 발견되었는데 Improved됨")이 포함된 Error Data 제거.
(4) Refine Thinking
- 장황한 Thinking Text를 Evidence-linked Paragraph로 압축함.
- Redundancy 제거 및 Clinical Uncertainty를 반영한 Probabilistic qualifiers(예: likely, suggestive of)를 삽입하여 Professionalism 확보.
(5) Report Thinking Synthesis
- 생성된 QA 및 Thinking Trace들을 Anatomical Order로 재배열함.
- Findings Rationale, Impression Rationale 등으로 Section을 구조화하여 완결된 Narrative Data 구축.
3. Experiments
(1) Datasets
- Composition: AMOS-MM(약 2천 건), CT-Rate(약 5만 건, 다양한 Slice/Resolution), Abdomen Atlas 3.0(약 9천 건) 등 Large-scale Dataset 활용.
- Augmentation: GPT-4o mini를 활용하여 기존 Report를 Rewriting하거나 QA Pair를 생성하여 Training Data의 Richness를 더함.
(2) Implementation & Baselines
- Setup: 3D ViT (M3D-CLIP 기반 Image Encoder) + Llama-3.2-1B-Instruct (LLM) + μ² Tokenizer.
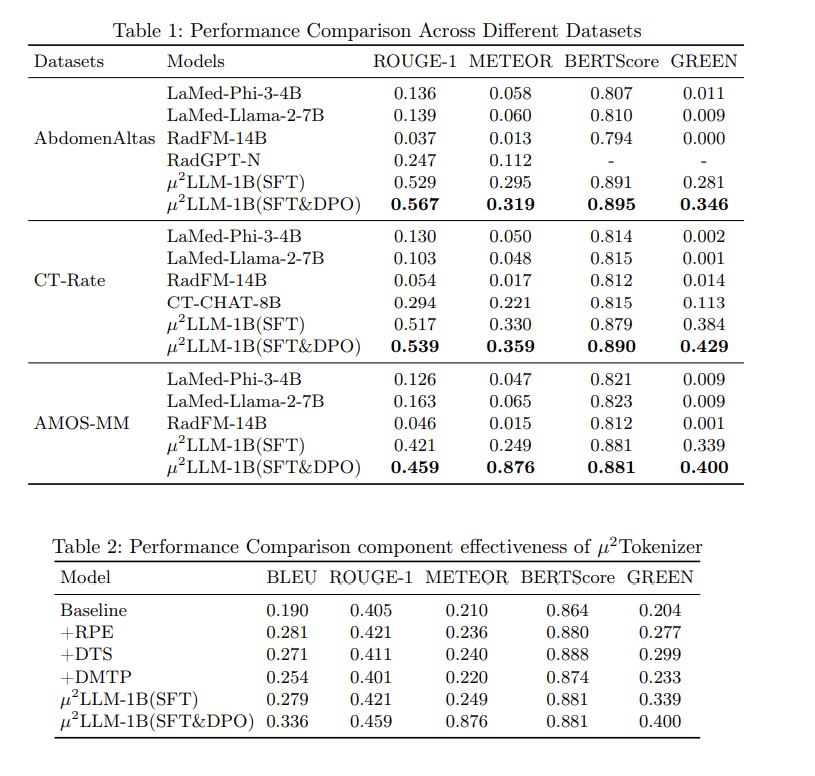
- Baselines: LaMed-Phi-3-4B, RadFM-14B, CT-CHAT-8B 등 Parameter 수가 본 모델(1B)보다 훨씬 큰 Model들과 Comparative Evaluation 수행.
(3) Results Analysis
- Performance: 1B size의 μ²LLM이 7B~14B 규모의 Competitive Model 대비 대부분의 Metric에서 Superiority를 보임. 특히 CT-Rate Dataset에서 GREEN Score 0.384를 기록하며 CT-CHAT-8B(0.113)를 압도함.
- DPO Effect: SFT Only Model 대비 DPO 적용 시 GREEN Score가 약 20% 향상되어 Clinical Accuracy 개선 입증.
- Ablation Study: Component(RPE, DTS, DMTP) 중 DTS 적용 시 GREEN Score가 최대 0.2점 상승하여 Performance Contribution이 가장 높음을 확인.
'Paper_Review' 카테고리의 다른 글
| [jyyang] Paper review(PancariesNet, Proximal caries detection accuracy) (0) | 2026.02.10 |
|---|---|
| [sbpark] paper review CCTV 영상을 활용한 강우량 산정기법 개발 (0) | 2026.02.01 |
| [jekim] paper review (0) | 2025.11.15 |
| [jekim] Paper review (1) | 2025.11.08 |
| [jyhan] paper review (0) | 2025.11.08 |