논문에서는 의료 분야에서 다중 모달 기초 모델의 활용을 개선하기 위해 Knowledge-enhanced Auto Diagnosis(KAD)를 제안합니다. 기존의 대규모 자연어 및 컴퓨터 비전 모델은 의료 분야에서 정밀한 분석과 높은 수준의 전문 지식이 필요해 한계가 존재합니다.
이를 해결하기 위해 KAD는 의료 도메인 지식을 활용하여 X-ray 영상과 방사선 보고서를 함께 학습하는 비전-언어 사전 학습을 수행합니다. 실험 결과 네 개의 외부 X-ray 데이터셋에서 평가한 결과, 별도의 학습 없이도 기존의 완전 지도 학습 모델과 비슷한 성능을 보였으며, 다섯 가지 병리 중 세 가지에서는 전문가 세 명의 평균보다 우수한 진단 성능을 통계적으로 유의미하게 달성했습니다.
또한, 소량의 주석 데이터만으로 학습이 가능한 환경에서도 기존의 모든 모델보다 뛰어난 성능을 보이며 다양한 임상 환경에서의 활용 가능성을 확인할 수 있었습니다.
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
BERT, GPT, CLIP과 같은 기초 모델은 의료 분야에서의 기초 모델 개발은 상대적으로 더딘 상황입니다. 기존의 visual-text modal 정렬 기법을 의료 도메인에 그대로 확장하는 방식은 훈련 데이터에는 없는 질병이나 방사선학적 소견에 대해 일반화하기 어렵습니다. 이는 의료 진단에서 요구되는 정밀한 인식 능력과 관련이 있는데, 질병 진단의 핵심 단서는 미세하고 국소적인 경우가 많으며, 의료 용어 자체도 추상적이고 복잡하여 전문적인 지식이 필요합니다.
Ex) 'infiltrates'는 폐의 흰 반점을 의미하는데, 이러한 개념은 단순한 언어적 정렬만으로는 효과적으로 학습하기 어렵습니다.
따라서 의료 응용에서 요구되는 복잡하고 특수한 개념을 효과적으로 모델링하기 위해서는 도메인 지식을 필수적으로 반영해야 합니다.
논문에서는 가슴 X-ray 영상과 방사선학적 보고서를 함께 학습하여 Knowledge-enhanced Auto Diagnosis (KAD) 모델을 구축하는 것을 목표로 합니다. 기존 방식은 단순히 이미지를 원본 텍스트 보고서와 정렬하는 데 그쳤지만, KAD는 보고서에서 유용한 정보를 추출하는 다양한 방법을 탐색하고, 체계적으로 구축된 의료 지식 그래프를 활용하여 지식 인코더를 학습합니다.
KAD는 두 단계로 구성됩니다. 먼저 의료 지식 그래프의 뉴럴 표현을 학습하여, 질병이나 의학 개념을 노드로, 개념 간 관계를 엣지로 설정해 다단계 추론이 가능한 구조를 만듭니다. 이후 방사선학적 보고서에서 임상적 개체(entity)와 관계를 추출하는데, 이를 정의된 규칙 기반 방법, RadGraph, ChatGPT 등을 이용해 수행합니다. 이렇게 추출된 정보를 사전 학습된 Knowledge Encoder를 통해 시각적 표현 학습에 반영함으로써, 도메인 지식을 효과적으로 시각 인코더에 주입할 수 있도록 설계하였습니다.
또한 새로운 질병이나 방사선학적 소견에 대한 유연한 제로샷 평가를 가능하게 하기 위해 Disease Query Network (DQN)이라는 쿼리 기반 트랜스포머 아키텍처를 활용합니다. 이 모델은 질병명을 ‘쿼리’로 입력받아 시각적 특징을 반복적으로 참조하며 예측을 수행하며, attention 맵을 통해 신뢰할 수 있는 임상적 근거를 제공합니다.
KAD의 효과를 입증하기 위해 PadChest, ChestXray14, CheXpert, ChestX-Det10 등 네 개의 외부 X-ray 데이터셋을 활용하여 실험을 진행하였습니다. KAD는 학습 과정에서 보지 않은 병리학적 소견에 대해서도 자동 진단 성능이 뛰어나며, PadChest의 193개 병변에 대한 제로샷 성능이 기존 최첨단 의료 영상-언어 모델을 크게 웃도는 것으로 나타났습니다. 또한, 완전 지도 학습된 모델과 비교해도 성능이 유사하거나 우수한 결과를 보였습니다.
KAD는 X-ray 영상과 방사선학적 보고서를 함께 학습한 최초의 모델로 CheXpert 데이터셋에서 방사선 전문의 평균 진단 성능과 대등하거나 일부 병변에서는 이를 능가하는 성과를 보였습니다. 추가적인 수작업 주석(annotation)이 제공될 경우, 기존의 자기지도 학습(self-supervised learning) 방식과 동일한 프로토콜로 모델을 미세 조정할 수 있으며, 이때 성능이 더욱 향상되는 것이 확인되었습니다. 이를 통해 KAD가 뛰어난 전이 학습(transfer learning) 능력을 갖추고 있음을 입증하였습니다.

[ Knowledge Base은 개념-관계-개념 삼중항(triplet)으로 구성된 지식 그래프와 개념 정의 쌍으로 이루어진 개념 정보 목록으로 구성됩니다. Knowledge Encoder는 양성 샘플 간의 유사성을 극대화하는 방식으로 학습되어 텍스트 표현을 효과적으로 학습합니다. 이후 방사선학적 보고서에서 임상 개체(clinical entities)와 관계를 추출하는데, 이는 휴리스틱 규칙, 기존의 보고서 정보 추출 도구(Entity Extraction) 또는 ChatGPT를 활용하여 수행할 수 있습니다. 추출된 임상 개체를 활용해, 사전 학습된 지식 인코더와 함께 흉부 X-ray와 보고서 간의 이미지-텍스트 대조 학습(contrastive learning)을 진행하며, 이를 통해 질병 분류를 위한 Disease Query Network(DQN)를 최적화합니다. 추론 단계에서는 질병명을 쿼리 입력으로 제공하면, DQN이 해당 병리학적 소견이 입력된 영상에서 나타날 확률을 출력하는 방식으로 진단을 수행합니다. ]
제안하는 Knowledge-enhanced Auto Diagnosis(KAD)의 목표는, 도메인 지식을 활용하여 흉부 X-ray 영상의 자동 진단 성능을 향상시키고 비전-언어 사전 학습을 개선하는 것입니다. 여기서 도메인 지식은 기존의 지식 그래프(Unified Medical Language System, UMLS), 사전 정의된 휴리스틱 규칙, 또는 보고서 정보 추출 도구(RadGraph) 등을 포함합니다.
본 논문에서는 모든 비교 모델을 MIMIC-CXR14 데이터셋에서 사전 학습한 후, PadChest, NIH ChestX-ray, CheXpert, ChestX-Det10의 네 가지 다기관(multi-center) 데이터셋에서 제로샷(zero-shot) 방식으로 평가하였습니다. 모든 실험에서 모델은 특정 질병이 입력된 영상에서 존재하는지를 예측하는 방식으로 추론을 수행합니다.
본 논문의 핵심은 의료 도메인 지식을 사전 학습 과정에 효과적으로 통합하는 것으로, UMLS나 RadGraph와 같은 정보를 활용하여 기존의 자가 지도 학습(self-supervised learning) 방식보다 추가적인 정보를 제공합니다. 그러나 KAD의 학습 과정에서는 기존의 도구를 그대로 활용하므로, 대규모 데이터셋에도 확장 가능하며 기존 자가 지도 학습 모델과 동등한 확장성을 갖습니다.
훈련되지 않은 새로운 질병을 인식하는 능력과 희소 질환(long-tail recognition) 문제를 다루는 데 있어 기존 방법보다 뛰어난 성능을 보였습니다. 추가적으로, 이미지 해상도 및 시각적 백본(visual backbone)의 영향, 모델 구성 요소별 기여도를 분석하는 다양한 분석 실험을 수행하였습니다.

Figure 2에서는 PadChest 데이터셋 내 전문가가 주석을 단 하위 집합(n=39,053개의 흉부 X-ray 이미지)을 이용하여 모델 성능을 평가한 결과를 보여줍니다. 모델의 성능은 AUC(Area Under the Curve)와 95% 신뢰 구간(CI)를 기준으로 측정되었으며, 이는 각 방사선학적 소견 또는 진단(class)에 대해 계산되었습니다. 단, 분석 대상이 된 class는 테스트 데이터셋에서 샘플 수(n)가 50개 이상인 경우로 한정되었습니다.
a) 학습에 사용된 class의 결과: CheXNet은 PadChest 데이터셋에서 학습된 지도 학습(supervised learning) 모델
b) 학습에 사용되지 않은 class의 결과: KAD는 177개의 학습하지 않은 class 중에서 31개 class에서 최소 0.900 이상의 AUC를 달성했으며 111개 class에서는 최소 0.700 이상의 AUC를 기록
Figure 2는 테스트 데이터셋에서 샘플 수가 50개 이상인 상위 50개 class에 대한 모델의 성능을 시각적으로 보여주고 있으며, 특히 KAD 모델이 학습되지 않은 class에서도 높은 AUC를 달성할 수 있음을 입증하는 중요한 결과를 제공합니다.
KAD는 PadChest 데이터셋에서 진단 작업을 평가했습니다. 데이터셋은 174개의 다양한 방사선학적 소견과 19개의 차별 진단이 라벨링되어 있습니다. PadChest 데이터셋의 주요 도전 과제는 long-tailed class distribution입니다. 예를 들어, 21개 클래스만 1000개 이상의 샘플을 가지고 있고, 16개 class만 사전 학습 동안 모델에 의해 학습됩니다. 여기서 Disease Query Network(DQN)가 훈련 중에 본 질병을 seen diseases으로, 그렇지 않은 질병을 unseen diseases으로 구분합니다.
Figure 2a에서는 KAD가 기존의 완전 지도 학습(supervised learning) 모델보다 뛰어난 성능을 보였으며, 특히 CheXNet과 비교했을 때 5가지 병리 진단에서 더 좋은 결과를 얻었습니다. Figure 2b를 보면, KAD 모델은 기존의 최첨단(SOTA) 모델보다 학습하지 않은 방사선학적 소견(class)에서 더 좋은 성능을 보였습니다.
- 기흉(pneumothorax): AUC 0.809 (95% CI: 0.796–0.822)
- 심비대(cardiomegaly): AUC 0.916 (95% CI: 0.913–0.919)
- 응집(consolidation): AUC 0.910 (95% CI: 0.896–0.924)
- 부종(edema): AUC 0.966 (95% CI: 0.958–0.974)
- 폐렴(pneumonia): AUC 0.835 (95% CI: 0.829–0.842)

AUC와 F1 점수는 모든 질병에 대해 매크로 평균으로 보고되었습니다. 매크로 평균은 각 클래스의 성능을 동등하게 반영하기 위해 모든 클래스를 동일하게 평가한 값입니다. 이를 통해 각 질병에 대한 모델의 전체적인 성능을 한눈에 볼 수 있습니다.
또한, 공정성을 위해 모든 기준 모델들은 동일한 기본 이미지 인코더(ResNet50)를 사용했습니다. 즉, 네트워크 아키텍처의 차이가 모델 성능에 미치는 영향을 최소화하기 위해 동일한 백본을 사용하여 비교를 했습니다.'비율'은 훈련 데이터에 사용된 각 레이블의 비율을 나타내며, 이는 각 질병이 훈련 데이터에 얼마나 자주 등장하는지를 보여줍니다.
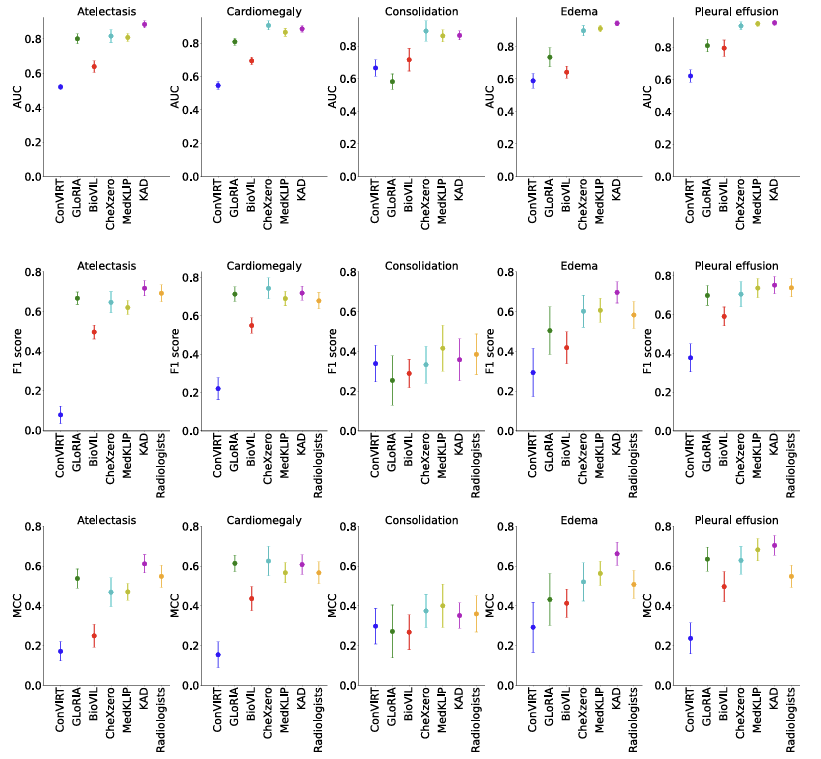
모든 모델은 CheXpert 데이터셋에서 제로 샷(Zero-shot) 설정으로 직접 평가되었습니다. AUC, F1 점수, 그리고 다섯 가지 병리에 대한 MCC가 그래프에 나타나 있으며, 평균 값과 95% 신뢰 구간(CI)이 함께 표시됩니다.
Figure 4는 KAD와 다른 이미지-텍스트 사전 훈련 모델의 실험 결과를 제시하며, 성능은 CheXpert 테스트 세트에서 세 명의 인간 방사선 의사와 비교되었습니다. 결과에 따르면, KAD는 기존 모델들보다 평균 평가 점수에서 일관되게 우수한 성능을 보였으며, 강력한 일반화 능력을 보여주었습니다. 세 명의 방사선 의사와 비교했을 때, KAD는 대다수의 경쟁 병리에서 Matthews 상관 계수(MCC) 메트릭에서 통계적으로 더 높은 평균을 기록했습니다.

AUC 점수는 (a)에서 제로 샷 분류 작업에 대해 표시되며, 포인팅 게임 점수는 (b)에서 제로 샷 위치 추적 작업에 대해 표시됩니다. 각 카테고리의 최대값으로 최상의 결과를 사용하고, (a)에서는 0.5를 최소값으로, (b)에서는 0을 최소값으로 설정하여 레이더 차트를 작성했습니다.
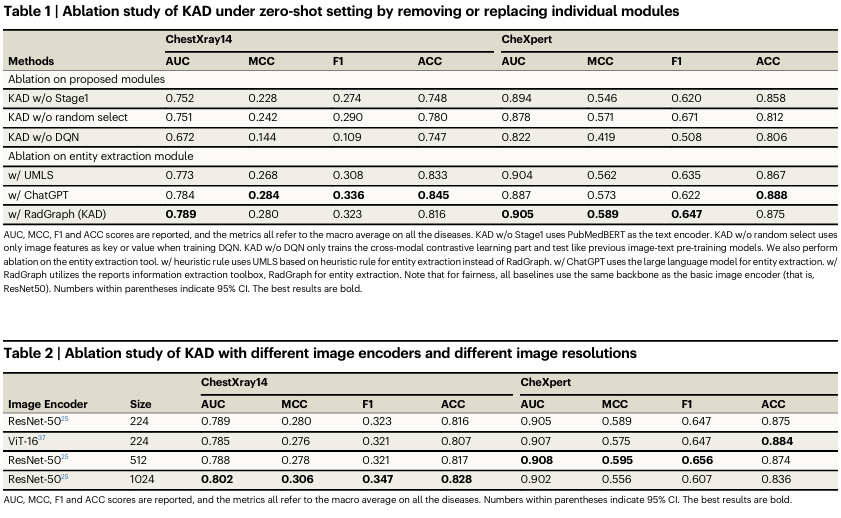
Figure 5는 ChestX-Det10 테스트 세트에서 제로 샷 진단과 질병 위치 추적 결과를 보여줍니다. 제안된 모델인 KAD는 기존 방법들에 비해 대부분의 경우에서 우수한 성능을 보였습니다. 특히, KAD는 GLoRIA보다 calcification(7% 이상)과 fracture(18% 이상)와 같은 어려운 카테고리에서 상당한 성능 향상을 달성했습니다. 또한, 질병을 정확하게 위치 추적하는 능력이 이미지 해상도가 증가함에 따라 크게 향상되었습니다. 마지막으로 KAD에 대한 상세한 소거 연구가 표 1과 표 2에 제공됩니다.
Discussion
논문의 목적은 의료 분야에서 기존의 지식 선행 정보를 활용하여 흉부 X-ray에 대한 기초 모델을 개발하는 것입니다. CheXpert 데이터셋에서 KAD와 인간 전문가 방사선 의사의 성능을 비교한 결과, KAD는 일부 진단 작업에서 경험이 풍부한 의사들의 성과를 뛰어넘거나 동등한 성과를 보였으며, 특히 5개 병리에 대한 MCC 점수가 방사선 의사들의 평균 성과보다 통계적으로 유의미하게 높았습니다. 이는 지식 강화된 사전 훈련의 효과를 입증하므로 KAD 모델은 의사들 간 의견 차이가 있을 때 참고 자료로 활용될 수 있습니다.
Fig. 2a에서 KAD의 성능은 PadChest에서 완전 지도 학습(supervised learning) 모델과 유사하거나 더 나은 성과를 보였습니다. 완전 지도 학습(supervised learning) 모델 은 고정된 범주의 카테고리만 적용할 수 있는 반면 KAD는 임의의 병리를 input으로 받아들이며 PadChest에서 고도 정확도로 방사선학적 발견을 식별할 수 있어 강력한 일반화 능력과 다양한 임상 진단 카테고리에 대한 강한 내성을 보여줍니다. KAD는 다른 기존 모델들과 비교했을 때, 고유한 의료 지식 기반을 사용하여 의료 영상과 텍스트 사이의 관계를 강화하고, 이를 통해 훈련되지 않은 질병이나 진단을 정확하게 예측할 수 있는 능력을 보여주었습니다.
KAD는 단순한 진단 성능 향상뿐만 아니라, 해석 가능한 예측을 통해 임상 결정을 지원할 수 있는 가능성도 보여주었습니다. KAD는 예측 결과에 대해 시각적으로 근거를 제공하여, 의사들이 AI 모델의 예측을 이해하고 신뢰할 수 있도록 돕습니다. 이를 통해 KAD는 의료 분야에서 AI 기반 진단 도구로서의 활용 가능성을 더욱 확고히 했습니다.
그러나 몇 가지 한계점이 존재합니다. 첫째, 사전 학습된 모델은 다른 모델과 마찬가지로 하이퍼파라미터 조정을 위해 소규모 검증 세트를 필요로 합니다. 둘째, 일부 병리학적 특성은 지식 그래프에서 다른 질병과의 관계가 없거나 보고서에서 언급되지 않을 수 있습니다. 셋째, KAD의 진단은 분류와 대략적인 위치 지정에만 한정되어 있으며, 정확한 세분화(segmentation)는 제공하지 못합니다.
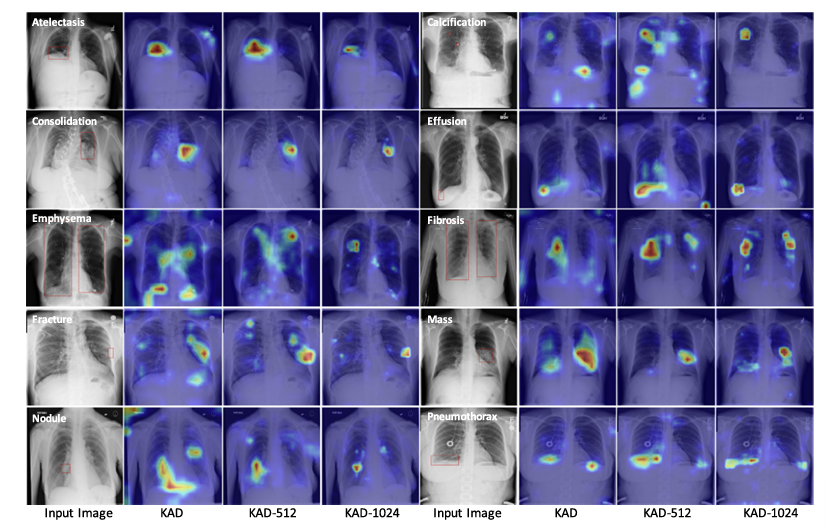
원본 이미지에서 빨간색 박스는 방사선 전문의가 주석한 병변 부위를 나타냅니다. 어텐션 맵(attention map)에서는 빨간색에서 파란색으로 이어지는 스펙트럼을 사용하여, 빨간색은 높은 어텐션(high-attention) 영역을, 파란색은 낮은 어텐션(low-attention) 영역을 의미합니다.
데이터셋
실험에서는 MIMIC-CXR14 데이터셋을 사용하여 모델을 사전 훈련합니다. MIMIC-CXR는 공공 데이터셋으로, 흉부 방사선 영상과 방사선학적 보고서를 포함합니다. 이 데이터셋은 총 377,110개의 X-ray 이미지와 227,835건의 방사선 검사, 그리고 65,379명의 환자 데이터를 포함하고 있습니다. 각 방사선 검사는 자유 형식의 방사선학 보고서와 연결되어 있으며, 이미지(전면 또는 측면 뷰)와 함께 제공됩니다. 보고서는 방사선 전문의가 작성한 검사 결과 요약으로, 검사 방법, 소견, 인상, 비교 등의 여러 섹션으로 구성됩니다. 실험에서는 소견(findings)과 인상(impressions) 섹션만을 사용합니다.
의료 영상-텍스트 사전 학습 방법
• ConVIRT: 의료 영상과 보고서의 쌍을 사용하여 양방향 대비 학습(contrastive learning) 방식으로 비전 및 텍스트 인코더를 공동 학습
• GLoRIA: 의료 영상과 보고서 간의 전역(global) 및 지역(local) 대비 학습을 통해 상호작용을 모델링
• BioVIL: 방사선학 특화 텍스트 인코더를 사전 학습한 후, 영상-텍스트 쌍을 사용한 대비 학습 수행
• CheXzero: 사전 학습된 CLIP 모델을 X-ray 및 보고서에 맞춰 미세 조정(fine-tuning)하여 대비 학습 진행
• MedKLIP: 의료 분야에 특화된 지식 설명을 활용하여 영상-언어 사전 학습을 향상
의료 영상 사전 학습 방법
• Model Genesis: 국소적 셔플링(local shuffling), 비선형 변환(nonlinear transformation), 인-페인팅(in-painting) 및 아웃-페인팅(out-painting) 등 인위적인 변형을 가한 후, 원본 이미지를 복원하는 방식으로 자기 지도 학습(self-supervised learning) 수행
• Comparing to Learn (C2L): 이미지 및 특징(feature) 수준에서 데이터를 혼합한 후, 이를 통해 양성(positive) 및 음성(negative) 쌍을 생성하여 대비 학습 진행
• ImageNet 사전 학습: 대규모 자연 이미지 데이터셋에서 지도 학습(supervised learning)을 수행한 대표적인 방식
데이터 전처리 과정에서는 흉부 X-ray 이미지와 방사선 보고서를 효과적으로 활용하기 위해 이미지와 텍스트를 각각 다르게 처리합니다. 먼저, 이미지 전처리 과정에서는 모든 흉부 X-ray 이미지를 224×224 크기로 조정한 후, 전체 학습 데이터셋에서 계산된 평균과 표준편차를 사용하여 정규화합니다. 또한, 모델의 일반화 성능을 향상시키기 위해 다양한 데이터 증강 기법을 적용합니다. 여기에는 랜덤 크기 조정 후 자르기, 랜덤 수평 반전, -10°에서 10° 사이의 랜덤 회전, 그리고 밝기, 선명도, 대비 변화를 포함한 랜덤 그레이스케일 변환이 포함됩니다.
텍스트 전처리 과정에서는 방사선 보고서에 포함된 의학 용어를 효과적으로 추출하고 정리하기 위해 ScispaCy 도구를 활용합니다. 이를 통해 보고서에서 개체(entity)를 추출한 후, 해당 개체를 UMLS 지식베이스와 연결하여 의미를 명확히 합니다. 방사선 보고서에서는 동일한 개념이 다양한 형태(비표준 용어, 약어, 철자 오류 등)로 나타날 수 있기 때문에, 이러한 과정을 통해 모델이 보다 체계적인 정보를 학습할 수 있도록 합니다. 이후 RadGraph를 활용하여 추출된 개체의 의미 유형(semantic type)과 불확실성 수준(uncertainty level)을 분석하며, 최종적으로 모델 입력을 구성할 때 개체와 해당 속성을 {pleural effusion, observation definitely present, [SEP], lung, anatomy, [SEP], ...}와 같은 형태로 정리합니다. 이때, 모델의 효율적인 학습을 위해 최대 시퀀스 길이는 256으로 제한합니다.
한편, 특정 임상 데이터를 활용하여 모델을 미세 조정(fine-tuning)할 때에도 사전 학습 단계에서 사용한 데이터 전처리 전략을 동일하게 적용합니다. 이를 통해 사전 학습에서 익힌 지식을 유지하면서도 새로운 데이터에 대한 적응력을 높일 수 있습니다. 이러한 일관된 전처리 과정을 거침으로써, 모델이 다양한 임상 데이터에 대해 보다 효과적으로 학습하고 일반화할 수 있도록 합니다.
알고리즘은 의료 분야의 사전 지식을 활용하여 기초 모델을 학습하는 것을 핵심입니다. 이를 위해 Unified Medical Language System(UMLS)이라는 정립된 의료 지식 그래프를 활용하며, 의료 정보를 효과적으로 추출하기 위해 휴리스틱 규칙(heuristic rules), RadGraph, ChatGPT 등의 다양한 방법을 적용합니다.
모델 학습은 크게 두 단계로 구성됩니다. 첫 번째 단계에서는 의료 지식베이스의 신경 표현(neural representation)을 학습하는 지식 인코더(knowledge encoder)를 훈련합니다. 두 번째 단계에서는 방사선 보고서에서 임상 개체(clinical entities)와 그 관계를 추출한 후, 사전 학습된 지식 인코더를 활용하여 흉부 X-ray 이미지와 텍스트 쌍의 시각적 표현 학습을 효과적으로 수행할 수 있도록 합니다.
다음으로 전문가 지식에 의존하는 의료 이미지 데이터 분석에서 KAD는 지식 그래프의 신경망 표현을 학습하여 의료 엔터티 간의 암묵적인 관계를 텍스트 임베딩 공간에서 포착하고, 이를 통해 모델의 일반화 능력을 향상시켰습니다. 또한 KAD는 주의(attention) 맵을 출력하여 모델의 의사결정 과정을 시각적으로 보여줌으로써, 임상의들이 모델의 예측을 확인하도록 합니다.