
논문 제목: High-Resolution Image Synthesis with Latent Diffusion Models
출판 연도: 2022년
저자: Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
원본 논문 링크 : https://arxiv.org/abs/2112.10752
High-Resolution Image Synthesis with Latent Diffusion Models
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism t
arxiv.org
1. Introduction
최근 이미지 합성 분야는 급격한 발전을 이루었지만, 높은 계산 비용(computational demands)이 여전히 큰 문제로 남아 있습니다. 특히, 오토리그레시브(AR) 모델은 수십억 개의 parameters(변수)를 필요로 하며, GAN은 복잡한 variability, 즉 multi-modal distributions 학습하는 데 한계를 보입니다. 이에 반해, Hierarchy of denoising autoencoders로 구축된 Diffusion Models (DM)은 좋은 생성 능력을 보이며 이미지 synthesis 기술의 state-of-the-art로 자리 잡았으나, High-Resoultion Image의 경우 여전히 높은 계산 비용이 요구됩니다.
이해를 위해 Diffusion과 DDPM에 대해 간단히 알아보도록 하겠습니다.
Diffusion
여러분들이 흔히 아시는 확산입니다.
물 속에서 특정 물질이 서서히 퍼지는 것을 의미하는데, 만약 퍼지는 timestep을 알고 있다면, 그것을 역으로 재생시키면 기존의 상태로 돌아올 수 있지 않을까 하는 개념을 여기서 이해해주시면 될거 같습니다.
DDPM
고양이가 선명하게 보이는 원본 데이터에서 점차 노이즈를 추가해 가면서 마지막에는 완벽한 노이즈 이미지를 만드는 Forward Process로 먼저 진행이 됩니다. 다음으로 추가했던 노이즈 이미지를 다시 원 상태로 되돌리는 Reverse Process로 학습을 하게 됩니다.

Forward process에서 Gaussian 분포(정규분포)로 noise를 추가하는 과정이 있는데, Markov Chain을 통해 점차 noise를 더합니다. 여기서 Markov Chain이란 것은 미래를 생각하지 않고 현 상태에서 다음 상태를 예측하는 확률이라고 합니다. 그래서 코드 프로세스에서 수식을 보게 되면 t-1, 즉 이전 상태를 기준으로 했을 때 Xt 확률 분포를 나타내는 함수입니다. Reverse process는 추가된 노이즈를 다시 원상 복구하는 과정에서 데이터 특성의 분포를 학습시키는 과정입니다.
아래의 식을 보시면 위의 forward process에서의 t와 t-1의 위치가 바뀐 것을 확인하실 수 있습니다.
또 reverse process에서는 노이즈 생성 확률 분포 parameter인 평균과 표준편차를 업데이트하면서 학습을 진행합니다.
이 Diffusion Model의 문제점은 기존의 DM이 감지할 수 없는 데이터의 Detail까지도 모델링을 하기 때문에 과도한 양의 recources를 소비하게 됩니다.
DDPM에서는 reweighted variational objective(재가중된 변분 목적함수)를 통해 초기 노이즈 제거 단계에서 적게 샘플링(복원)하는 방법으로 문제를 해결했으나 RGB 이미지 고차원 공간에서 gradient 계산이 반복적으로 필요합니다. 즉 계산량이 많아지는 문제가 발생합니다.
본 논문에서는 DM의 학습과 샘플링 두 가지 모두 계산량을 줄이는 것에 중점을 두었습니다.
Idea

Perceptual Compression은 세부적인 pixel은 제거 하지만 semantic 정보는 학습하지 않는 단계입니다. 위의 그림을 보시면 rate가 높아질 수록 고화질의 이미지가 생성 된다고 보시면 됩니다. rate가 변하더라도 선글라스를 쓴 남성의 사진이라는 것을 인지하는데 어려움은 없습니다.
다음으로 Semantic compression이 있습니다. Semantic compression은 semantic 정보와 conceptrual 정보를 학습하는데 이것을 실제 생성 모델에서 하는 것입니다. 위의 그림에서 rate가 변화함에 따라 왜곡이 크게 발생하는 것을 확인할 수 있습니다.
이것은 의미론적인 정보를 이 과정에서 학습하기 때문입니다.
본 논문에서는 기존의 DM의 경우 Perceptual compression 과정이 오래 걸리는 것을 개선하기 위해 perceptual 하게 동등하지만 low dimensional space에서 계산할 수 있는 space를 탐색하여 고해상도 이미지 합성을 적은 계산량으로 학습하는 것을 목표라고 하였습니다.
기존 모델 VS LDM

Input 이미지와 LDM, DALL-E, VQGAN을 비교했을 때, 논문에서 소개하는 LDM의 결과가 Input과 가장 유사한 것을 알 수 있습니다.
Diffusion Model VS Latent Diffusion Model
기존의 DM은 고차원 데이터 공간인 pixel space에서 반복적으로 손실을 계산하고 gradient를 업데이트 해야해서 계산량이 많았습니다. 위의 왼쪽 그림에 있는 DM의 간단한 architecture를 보시면 원본 이미지가 들어왔을 때 이것을 그대로 DM이 학습을 진행하는 것이 아니라 원본 이미지를 압축해서 정보를 넣게 됩니다. Perceptual 압축 과정에서 시간도 오래 걸리고 세부 정보의 손실이 발생하게 됩니다.
이것을 LDM에서는 Autoencoder로 Perceptual Compression을 진행한 뒤, Semantic Compression을 Diffusion으로 넘깁니다. autoencoder가 Perceptual Compression만 진행하고 세부사항이 사라진 후 semantic이 남아있는 정보를 학습합니다. Semantic은 남아있기 때문에 이미지의 Inductive Bias는 학습 가능하다고 합니다.
DDPM과 같은 일반적인 모델을 Pixel Space Model이라 하고, Autoencoder를 사용해서 compression을 하는 모들엘 Latent Space Model이라고 합니다.
2. Method

2.1 Perceptual Image Compression
perceptual loss, patch-based adversarial objective를 결합해서 autoencoder를 구성합니다.
perceptual loss는 사람의 눈에 자연스러워 보이는지를 기준으로 이미지의 유사성을 평가하는 것인데 High level Feature Preservation을 위한 것입니다.
Patch-based adversarial objective는 patch단위로 세밀하게 평가를 진행 해서 이미지의 사실성을 높이게 됩니다. perceptual loss와 달리 low level feature preservation을 위한 것입니다.

이 두가지를 결합한 autoencoder가 LDM architecture에서 encoder와 decoder 부분입니다. 이미지를 입력하면 downsampling (압축 비율은 downsampling factor f로 표현함) 을 통해 encoder를 거쳐서 latent space에서 diffusion model을 학습하게 되고 이 latent embedding이 다시 decoder를 통해 원본 이미지로 복원하는 과정을 거칩니다.
KL, VQ 정규화
latent space의 과도한 변동을 막기 위해 정규화(regularization)를 사용합니다. KL-reg는 압축을 하되, latent space에서 불규칙과 같은 불완전성을 막기 위해 분포를 연속적이고 표준 정규분포(평균0, 분산1)로 유지하는 모델을 학습합니다.
VQ-reg는 벡터 양자화(Vector Quantization) layer를 Decoder 내부에 사용해 다양한 특성을 몇 가지 중요한 특징으로 요약하고 구체적인 패턴을 잘 추출할 수 있게 합니다.
2.2 Diffusion model vs Latent Diffusion Model
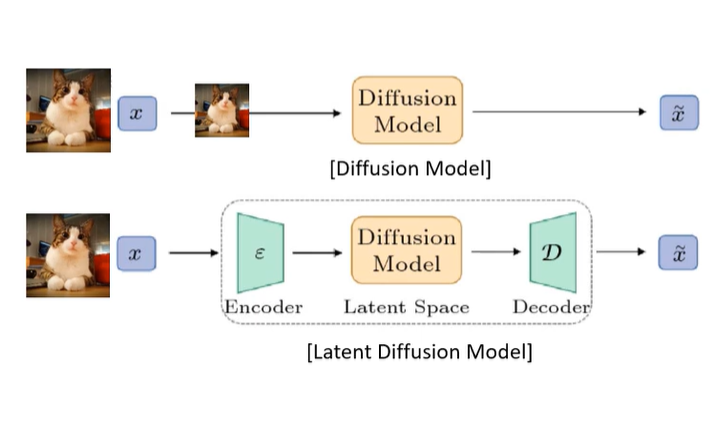
기존의 diffusion model의 경우 정규 분포 변수의 noise를 점차 제거해서 데이터 분포를 학습하는 모델입니다.
Latent Diffusion Model은 미리 학습한 Autoencoder를 이용해 latent space에서 diffusion을 진행합니다.
likelihood 기반의 생성 모델에 더 적합하다고 합니다.
데이터의 중요한 semantic 정보에 더 집중해서 latent space에서 데이터의 중요한 구조적 정보를 나타낼 수 있습니다. 또한 latent space가 low dimensional space여서 효율적인 계산이 가능합니다.

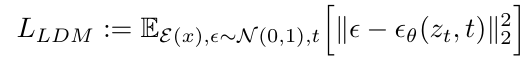
두 Object funtion을 보면, Xt가 Zt로 바뀐 것을 확인할 수 있습니다.
3. Experiments

얼굴 데이터셋, 교회, 침실, 이미지넷이 있습니다. Unconditional 환경에서 기존의 모델과 LDM의 이미지 생성(복원)을 비교해 보겠습니다.

*FID (Frechet Inception Distance): 생성된 이미지와 실제 이미지의 차이를 측정하는 지표 (낮을 수록 유사)
*Precision (정확도): 생성된 이미지 중 실제 데이터와 얼마나 일치하는지를 나타내는 지표 (높을 수록 일치)
*Recall (재현율): 실제 데이터의 특성을 생성된 이미지가 얼마나 잘 포괄하는지 나타내는 지표 (높을 수록 유사)
기존의 다양한 모델과 비교 했을 때 LDM-4가 좋은 성과를 보여주고 있다는 것을 알 수 있습니다.
다음으로 Conditional Latent Diffusion 성능을 비교하기 위해 Text Conditional Image Synthesis를 기존의 모델과 비교해보겠습니다.

*IS (Inception Score): 생성된 이미지가 다양한 클래스에 걸쳐 있는지, 각 이미지가 특정 클래스에 속하는 명확한 정보를 제공하는지를 측정하는 지표 (높을 수록 명확)
FID와 IS를 비교했을 때, LDM의 성능이 다른 모델들에 비해 가장 좋은 것은 아니지만 괜찮은 성능을 보여주고 있습니다. 하지만 이 부분에서 주목해야 하실 부분은 parameter의 수인 Nparams를 살펴봐야합니다. 다른 모델들을 보시면 40억개, 60억개가 되지만, LDM의 경우 14.5억 개로 매우 압도적으로 낮은 paramerter 수를 보여주고 있습니다.
Text conditional image synthesis에서도 LDM의 성능이 탁월한 것을 실험을 통해 알 수 있습니다.

위의 이미지는 LDM-8이 Text만으로도 현실에 존재하지 않는 이미지를 잘 구현한다는 것을 알 수 있습니다. 하지만 첫 번째 이미지와 마지막 이미지 같은 경우 문자가 있는데, 스펠링이 맞지 않는 것을 볼 수 있습니다. 글자 부분은 아직 취약하다는 것을 이 실험에서 알 수 있습니다.


왼쪽의 그림은 lay-out만 주어진 상황에서도 LDM의 이미지 합성이 잘 진행된 모습을 확인 할 수 있습니다.
오른쪽 그림은 semantic과 영역만 주어진 상황에서도 이미지 합성이 잘 된 것을 볼 수 있습니다.

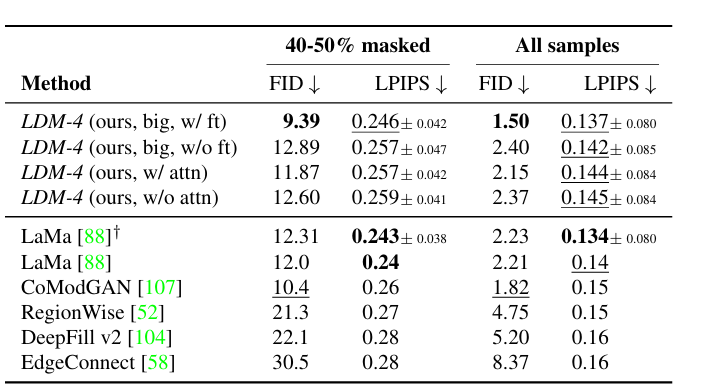
Inpainting은 이미지에서 특정 영역을 masking 후 새로운 내용으로 채우는 기법입니다. 이를 통해 미완성된 이미지의 빈 공간을 보완하거나, 기존의 물체를 제거한 뒤 자연스럽게 주변과 어우러지도록 만들 수 있습니다. 위 그림은 특정 객체를 제거하는 과정을 적용한 예시입니다.
위의 table 비교를 통해서 LDM의 성능이 Inpainting에서도 성능이 좋다는 것을 알 수 있습니다.
4. Conclusion
기존 Diffusion Model은 세부 정도의 손실이 있었고, 계산 비용이 너무 높았습니다. LDM은 DM의 높은 계산 비용을 Latent Space에서 Autoencoder를 사용함으로써 계산 시간을 단축하였습니다. Low-dimensional space에서의 계산으로 세부 정보는 유지하면서 효율성을 높였고, multi-modal을 통해 다양한 응용 분야에서 활용 가능성이 크다는 점을 확인할 수 있었습니다.