논문 제목:The false hope of current approaches to explainable artificial intelligence in health care
출판 연도: 2021
저자: Marzyeh Ghassemi, Luke Oakden-Rayner, Andrew L Beam
저널명: The Lancet Digital Health
피인용 수 (Google Scholar 기준): 888회
DOI: 10.1016/S2589-7500(21)00208-9
논문리뷰 작성일: 2024.02.08
01. Preview
AI가 의료 분야에 본격적으로 도입되면서, 많은 연구자와 임상의들이 AI 모델의 설명 가능성(Explainability)에 관심을 갖기 시작했다. AI의 '블랙박스' 특성이 불안하다는 이유로, 모델이 왜 특정 결정을 내렸는지를 설명해야 한다는 요구가 거세지고 있다.
해당 paper는 특정 아키텍처를 다루거나 실험한 결과가 아니라, review paper에 가깝기 때문에 줄글로 설명하겠다.
02. 설명 가능한 XAI에 대한 과한 기대
일반적으로 XAI가 필요한 이유로는 다음과 같이 이야기한다.
- 의료진이 AI의 결정 과정을 이해하고 신뢰할 수 있도록 한다.
- 모델의 결정을 설명함으로써 환자에게 보다 투명한 진료를 제공한다.
하지만 논문에서는 이러한 기대가 실제로 충족되지 않을 가능성이 크다고 주장한다. XAI는 개별적인 의료 의사결정 상황에서 신뢰할 만한 정보를 제공하지 못하며, 오히려 인간이 AI를 과신하게 만들거나 잘못된 확증 편향을 유발할 수 있다는 것이다. 즉, XAI가 모델이 어떻게 결정을 내렸는지에 대한 '겉보기' 설명만 제공할 뿐, 실제로 AI가 정확한 판단을 내렸는지를 보장하지 않는다는 점이 핵심이다.
03. 현재 XAI들의 한계
3-1. Heatmap
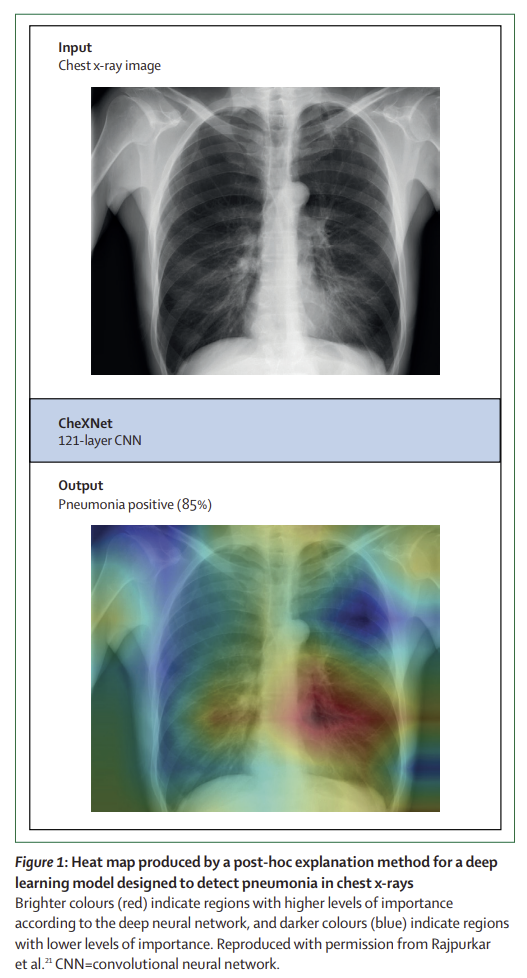
히트맵은 의료 영상 AI에서 많이 사용되는 기법으로, 모델이 특정 예측을 할 때 중요하게 여긴 영역을 시각적으로 강조하는 방식이다. 하지만 논문에서는 히트맵이 다음과 같은 문제점을 가진다고 설명한다.
- 모델이 어디를 '보고 있는지'는 알 수 있지만, 실제로 어떤 특징을 기반으로 판단했는지는 알 수 없다.
- 사람들은 히트맵이 강조하는 영역을 보고 모델이 '올바른 특징'을 사용했다고 착각할 가능성이 크다.
3-2. LIME(Locally Interpretable Model-Agnostic Explanations) & SHAP(Shapley Values)
LIME과 SHAP는 AI가 특정 예측을 내릴 때 개별 요소가 결과에 미친 영향을 분석하는 기법이다. 하지만 이 방식도 다음과 같은 한계를 가진다.
- 설명 결과가 상황에 따라 다르게 나올 수 있어 일관성이 부족하다.
- 설명이 잘못된 방향으로 해석될 위험이 있다.
3-3. Prototypical Explanations
프로토타입 기반 설명은 AI가 특정 질병을 판단할 때 '대표적인 패턴'을 학습해 이를 기준으로 예측 결과를 설명하는 방식이다. 하지만 이 기법 역시 문제가 있다.
- AI가 선택한 프로토타입이 정말 의료적으로 의미 있는지 검증하기 어렵고
- 모델이 적절한 패턴을 학습했는지 판단하는 것은 결국 사람이 해야 하며, 이는 새로운 오류를 발생시킬 가능성이 존자한다.
그렇다면 이쯤까지 글을 읽으면 XAI는 아에 필요가 없는가? 라는 의문이 든다.
04. What are explanation for
논문에서는 XAI가 개별 환자의 예측을 신뢰할 수 있도록 돕는 역할보다는, 모델의 전반적인 특성을 파악하는 도구로 사용될 때 유용할 수 있다고 설명한다.
- Audit: 모델이 잘못된 패턴을 학습했는지 점검하는 용도로 활용 가능.
- Knowledge Discovery: XAI를 활용하여 AI가 예측에 사용한 중요한 의료적 특징을 발견하는 데 기여
05. Relevance to Our Work
논문이 지적하듯, 현재의 XAI 기법들은 개별 환자의 예측을 검증하는 데 있어서 충분한 신뢰성을 제공하지 못한다. 오히려 XAI가 불완전한 설명을 제시하면서 AI를 과신하도록 유도하거나, 모델의 실제 성능을 저하시킬 위험이 있다는 점이 주요한 문제로 지적된다. 의료 data 생성하는 우리 연구과 관련지어서 생각해봤다.
Synthetic Data 생성에서도 동일한 XAI의 한계가 있을 것으로 예상된다. Diffusion 모델이 생성한 의료 영상을 분석할 때, 히트맵을 활용해 어떤 특징이 모델에 의해 강조되었는지를 시각적으로 확인할 수 있다. 하지만 논문에서 언급한 바와 같이, 히트맵은 단순히 '어디를 보고 있는지'를 보여줄 뿐, '무엇을 학습했는지'를 설명하지 못하는 한계가 있다.
논문이 주장하는 핵심은 설명 가능성보다 성능 검증이 더 중요하다는 점이다. 따라서 Synthetic Data 를 생성하는 우리 연구에서는 XAI보다는 생성된 데이터의 품질을 잘 평가할 수 있는 metric를 찾는 것이 좋은 방향이라고 생각이 든다.