1. LDM - High-Resolution Image Synthesis with Latent Diffusion Models (2022)
CVPR 2022 Open Access Repository
High-Resolution Image Synthesis With Latent Diffusion Models Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10684-10695 Abst
openaccess.thecvf.com
1. Abstract
- 확산 모델(DMs)은 이미지 합성에 있어 최고의 성능을 보였으나, 픽셀 공간(Pixel Space)에서 직접 작동하기 때문에 최적화에 수백 GPU 일이 소요되며, 순차적 추론으로 인해 계산 비용이 매우 비쌈을 지적함.
- 품질과 유연성을 유지하면서 제한된 컴퓨팅 자원으로 훈련하기 위해, DMs를 사전에 학습된 강력한 오토인코더의 잠재 공간(Latent Space)에서 작동시킬 것을 제안함.
- 이 잠재 공간에서의 훈련은 지각적으로 중요한 정보는 보존하면서 계산 복잡성을 크게 줄여 효율성을 달성함.
- UNet (신경망)구조에 교차 주의(Cross-Attention) 레이어를 도입하여, 텍스트, 시맨틱 맵 등 다양한 조건부 입력으로 생성 과정을 유연하게 제어할 수 있도록 함.
- LDM(잠재 확산 모델)은 픽셀 기반 DM 대비 계산 요구 사항을 크게 줄였으며 (최대 16배), 이미지 임페인팅, 클래스 조건부 합성 등 다양한 다운스트림 태스크에서 최고 성능(SOTA)을 달성함을 확인함.
2. Introduction
- 기존 DMs는 고해상도 이미지 합성이 가능하지만, 훈련에 엄청난 시간과 자원이 필요해 연구의 접근성을 저해하고 환경 발자국을 남긴다는 문제점.
- DMs의 비효율성 : DMs의 학습 과정에서 모델 용량의 대부분이 사람의 눈으로 구별하기 어려운 지각적으로 중요하지 않은 세부 사항(imperceptible details)을 모델링하는 데 소모됨을 분석함.
- 이러한 비효율적인 '지각적 정보' 모델링을 제거하기 위해, 이미지 합성을 두 단계로 분리하여 해결하는 전략을 제시함.
- 지각적 압축(Perceptual Compression) : 오토인코더를 사용하여 고차원 픽셀 데이터를 효율적인 저차원 잠재 공간으로 변환함.
- 의미론적/개념적 합성(Conceptual Synthesis) : 이 잠재 공간에서만 확산 모델(LDM)을 훈련시켜 이미지의 핵심 의미를 모델링함.
- - LDM 아키텍처는 계산 효율성을 높여 다양한 이미지 대 이미지 변환 작업에 유연하게 적용될 수 있는 범용적인 고해상도 이미지 합성 프레임워크를 제시함.
3. Methods
3.1. 지각적 압축 모델 (Perceptual Compression Model)
- 구성 : 인코더와 디코더로 이루어진 오토인코더를 사용함.
- 인코딩 : 원본 이미지 x를 인코더를 통해 잠재 표현 z로 변환함. 이때, 이미지 x는 H x W x 3 차원이고, 잠재 표현 z는 h x w x c 차원이 됨.
- 압축 비율 f = H / h = W / w에 따라 계산 복잡성 감소, 이 비율이 LDM의 효율성을 결정함.
- 손실 함수 : 단순히 픽셀 차이(L1/L2)를 사용하는 대신, 지각적 손실(Perceptual Loss)과 적대적 학습(GAN Objective)을 결합하여, 재구성된 이미지가 실제 데이터 분포에 가깝고 흐릿함(Blurriness)이 없도록 보장함.
- *지각적 손실 = 픽셀이 조금 달라도 구조, 질감, 패턴 등 지각적 특징이 유사하면 손실을 낮게 부여함.
- *적대적 학습 = 생성자 - 판별자 간의 경쟁하면서 상호 발전하는 학습 방법.
- 특징 : 이 압축 모델은 일반적인 목적으로 한 번만 학습하고, LDM 훈련에 재사용됨.
3.2. 잠재 확산 모델 (Latent Diffusion Model)
- 작동 : 노이즈 제거 UNet을 저차원 잠재 공간에서 훈련함.
- 학습 목표 : 노이즈가 섞인 잠재 표현 zt를 입력받아 노이즈 성분을 예측하고 제거함으로써 깨끗한 잠재 표현 z를 복원하는 것에 집중함.
- 효율성 : 픽셀 공간 대비 약 4배~16배 낮은 차원에서 훈련이 이루어져 계산 비용과 메모리 사용량이 극적으로 감소됨.
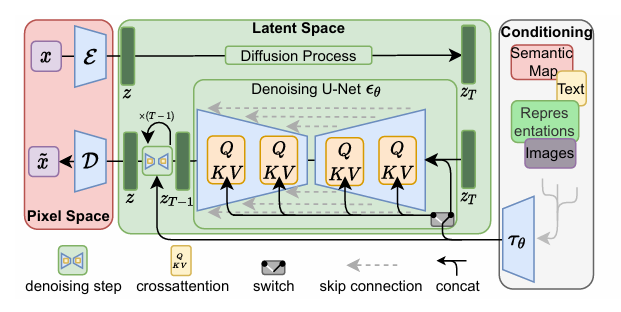
3.3. 조건부 메커니즘 (Conditioning Mechanism)
- 목적 : 텍스트, 시맨틱 맵 등 외부 조건 y를 통해 생성 과정을 제어함.
- 구현 : 교차 주의(Cross-Attention) 메커니즘을 UNet의 중간 계층과 하위 계층에 삽입하여 구현함.
- 흐름 :
- 조건 y는 도메인 특화 인코더를 통해 중간 표현으로 매핑됨.
- 이 표현은 교차 주의 레이어에서 잠재 표현과 상호작용하며, 잠재 공간의 어떤 부분이 조건에 집중해야 하는지 학습됨.
4. Experiments
- 계산 복잡성 및 효율성 분석 :
- 픽셀 기반 Diffusion Model 대비 LDM이 수십 배 더 효율적임을 입증함.
- 동일한 계산 자원 내에서 더 낮은 FID(더 좋은 품질)에 빠르게 도달하여 효율성과 성능의 우위를 확인함.
- 비조건부 이미지 합성 품질 :
- CelebA-HQ, FFHQ, LSUN 등 다양한 데이터셋에서 기존 DMs 및 GAN 기반 모델의 FID를 능가하는 최고 성능(SOTA)을 달성함.
- 텍스트-이미지 합성 및 제어 :
- 교차 주의 메커니즘을 사용한 LDM이 당시 최고 모델들을 뛰어넘는 FID 및 CLIP 점수를 달성함.
- 이를 통해 외부 조건에 따른 강력하고 유연한 제어 가능성을 입증함.
- 이미지-대-이미지 변환 (고해상도 적용) :
- 임페인팅 및 초해상화 작업에서 픽셀 기반 모델보다 빠른 속도(약 2.7배)와 더 좋은 품질을 보임.
- 훈련 해상도를 넘어선 메가픽셀 해상도의 출력이 일관성 있게 가능함을 입증함.
5. Insight
- Diffusion Model의 민주화(상용화 가능) : LDM은 확산 모델의 학습 및 추론 비용을 획기적으로 낮춰, 대규모 GPU 클러스터 없이도 고성능 이미지 생성 모델을 연구하고 개발할 수 있는 길을 열어주었음.
- 정보 압축의 중요성 : 지각적 압축 단계가 사람의 눈에 중요하지 않은 정보를 제거하는 데 성공함으로써, 확산 모델이 이미지의 핵심 의미적 내용에만 집중할 수 있게 된 것이 효율성의 근본 원인임.
- 조건부 생성의 표준 : 교차 주의 메커니즘은 후속 연구들이 텍스트, 레이아웃, 깊이 맵 등 다양한 형태의 조건을 확산 모델에 통합하는 표준적인 방법론을 제시했음.
- 파급 효과 : 이 LDM 아키텍처는 오늘날 가장 널리 사용되는 이미지 생성 모델인 Stable Diffusion의 직접적인 기술적 기반이 되었으며, AI 아트 및 디자인 산업 전반에 혁명을 일으킨 핵심 논문으로 평가받음.
2. ControlNet - Adding Conditional Control to Text-to-Image Diffusion Models (2023)
ICCV 2023 Open Access Repository
Adding Conditional Control to Text-to-Image Diffusion Models Lvmin Zhang, Anyi Rao, Maneesh Agrawala; Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 3836-3847 Abstract We present ControlNet, a neural network archi
openaccess.thecvf.com
1. Abstracts
- 이 논문은 ControlNet이라는 새로운 신경망 아키텍처를 제안함.
- 이는 대규모 사전 학습된 텍스트-이미지 확산 모델(Diffusion Models)에 공간적 조건 제어(Spatial Conditioning)를 추가하는 것을 목적으로 함.
- 사전 학습된 대규모 모델의 가중치를 잠금(Lock) 상태로 유지하여 기존 학습했던 견고한 지식을 보존함.
- 잠금된 모델의 인코딩 레이어를 재사용하여 다양한 조건적 제어(Conditional Controls)를 학습할 수 있는 학습 가능한 복사본을 구성함.
- 이 두 모델은 제로 컨볼루션(Zero Convolutions)으로 연결되어, 학습이 진행될수록 조건적 제어 능력이 점진적으로 성장하는 특성을 보임.
2. Introduction
- 문제 인식 : Stable Diffusion과 같은 대규모 확산 모델은 높은 품질의 이미지를 생성하지만, 이미지의 공간적 구성을 정밀하게 제어하는 능력은 텍스트 프롬프트만으로는 매우 부족함.
- 기존 방식의 한계 : 새로운 제어 조건을 학습시키기 위해 모델 전체를 미세 조정(Fine-tuning) 할 경우, 이전에 학습했던 방대한 일반 지식을 잃어버리는 재앙적 망각(Catastrophic Forgetting) 문제가 발생함.
- ControlNet의 기여 : 재앙적 망각을 방지하면서, 이미지 형태의 조건 입력(Canny Edge, Pose 등)을 통해 이미지 생성 과정을 정교하게 제어하는 새로운 프레임워크를 제공함.
3. Methods
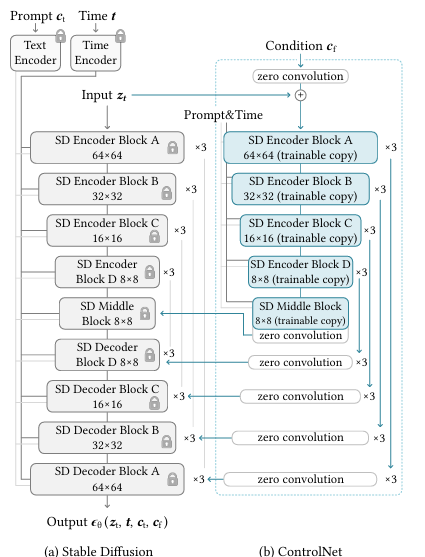
- 복제된 네트워크 구조 : ControlNet은 확산 모델의 인코딩 블록을 복제하여 두 세트의 가중치로 분리함.
- Locked Copy (잠금된 복사본) : 원본 모델의 가중치를 그대로 동결(Freeze)하여, 수십억 장의 이미지 학습으로 얻은 고품질 생성 능력을 보존함.
- Trainable Copy (학습 가능한 복사본) : 조건적 제어를 학습하기 위해 0에서부터 새로 학습되는 복사본임.
- 제로 컨볼루션 (Zero Convolutions) :
- 잠금된 블록과 학습 가능한 블록의 입력 및 출력단에 가중치와 편향이 모두 0으로 초기화된 1x1 컨볼루션 레이어를 사용함.
- 학습 시작 시 출력값이 항상 0이므로, 복사본의 초기 학습 상태가 잠금된 원본 모델에 노이즈나 오류를 전달하지 않도록 안전장치 역할을 함.
- 이를 통해 훈련이 시작될 때부터 고품질의 출력을 유지하며, 학습을 통해 조건적 제어 능력을 점진적이고 안정적으로 습득함.
- 효율성 : 학습 시 전체 모델의 파라미터 중 절반(잠금된 부분)은 업데이트되지 않으므로, 효율적인 자원 활용이 가능함.
4. Experiments
- 광범위한 제어 능력 입증 : Canny Edge, HED Boundary, Human Pose, Semantic Segmentation, Depth Map, Normal Map, Scribble 등 7가지 이상의 다양한 조건적 입력에 대해 ControlNet이 성공적으로 제어 능력을 학습함을 보여줌.
- 재앙적 망각 방지 확인 : ControlNet을 통해 학습된 모델이 미세 조정을 거친 기존 모델과 달리, 원래의 생성 능력을 완벽하게 유지함을 정성적, 정량적으로 입증함.
- 제로 컨볼루션의 중요성 검증 : 제로 컨볼루션이 없을 경우, 학습 초기에 출력이 심하게 훼손되거나 학습이 실패함을 확인하여 해당 구조의 필수성을 확인함.
- Multi-Control 실현 : 여러 개의 ControlNet을 쌓아서 두 가지 이상의 조건(예: 포즈와 깊이 맵)을 동시에 적용하여 복합적인 제어를 수행할 수 있음을 실험적으로 증명함.
5. Insights
- 정교한 제어의 민주화 : 대규모 확산 모델에 대한 사용자의 통제력을 획기적으로 향상시켜, AI 아트를 상업적 디자인 및 실제 창작 과정에 도입할 수 있는 길을 열었음.
- 저수준/고수준 비전의 결합 : 외곽선이나 포즈 같은 저수준(Low-level)의 이미지 특징을, 텍스트 프롬프트로 제어되는 고수준(High-level)의 방대한 지식 모델에 안전하고 효과적으로 통합하는 패러다임을 구축함.
- 높은 확장성 : ControlNet의 구조는 Stable Diffusion 외의 다른 대규모 사전 학습 모델에도 적용할 수 있어, 향후 다양한 생성 모델에 조건부 제어 기능을 쉽게 추가할 수 있을 것으로 예상됨.
3. MAE (Masked Autoencoders Are Scalable Vision Learners) (2022)
CVPR 2022 Open Access Repository
Masked Autoencoders Are Scalable Vision Learners Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 16000-16009 Abstract This p
openaccess.thecvf.com
1. Abstracts
- MAE(Masked Autoencoders)는 컴퓨터 비전을 위한 확장 가능한 자가 지도 학습(Self-supervised Learning) 방법임을 제시함.
- 접근 방식은 간단하여, 입력 이미지의 랜덤 패치를 가리고(Masking), 가려진 픽셀을 복원하도록 학습함.
- 핵심 디자인은 두 가지로 구성됨.
- 비대칭 인코더-디코더(Asymmetric Encoder-Decoder) 구조를 개발함. 인코더는 가려지지 않은 보이는 패치(Visible Patches)만 처리하며, 경량 디코더가 가려진 부분을 복원함.
- 입력 이미지의 높은 비율(ex. 75%)을 가리는 것이 비전 문제에 의미 있는 자가 지도 학습 과제가 됨을 발견함.
- 이 두 디자인의 결합으로 대규모 모델을 효율적이고 효과적으로 학습할 수 있었으며, 학습 속도(3배 이상)와 정확도를 모두 개선함.
- MAE의 확장성은 ViT-Huge 모델이 ImageNet-1K 데이터셋만으로 최고 정확도(87.8%)를 달성하는 등 뛰어난 결과를 입증함.

2. Introduction
- NLP 분야에서 BERT의 성공을 이끈 토큰 마스킹 및 복원(Masked Token Prediction) 패러다임을 비전 분야에 적용하고자 함.
- 기존 이미지 복원 기법은 이미지의 높은 공간적 중복성(Spatial Redundancy) 때문에 모델이 깊은 의미를 학습하기 어렵다는 한계가 있었음.
- MAE는 이 문제를 해결하기 위해 높은 마스킹 비율(75%)을 적용하여 모델이 주변 픽셀을 통한 단순 예측이 아닌, 전체 이미지의 맥락을 이해하도록 유도함.
- 또한, 가려진 패치(75%)를 인코더의 입력에서 제외하는 비대칭 구조를 도입하여, 학습 효율성을 극적으로 높여 대규모 모델 학습의 병목 현상을 해소함.
- MAE는 기존 방식 대비 단순성, 효율성, 확장성을 모두 갖추어 대규모 비전 학습을 위한 새로운 길을 열었음을 강조.
3. Methods
- 마스킹 전략 : 입력 이미지를 패치로 나눈 후, 75%의 패치를 무작위로 마스킹하여 인코더 입력에서 제거함.
- 인코더 (Encoder) : ViT(Vision Transformer) 기반의 구조를 사용하며, 마스킹된 패치를 제외한 25%의 보이는 패치만 처리함. 이는 연산량을 획기적으로 줄이는 핵심 요소임.
- 디코더 (Decoder) : 인코더의 출력(압축된 특징)과 마스킹된 패치의 위치 정보를 담은 마스크 토큰(Mask Tokens)을 모두 받아 전체 이미지를 재구성함. 디코더는 인코더보다 층 수가 적은 경량 구조(Lightweight)로 설계하여 효율성을 유지함.
- 복원 목표 (Reconstruction Target) : 가려진 패치에 해당하는 원본 픽셀 값을 복원하도록 학습함. 학습 손실(Loss)은 가려진 패치 부분에 대해서만 계산함.
- 모델 구조의 비대칭성 : 인코더는 복잡한 특징을 학습하고, 디코더는 간단한 복원 작업을 수행하도록 역할을 분리하여 전체 학습 과정의 효율과 성능을 극대화함.
4. Experiments
- ImageNet 분류 : ImageNet-1K 데이터셋을 활용하여 사전 학습을 진행하였으며, ViT-Huge 모델에서 87.8%의 최고 정확도를 달성함.
- 확장성 검증 : 모델 크기가 커질수록 성능 향상 폭이 커지는 선형적 확장성을 입증하여, MAE가 대규모 모델 학습에 최적화된 방식임을 보여줌.
- 구성 요소 분석 (Ablation Studies) :
- 마스킹 비율 : 75% 마스킹 비율이 가장 우수한 성능을 보였으며, 이는 비전 분야에서 높은 마스킹이 효과적임을 확인한 결과임.
- 디코더 설계 : 경량 디코더(ex. 8개 블록)가 충분한 복원 능력을 가지면서도 학습 효율을 해치지 않음을 입증함.
- 전이 학습 (Transfer Learning) : MAE로 사전 학습된 모델을 객체 탐지(Object Detection) 및 인스턴스 분할(Instance Segmentation)과 같은 다운스트림 과제에 적용하였으며, 지도 학습 기반 모델을 능가하는 성능을 시연함.
5. Insights
- ViT에 대한 최적의 학습 방식 : MAE는 ViT 아키텍처의 특성(패치 기반 처리)을 최대한 활용하여 효율적인 자가 지도 학습이 가능함을 확인시켜줌.
- 효율적인 대규모 학습의 가능성 : 인코더의 입력에서 마스킹된 패치를 제외하는 비대칭 구조 덕분에 높은 성능을 유지하면서도 학습 시간을 획기적으로 단축(3~4배)할 수 있음.
- 새로운 시각적 사전 학습 패러다임 : NLP의 '가려진 토큰 복원' 방식을 비전 데이터의 특성(높은 중복성)에 맞게 '높은 마스킹 비율 + 비대칭 구조'로 변형하여 성공적인 결과를 도출함.
- 일반화 및 전이 성능 우수성 : 대규모 비라벨 이미지에서 학습된 모델이 지도 학습으로 학습된 모델보다 더 나은 일반화 성능을 보였으며, 이는 광범위한 다운스트림 과제에 효과적으로 전이될 수 있음을 시사함.
4. MAISI : Medical AI for Synthetic Imaging (2024)
https://ieeexplore.ieee.org/abstract/document/10943915/
MAISI: Medical AI for Synthetic Imaging
Medical imaging analysis faces challenges such as data scarcity, high annotation costs, and privacy concerns. This paper introduces the Medical AI for Synthetic Imaging (MAISI), an innovative approach using the diffusion model to generate synthetic 3D comp
ieeexplore.ieee.org
1. Abstracts
- 의료 영상 분석이 직면한 데이터 희소성, 높은 주석 비용, 개인 정보 보호 문제를 해결하고자 함.
- 3차원(3D) CT 이미지를 합성 생성하는 혁신적인 확산 모델(Diffusion Model) 기반 접근 방식인 MAISI를 제안함.
- 파운데이션 볼륨 압축 네트워크와 잠재 확산 모델(LDM)을 활용하여 512 x 512 x 768 에 이르는 초고해상도 CT 이미지 생성을 특징으로 함.
- ControlNet을 통합하여 127개 해부학적 구조에 대한 분할 정보(Segmentation)를 조건으로 입력하여 정밀하게 제어함.
- 이로써 정확하게 주석이 달린 합성 이미지를 생성하여 다양한 다운스트림 작업에 활용 가능함을 입증함.
- MAISI가 현실적이고 해부학적으로 정확한 이미지 생성 능력을 보여주며, 의료 AI 개발의 주요 난제를 완화할 수 있다는 잠재력을 제시함.
2. Introduction
- 의료 AI의 상용화는 학습 데이터 부족과 민감한 환자 정보 보호 문제로 인해 심각한 제약을 받고 있음.
- 의료 데이터는 확보가 어려울 뿐 아니라, 전문가에 의한 수동 주석 작업이 필수적이어서 비용과 시간이 매우 많이 소요됨.
- 기존의 3D 생성 모델들은 높은 메모리 사용량으로 인해 초고해상도 이미지 처리가 어렵고, 생성된 이미지의 해부학적 구조를 정밀하게 제어하는 기능이 부족함.
- 위 논문은 이러한 한계를 극복하고 초고해상도 3D 의료 영상을 정밀하게 제어하며 생성할 수 있는 새로운 프레임워크 MAISI를 제안함.
- MAISI는 대용량 3D 데이터 처리 기술과 정밀 제어 기술을 결합하여 의료 AI 개발의 병목 현상을 해결하는 것을 목표로 함.
3. Methods
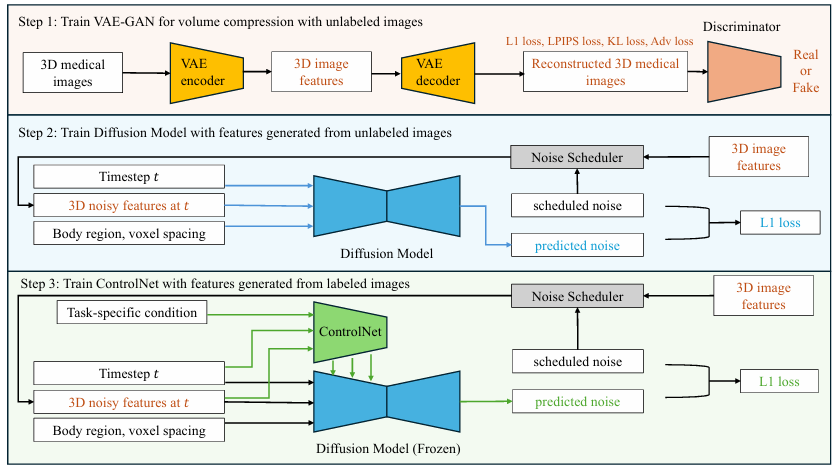
3.1. MAISI 아키텍처 구성
- MAISI는 크게 Volume Compression Network, Latent Diffusion Model, ControlNet 세 가지 핵심 모듈로 구성됨.
3.2. Volume Compression Network
- 고해상도 3D CT 볼륨을 메모리 및 계산 효율이 높은 잠재 공간(Latent Space)으로 압축하고 복원하는 역할을 담당함.
- 이를 통해 잠재 공간에서 확산 모델이 학습할 수 있는 기반을 마련함.
3.3. Latent Diffusion Model (LDM)
- 압축된 잠재 공간에서 이미지 생성 과정을 수행하는 핵심 모듈임.
- 노이즈를 단계적으로 제거하며 컨디셔닝 입력(ex. 신체 부위, 복셀 간격)에 맞는 3D 특징을 생성함.
- 기존 2D 확산 모델을 3D 볼륨 처리에 맞게 확장함.
3.4. ControlNet을 통한 정밀 제어
- 이미 학습된 LDM의 가중치를 고정하고, 추가적인 조건(Additional Condition)을 입력받아 생성 결과를 정밀하게 제어하는 모듈임.
- 주요 조건으로 장기 분할 마스크(Organ Segmentation Mask)를 사용하여 원하는 해부학적 구조를 정확하게 반영하는 이미지를 생성함.
- 재학습 없이 다양한 조건에 유연하게 대응하여 정확한 주석이 달린 데이터를 확보하는 데 핵심적인 역할을 함.
3.5. TSP (Tensor Splitting Parallelism)
- 기술 혁신 : 대규모 3D 텐서 처리 시 발생하는 GPU 메모리 부족 문제를 해결하기 위해 제안된 병렬 처리 기법임.
- 3D 볼륨의 특징 맵(Feature Map)을 작은 청크(Chunk)로 분할하여 GPU에 나누어 처리함으로써, 초고해상도 3D 이미지의 학습 및 생성을 가능하게 함.
4. Experiments
- 데이터셋 : 대규모 3D CT 데이터셋(ex. WORD 데이터셋, MSD Task)을 사용하여 모델의 성능을 검증함.
- 3D 생성 품질 : MAISI가 512 x 512 x 768 해상도의 초고해상도 3D CT 볼륨을 성공적으로 생성함을 시각적으로 및 정량적으로 입증함.
- 분할 기반 제어 성능 : ControlNet을 통해 입력된 127개 해부학적 구조의 분할 마스크에 매우 정확하게 일치하는 합성 이미지를 생성함을 확인했음.
- 데이터 증강 효과 : MAISI로 생성한 합성 데이터를 기존의 실제 데이터와 함께 종양 분할(Tumor Segmentation) 모델 학습에 사용했음.
- 성능 향상 : 특히 데이터셋이 작은 작업(MSD Task06)에서 합성 데이터를 1:1.5 비율로 추가했을 때, 분할 성능이 실제 데이터만을 사용했을 때보다 상대적으로 약 3.9% 향상됨을 보여줌.
- 합성 데이터가 의료 AI 모델의 일반화 능력과 견고성을 향상시키는 데 기여함을 확인함.
5. Insights
- 3D 고해상도 생성의 장벽 극복 : TSP와 LDM의 결합을 통해 기존 메모리 제약으로 인해 어려웠던 초고해상도 3D 의료 영상 생성의 기술적 난제를 해결함.
- 주석 정확도 혁신 : ControlNet을 사용하여 해부학적 구조를 정밀하게 제어함으로써, 생성된 합성 데이터가 정확한 주석 정보를 내포하게 됨. 이는 수동 주석 작업의 비용과 시간을 획기적으로 절감할 잠재력을 가짐.
- 실질적인 성능 기여 : 합성 데이터가 단순히 시각적 품질만 좋은 것이 아니라, 실제 다운스트림 AI 모델의 성능 향상에 유의미하게 기여함을 입증함.
- 의료 AI 생태계 기여 : MAISI는 데이터 부족 문제를 해소하고 안전한 연구 환경을 제공함으로써, 희귀 질병 분석 및 새로운 AI 모델 개발을 가속화할 수 있는 중요한 파운데이션 모델로서의 역할을 할 것으로 기대됨.
'Paper_Review' 카테고리의 다른 글
| [jekim] paper review (0) | 2025.11.15 |
|---|---|
| [jekim] Paper review (1) | 2025.11.08 |
| [jekim] Paper review (0) | 2025.11.03 |
| [jyhan] paper review (0) | 2025.11.01 |
| [jekim] Paper review (2) | 2025.10.20 |