논문 게시일 : 2019.02.04
논문 링크 : https://ieeexplore.ieee.org/document/8633930
논문 리뷰 작성일 : 2025.02.11
논문 리뷰에 앞서 본 논문을 이해가 하기 위해서는 다음과 같은 용어를 미리 알고 있어야 합니다.
registration : 서로 다른 두 개 이상의 이미지를 매칭시키는 기법, Linear와 non-linear한 방법이 존재
deformable(non-linear) registration) : 단순히 평행이동/대칭이동하는 것이 아니라, 각각의 점을 비선형적으로 변형하여 정렬하는 것
voxel : 3차원 공간에서의 Pixel을 의미 (Volume + Pixel), 즉 3차원 이미지에서의 최소 단위
morph: 변한다는 의미를 가진 영단어
Abstract
voxelmorph는 의료 영상 정합을 위한 fast learning-based framework 입니다.
voxelmorph는 아래와 같은 학습 전략을 가지고 있습니다.
1. unsurpervised learning(비지도 학습)
이미지 강도를 기반으로 한 objective function을 사용하여 최적화합니다.
* 이때 unsupervised learning은 라벨 없이 데이터를 학습하는 방식, 즉 주어진 데이터에서 숨겨진 패턴이나 구조를 찾아내는 방식을 말합니다. (입력 데이터만 제공되는 형식)
2. Auxiliary segmentation을 활용한 성능 향상
보조 분할을 활용하여 학습된 VoxelMorph 모델이 정합 정확도를 향상시킵니다.
Introduction
Deformable Registration은 3D MR 뇌 스캔과 같은 이미지의 비선형적인 대응관계를 설정하는 작업으로, 의료 영상을 연구할 때 있어 매우 중요한 과제이며 지난 수십 년간 활발히 연구되어 왔습니다.
기존의 Deformable Registration은 각각의 이미지 쌍마다 최적화를 해 정합을 수행하는데 이때 비슷한 voxel를 정렬하며 제약 조건을 적용해는 방법입니다. 그러나 이 방법은 계산 비용이 크고, 속도가 느리다는 단점이 있습니다.
이에 연구팀은 딥러닝을 이용하여 Registration을 학습하는 방법을 제안하였습니다.
이는 기존의 개별 이미지 쌍의 최적화 방식과 달리, 전체 데이터 셋을 학습해 하나의 Registration function을 만들고 이를 이용하는 방식입니다. 즉, 학습 단계에서 global function 최적화를 수행하여 비용을 줄였습니다.
이를 global framework인 VoxleMorph 모델로 구현하였으며, 아래와 같은 링크에서 확인해 볼 수 있습니다.
https://github.com/voxelmorph/voxelmorph.
Voxel Morph은 unsupervised learning과 해부학적 구조(segmentation)를 활용한 학습 방식을 가지고 더욱 정확한 registration을 수행합니다. 기존의 방식에 비해 비슷한 정확도를 가지면서도 속도는 매우 빠릅니다.
Background
registration의 핵심 목표는 원본 영상을 변형하여 기준 영상과 최대한 정렬되도록 만드는 것인데, 의료에서는 registration을 통해 환자 간 차이, 질병에 따른 변화 등을 정확히 비교할 수 있기에 사용된다.
VoxelMorph에서 정합은 두 단계를 거쳐 진행되는데, Global Alignment(Affine transformation) 먼저 수행한 후, Nonlinear Alignment(Deformable Transformation)이 진행됩니다.
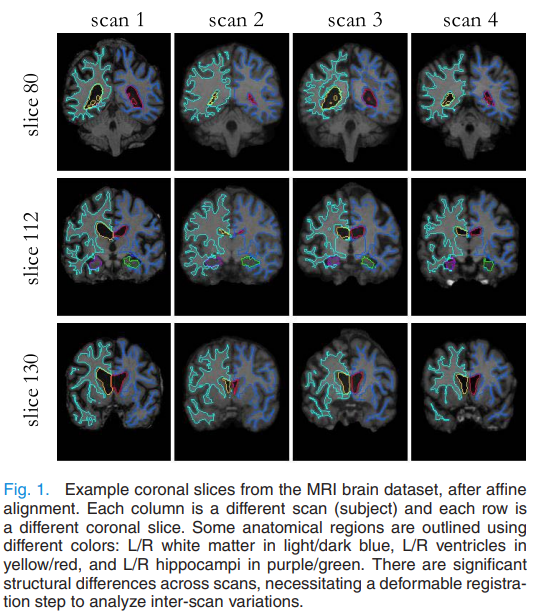
위 그림은 affine alignment만 진행했을 때 서로 다른 뇌 mri를 비교하기 어렵다는 것을 보여주는 예시로, deformable registration이 필요함을 보여줍니다.
Deformable Registraion의 최적화 수식은 아래와 같습니다.

여기서 f는 기준이 되는 fixed image, m은 moving image, phi는 registration field(f의 좌표를 m의 좌표로 매핑하는 함수)를 의미합니다.
registration의 목표는 손실 함수 L을 최소화하는 phi를 찾는 것으로 L은 변형된 영상이 원본과 얼마나 유사한지 평가합니다. 손실 함수는 similarity loss term과 regularization term으로 구성되어 있습니다. similarity loss는 변형된 m이 f와 얼마나 유사한지 평가하고, regularization term은 변형이 자연스럽고 연속적으로 이루어지게 하는 역할입니다.
VoxelMorph의 변형필드 phi는 displacement vector field로 각 복셀마다 어느 방향으로 이동해야 하는지를 벡터로써 표현합니다.
Method
앞에서 언급했던 f, m은 n차원 공간에서 정의된 영상 볼륨이며, 논문에서는 n=3 인 MRI, CT 등을 중심으로 설명하고 있습니다. VoxelMorph는 CNN을 이용하여 변형 필드를 예측합니다.
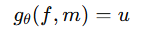
g_theta는 CNN을 의미하며, 입력받은 f, m을 변형 필드 u를 계산합니다. 이때 theta는 CNN의 학습가능 가중치를 의미합니다. u는 displacement field로 u는 n+1 텐서로 저장됙, 최종 변형 필드인 phi는 항등 변환과 u를 더한 ϕ=Id+u 꼴입니다.
theta는 Stochastic Gradient Descent, SGD를 사용해 손실함수를 최소화하는 최적의 값을 얻어냅니다.

위 그림은 voxelmorph 방식을 간단히 나타낸 것으로, 1. m과 f을 입력, 2. CNN gθ(f,m)을 이용하여 registration field인 phi 생성, 3. phi를 spatial transform 에 적용하여 m을 f에 맞게 변형, 4. loss function을 통해 와 의 유사성을 평가하여 학습 순으로 진행됩니다. 여기에 파란 박스의 보조 정보를 활용하는 방식도 포함하여 성능을 향상시킵니다.
A. VoxelMorph CNN Architecture
voxelmorph는 UNet 기반의 CNN을 사용하여 변형 필드 phi를 예측합니다.

UNet은 Encoder와 Decoder로 구성되며, Skip Conncetion을 포함합니다. Encoder는 해상도를 줄여 특징을 추출하는 역할을 하고, Upsampling으로 해상도를 복원하는 것은 Decoder의 역할입니다. 즉, Encoder는 3D 합성곱을 사용하여 특징을 추출하는데, 각 레이어에서 공간 크기를 절반으로 줄이는 식의 방법을 이용합니다. Decoder에서는 Skip connection을 사용해 Encoder의 정보를 Decoder로 직접 전달하도록 하여 고해상도를 유지하면서 정확도를 향상할 수 있도록 합니다.
B. Spatial Transformation Function
voxelmorph는 CNN이 예측한 변형필드 phi를 적용하여 m을 변형하는 과정을 수행하는데, 이때 Interpolatable 변환 방식을 사용해야 학습이 가능합니다. Voxel은 Spatial Transformation Network(STN)을 차용하여 m을 phi에 따라 변형하는데 식은 아래와 같습니다.

p는 변형 후의 좌표, p'은 변형 전의 좌표로 p+u(p)로 표현됩니다. Z(p')은 p'에 가장 가까운 8개의 정수 좌표 복셀을 의미합니다. 결론적으로, 이미지 값들은 정수 위치에서만 정의되기 때문에 p의 복셀 값은 p' 주변 8개의 복셀 값들을 선형 보간하여 계산됩니다. (변형필드를 거친 p'은 실수 값일 수도 있기에)
C. Loss Functions
1) Unsupervised Loss Function
voxelmorph는 의료 영상 정합을 위해 unsupervised learning 기반 손실함수를 사용하며, 손실함수는 아래와 같이 정의됩니다. 앞서 언급했듯 L_sim은 유사성 손실, 즉 변형된 이미지가 f와 얼마나 유사한지를 평가하는 항(이미지 intensity 최소화)이고, L_smooth는 변형 필드 phi가 급격하게 변하는 것을 방지합니다.
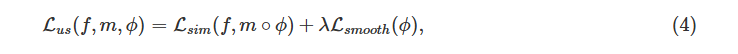
voxelmorph에서는 유사성 손실(L_sim)을 측정하기 위해 평균제곱오차인 MSE을 주로 사용하며, 식은 아래와 같습니다.

그러나 MSE는 강도 분포가 다르면 사용하기 어렵기에, Local Cross-Correlation 방법을 사용합니다. CC 방법은 다양한 강도 변화를 가지는 데이터셋에 유리합니다.
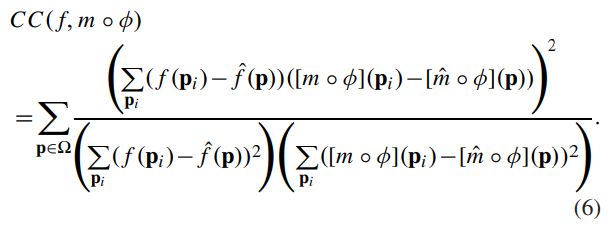
CC 공식은 위와 같이 정의되며, 분자는 f와 m∘ϕ의 강도 차이 간의 공분산이고 분모는 각각의 분산의 곱입니다. CC 값이 클 수록 두 영상이 잘 정렬되는 것을 의미합니다.
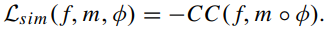
CC가 커질 수록 잘 정렬되는 것을 의미하므로 - 를 붙여 위와 같이 L_sim 이 표현됩니다.
L_smooth는 아래와 같이 표현됩니다.
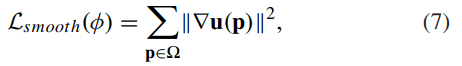
u(p)는 변위 벡터 필드를 의미하며, 변위 벡터의 gradient를 최소화하여 부드러운 변형을 유도하는 것을 목표로 하기에 위와 같은 식으로 표현됨을 알 수 있습니다.
2) Auxiliary Data Loss Function
추가적으로 해부학적 분할 정보를 활용하며 registration 성능을 더욱 향상시킬 수 있습니다. voxelmorph는 훈련할 때에만 auxiliary segmentation을 활용하여 모델의 정확도를 높이는 방법이 사용되었습니다.
만약 registration이 정확하다면, m의 분할 영역이 f의 분할 영역과 잘 겹쳐져야 합니다. 이러한 영역들의 overlap 정도를 측정하는 지표로 Dice Score을 사용하였습니다. Dice Score 공식은 아래와 같습니다.

sfk는 f에서 특정 구조 k에 속하는 복셀, skm은 m에서의 복셀, 분자는 두 구조가 겹치는 영역의 크기, 분모는 두 구조의 총 크기를 의미합니다. 즉, 이 값이 1에 가까우면 최적으로 registration된 상태이며, 0이면 겹치는 부분이 전혀 없음을 의미합니다. L_seg는 Dice Score가 높을 수록 registration이 잘 된 것이므로 -을 붙여 아래와 같이 표현됩니다.

1)과 2)를 함께 표현하면 아래와 같습니다.
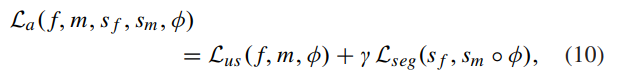
즉, 기존 손실에 보조 정보를 추가하여 더욱 정밀한 registration이 가능하도록 합니다.
D. Amortized Optimization Interpretation
voxelmorph는 기존의 pair-specific optimization을 global optimation으로 대체하는 방식으로 이를 amortized optimization이라 합니다. voxelmorph는 신경망 gθ(f,m)을 학습하여 변형 필드를 직접 예측합니다. 즉, 전체 데이터셋을 학습하여 공통된 최적화 모델를 생성하는 것이기에 기존보다 훨씬 빠른 속도를 지닙니다. 이는 전체를 학습하기에 자연스럽게 정규화 효과를 제공합니다. 최적 변형 필드의 근사값을 생성하는 것이게 최적 변형 필드와의 Amortization Gap이 생길 수 있으나, 이를 보완하기 위해 instance-specific optimization을 진행할 수 있다.
Experiments
본 논문에서는 다양한 실험을 통해 registration의 성능을 평가하였습니다.
A. Experimental Setup
1) dataset
3,731개의 T1-weighted brain MRI 스캔 데이터를 사용하였으며, 8개의 공개 데이터셋을 활용하였습니다. MRI는 Resampling과 Affine Normalization, Brain Extraction 등 전처리를 수행하였고, 30개 이상의 해부학적 segmentation도 이용하였습니다.
2) Evaluation Metrics
Registration된 해부학적 구조가 얼마나 일치하는지를 측정하는 Dice Score, 변형 필드의 국소적인 변화율을 측정하는 Jacobian Determinant, 실행시간 등이 평가 지표가 됩니다.
3) Baseline Methods
Baseline으로 Symmetric Normalization(SyN) (ANTs)과 NiftyReg 패키지를 사용하였습니다.
4) VoxelMorph Implimentation
Keras를 사용하여 구현하였으며, TensorFlow를 백엔드로 사용했습니다. 2D linear interpolation spatial transformer 레이어를 n-D로 확장시켰고, 여기서는 n=3을 사용하였습니다. ADAM Optimize을 적용하였고, learning rate는 10^-4로 설정하였습니다. 기본적으로 150,000회 반복을 수행하며 이는 https://github.com/voxelmorph/voxelmorph.에서 확인할 수 있습니다.
B. Atlas-Based Registration
Atlas를 기준 이미지로 설정하고, brain MRI를 아틀라스에 registration합니다. Atlas는 여러 뇌 MRI를 정렬하고 평균 내 만든 reference 영상으로 f는 아틀라스 m는 데이터셋의 개별 MRI라고 보면 됩니다. 즉 실험 B에서는 아틀라스 기반 registration이 효과적임을 확인합니다.

위 표는 voxelmorph가 ANTs 및 NiftyReg와 유사한 Dice Score를 기록하고, Affine registration만 이용했을 때보다는 훨씬 뛰어난 성능을 보인다는 것을 일러줍니다. Jacobian Determinant 분석의 경우, 대부분 differomorphic deformation을 유지하며, 변형 필드는 부드럽게 유지된다는 것을 확인해볼 수 있습니다. voxelmorph는 differomorphic deformation을 강제하지 않음에도 불구하고, smoothness loss를 통해 부드럽고 안정적인 변형결과를 얻어내는 반면, ANTs 및 NiftyReg는 differomorphic deformation을 강제하는 기능을 사용할 수는 있으나 runtime이나 결과에 부정적 영향을 받습니다.


그림 4와 6에서는 voxel morph가 적용된 변형 이미지의 예시를 찾아볼 수 있습니다.
Runtime 역시 표1에서 확인해볼 수 있습니다. 결론적으로, voxelMorph는 CPU에서 ANTs보다 평균적으로 150배 빠르고, NiftyReg보다 40배 빠르며, GPU를 사용할 경우 VoxelMorph는 1초 미만의 실행 시간으로 정합을 완료할 수 있다는 것을 확인할 수 있습니다. VoxelMorph의 가장 큰 장점은 테스트 이미지 쌍마다 최적화를 수행할 필요가 없다는 점입니다. 이는 CPU 실행 시간 비교에서 더욱 두드러지게 나타납니다.
C. Regularization Analysis
이 실험에서는 dice score의 변화 양상을 기준으로 정규화 파라미터 lambda 값이 voxelmorph의 성능에 미치는 영향을 분석합니다. 이때, lambda는 phi의 smooth를 조절하는 정규화 파라미터입니다.

왼쪽의 그래프는 MSE 모델, 오른쪽의 그래프는 CC 모델의 lambda에 따른 Dice score 변화입니다. 이를 통해 = 0 (정규화 없음)에서도 Affine 정렬보다 높은 Dice Score 달성함을 알 수 있으며, 적절한 lambda값을 설정하면 성능이 향상하지만 너무 큰 값은 저하시킬 수도 있음을 확인해볼 수 있습니다.
D. Training Set Size and Intance-Specific Optimization
이 실험에서는 훈련 데이터의 크기가 성능에 미치는 영향과 개별 이미지 쌍에 대한 intance-specifc optimization의 효과를 분석합니다.

데이터의 크기를 달리하며 총 세 가지 경우의 dice score을 비교하였습니다. Training set, Test set, Instance-Specific Optimization 수행 후의 세 경우에 관해 실험을 진행한 결과 우선 훈련 데이터의 크기가 증가할 수록 성능은 향상함을 알 수 있습니다. 이때 확인해볼 점은 100개 이상의 데이터만으로도 충분히 일반화가 가능하다는 것입니다.
또, instance-specific optimization을 진행하면 ANTs 수준으로 성능이 더 향상되는 것을 확인해볼 수 있습니다.
E. Manual Anatomical Delineations
이전 실험에서는 FreeSufer(자동 segmentation)을 이용해 성능을 평가했다면, 실험 E에서는 전문가가 직접 수행한 수동 분할 데이터셋인 Buckner40을 사용하여 성능을 평가하였습니다.
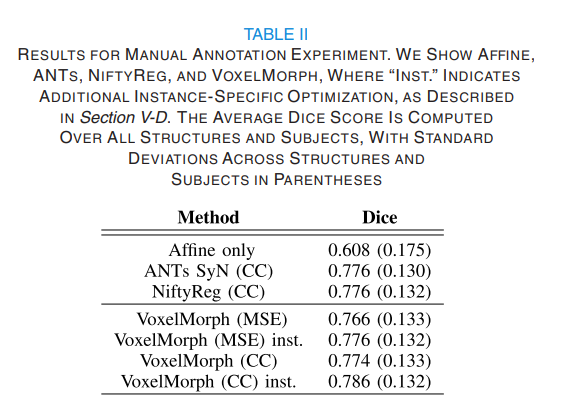
CC는 기존의 ANTs, NiftyReg와 유사한 성능을 보여줍니다. MSE도 추가 최적화를 수행하면 성능을 향상시킬 수 있으며, CC+inst가 가장 높은 성능인 0.786을 기록했다는 것을 확인해볼 수 있습니다.
F. Subject-to-Subject Registration
이전 실험에서는 Atlas-Based Registration을 수행하였으나, 실험 F에서는 subject-to-subject registration을 수행하여 더 어려운 변형 문제를 해결할 수 있는지를 평가합니다. 피험자 간 변형은 각 객인의 해부학적 차이가 크기 때문에 더 복잡한 registration이 필요하므로, feature의 개수를 증가시켜 성능을 개선하여 진행하였습니다.

CC가 MSE보다 더 우수한 성능을 제공함을 알 수 있습니다. 또, feature의 개수를 증가하면 성능이 향상되며, 앞선 실험들과 동일하게 instance-specific optimization을 수행하면 ANTs 와 NiftyReg 수준으로 성능이 향상되는 것 또한 확인해볼 수 있습니다.
G. Registration With Auxiliary Data
이 실험에서는 auxiliary segmentation maps을 활용하여 voxelmorph의 성능을 향상시키는 방법을 평가합니다.

상단의 그래프들은 FreeSurfer 자동 분할을 사용하여 실험을 진행한 것이고, 하단의 그래프들은 Buckner40, 즉 전문가들이 수동분할한 데이터셋에서 진행한 실험입니다. gamma는 보조 데이터의 영향을 조절하는 파라미터로 0이면 보조데이터 없이, ∞는 보조 데이터만으로 학습한 모델입니다. 그래프를 분석해보았을 때 gamma 값을 적절히 설정하면, 보조 데이터 활용을 통해 정합 성능을 향상시킬 수 있음을 파악할 수 있습니다.
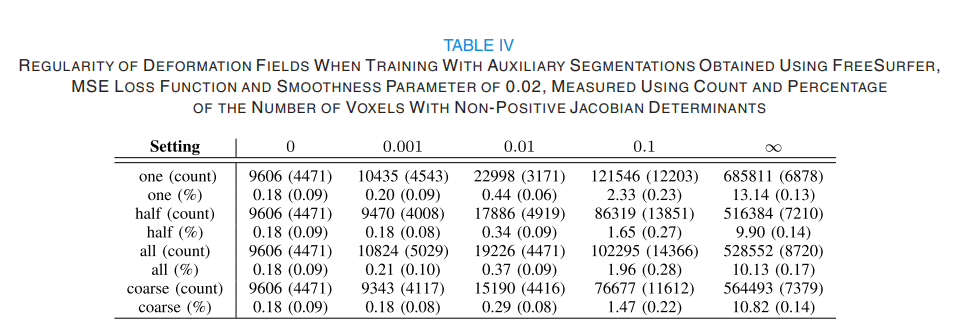
jacobian determinant를 분석 지표로 사용하여 변형 필드의 정규성을 분석해본 결과 gamma 값이 너무 크면 변형 필드가 비정상적으로 변형됨을 알 수 있습니다. 즉, 정도가 최적의 균형 유지한다는 것을 파악할 수 있습니다.
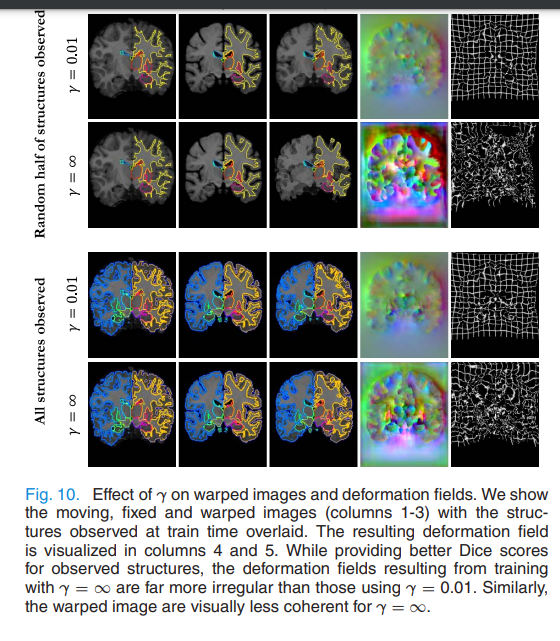
변형 필드를 시각적으로 비교한 이미지이며, 보조 데이터 활용 시 γ\gamma 값을 적절히 조정해야 안정적인 변형 필드를 얻을 수 있다는 것을 파악할 수 있습니다.
Discussion and Conclusion
여러 실험을 통해 voxelmorph는 기존 알고리즘과 동등한 성능을 보이면서도, 150배 이상 빠른 속도를 제공한다는 것을 알 수 있었습니다. Amortized Optimization을 통해 바로 registration이 가능하며, instance-specific optimization을 통해 추가적인 정밀 registration이 가능하고, auxiliary segementation data를 활용하면 성능을 향상시킬 수 있음을 파악하였습니다. 이러한 voxelmorph는 다양한 의료 영상 registration 문제에 적용하거나, loss function을 mutual information으로 변경하면 multi-modal로 registration 하는 식으로 확장해 볼 수 있습니다.