논문 게시일: 2020.12.07
논문 원문 링크: https://translational-medicine.biomedcentral.com/articles/10.1186/s12967-020-02620-5
Predicting 30-days mortality for MIMIC-III patients with sepsis-3: a machine learning approach using XGboost - Journal of Transl
Background Sepsis is a significant cause of mortality in-hospital, especially in ICU patients. Early prediction of sepsis is essential, as prompt and appropriate treatment can improve survival outcomes. Machine learning methods are flexible prediction algo
translational-medicine.biomedcentral.com
리뷰 작성일: 2025.02.16
Background
패혈증(Sepsis)는 감염에 의해 발생하는 생리적, 병리적, 생화학적 이상 증후군으로, 중환자실에서의 30%라는 높은 사망률을 보여 매년 530만 명이상의 사망자를 발생시키는 질병입니다. 이에 패혈증을 조기에 진단하는 것은 매우 중요한 과제로 분류되어 왔으며, 현재까지 로지스틱 회귀 분석, APACHE-II, SAPS-II 등의 예측 모델이 사용되어 왔습니다. 그러나 기존의 예측 방식은 예측력이 낮고 변동성이 커, 안정성과 실용성 그리고 계산 과정이 복잡하다는 등의 문제점을 가지고 있습니다. 따라서 본 논문의 연구 팀은 eXtreme Gradient Boosting(XGBoost)이라는 머신 러닝 기법을 사용하여 패혈증 예측 모델을 만들어 내고자 하였고, 연구 목표는 아래와 같습니다.
1. XGBoost 모델을 기존 예측 모델과 비교하여 MIMIC-III 데이터베이스의 Sepsis-3 환자에서 30일 사망률을 예측하는 성능을 평가하는 것
2. XGBoost 모델을 검증하기 위해 nomogram과 Clinical Impact Curve(CIC)을 작성하는 것
Method
Database
본 연구에서는 MIMIC-III v1.4(Medical Information Mart for Intensive Care III) 데이터베이스를 사용하였습니다. MIMIC-III는 2001년부터 2012년까지의 BIDMX의 ICU에 입원한 46,520명의 환자의 의료 정보로, 허가를 받으면 사용할 수 있는 데이터입니다.
Study Population
Sepsis-3으로 진단된 성인 환자를 대상으로 하였기에 18세 이상 성인, ICU에서 24시간이상 입원한 환자, 2016년 제3차 국제 패혈증 기준에 따라 패혈증으로 진단된 환자만 포함하여 연구를 진행하였습니다. 또한, missing data가 20%이상인 변수는 분석에서 제외하는 등의 제외 기준을 세워 신뢰할 수 있는 데이터를 기반으로 연구의 정확성을 높였습니다.
Data extraction
데이터 추출은 위에서 언급한 대로 아래와 같은 과정을 거쳐 진행되었습니다

즉, 최종 분석 대상 환자는 총 4,559명이고, 이를 다시 생존 및 사망 그룹으로 분류하여 연구에 사용하였습니다.
연구를 위해 각 환자 별로 인구통계학적 정보(연령, 성별, 인종, ... 등), vital sign, 실험실에서의 검사 결과 등의 데이터를 수집하였고, 최종적으로 연구에 사용될 패혈증 환자 데이터를 확보하였습니다. 아래의 표는 이러한 데이터를 정리해서 나타낸 표 입니다.


Statistical Analysis
위의 표는 통계 분석을 마친 후의 결과값이 표현된 것으로 통계 분석은 아래와 같이 진행되었습니다.
우선 30일 이내 사망 그룹과 30일 이상 생존 그룹으로 나누고, 각각의 변수에 대해 그룹 별로 상관 분석(correlation analysis)를 수행하였습니다. 연속형 변수의 경우 정규 분포를 따르는지의 여부에 따라 평균 ± 표준편차 혹은 중앙값으로 요약하였고, t-test, ANOVA, Mann-Whitney U, Kruskal-Wallis H 검정을 사용하여 p-value을 구했습니다. 범주형 변수의 경우 숫자나 백분율로 표현하였고, 샘플의 크기에 따라 Chi-square test, Fisher's Exact test 검정을 진행하였습니다.
본 연구팀은 추출해낸 데이터들을 세 가지 예측 모델을 개발하여 비교 분석하였습니다.
로지스틱 회귀 모델의 경우 카이제곱 검정과 후방 단계 선택법(Backward Stepwise Analysis)을 이용해 유의미한 변수들만 선택하여 회귀모델을 구척하였고, p-value < 0.05인 변수만 포함하여 최종 모델을 완성하였습니다.
SAPS-II Score 모델의 경우 원본 문헌의 방법론을 기반으로 하여 time-stamp variables를 사용해 사망률을 예측하였습니다.
XGBoost 머신 러닝 모델은 각 변수의 기여도를 분석하여 30일 전후 사망률에 미치는 영향을 평가하고, 후방 단계 선택법을 사용하여 Akaike Information Criterion(AIC) 기준 p-value < 0.05인 변수만 선택하여 XGBoost 알고리즘 모델을 구축하였습니다.
모델의 성능은 다음과 같은 방식으로 비교되었습니다 ROC curve의 AUC(Area Under Curve)를 비교하고, DCA(Decision Curve Analysis)를 수행하며, Nomogram과 CIC를 작성해 모델의 임상적 유용성과 적용 가능성을 평가하였습니다.
Results
Baseline characteristic
우선 기본적인 특성을 살펴보았을 때, 패혈증 환자 중 30일 내 사망과 생존 여부를 비교한 결과 연령, 인종, 입원 유형, 평균 심박수(heartrate_mean), 최소 수축기 혈압(sysbp_min), 평균 이완기 혈압(diasbp_mean), 평균 혈압(meanbp), 최소 평균 혈압(meanbp_min), 평균 호흡수(resprate_mean), 최소 및 최대 체온(tempc_min/max), 평균 산소포화도(spo2_mean), 최소 및 최대 음이온 차이(aniongap (AG)_min/max), 최소 크레아티닌(creatinine_min), 최소 및 최대 헤모글로빈(hemoglobin_min/max), 최소 젖산 농도(lactate_min), 최소 칼륨 농도(potassium_min), 최대 나트륨 농도(sodium_max), 최소 및 최대 혈액 요소 질소(BUN_min/max), 최소/최대/평균 백혈구 수(wbc_min/max/mean), 최대 및 평균 국제 표준화 비율(INR_max/mean), 소변 배출량(urine output), 점수 시스템(score system), 동반 질환(comorbidity), 주요 감염 원인(common sources of infection) 등이 두 그룹 간 유의미한 차이를 드러냈습니다. 그러나, 성별(sex), 최소 심박수(heart rate_min), 최소 염소 농도(chloride_min), 최소 혈소판 수치(platelet_min), 최소 나트륨 농도(sodium_min), 고급 생명 유지 치료(advanced life support) 등 의 경우 두 그룹 간 차이가 유의미하지 않으며, 아래의 그림은 순서대로 환자들의 인종 분포, 주요 감염원인이 원그래프로 표현된 것입니다.

아래의 표에 나타난 것은 후방 단계 선택법을 통한 로지스틱 회귀 모델으로 30일 전후 사망률과 강한 연관성을 가져 선정된 변수입니다.
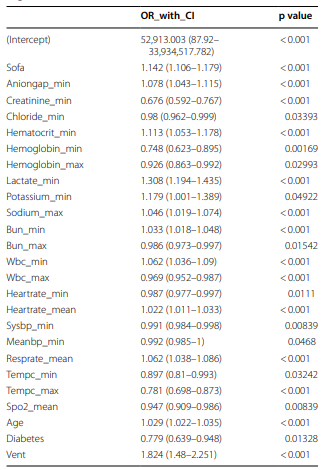
또, XGBoost 모델을 사용하여 각 변수의 기여도를 분석한 결과 소변 배출량(Urine Output), 젖산(Lactate), 혈액 요소 질소(BUN), 최소 수축기 혈압(SysBP_min), 국제 표준화 비율(INR), 연령(Age), 암(Cancer), 산소포화도(SpO2), 나트륨(Sodium), 음이온 차이(AG), 크레아티닌(Creatinine)이 가장 중요한 변수로 선정되었습니다.


위 11가지의 변수들은 XGBoost 예측 모델을 구축하는데 포함되었습니다.
Model comparisons
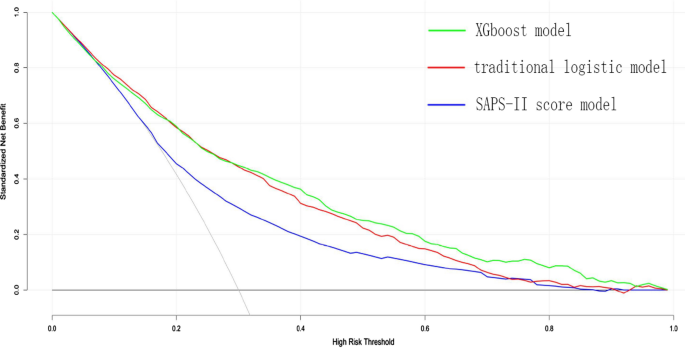
아래 그림들은 로지스틱 회귀 모델, SAPS-II 점수 모델, XGBoost 머신 러닝 모델에 대한 ROC 곡선과 DCA 곡선을 그려낸 것으로. 왼쪽 그림은 ROC 곡선입니다. ROC 곡선의 AUC 값으로 성능을 평가해 보면 로지스틱 회귀는 0.819, SAP-II는 0.797, XGBoost는 0.857로, XGBoost 모델의 성능이 가장 높다는 것을 확인할 수 있습니다. 오른쪽 그림은 DCA 결정 곡선으로, XGBoost의 Net benefit이 로지스틱 회귀 모델과 SAPS-II보다 더 큰 것을 확인할 수 있고, 이는 XGBoost 모델이 가장 우수한 예측력을 가진 모델임을 나타냅니다.

Optimal model analysis
XGBoost 예측 모델을 시각적으로 표현한 Risk Nomogram은 왼쪽 그림에 표현되어 있습니다. 오른쪽 그림은 임상영향곡선(CIC) 분석을 수행하여 Risk Nomogram의 임상 적용 가능성을 평가한 것입니다.

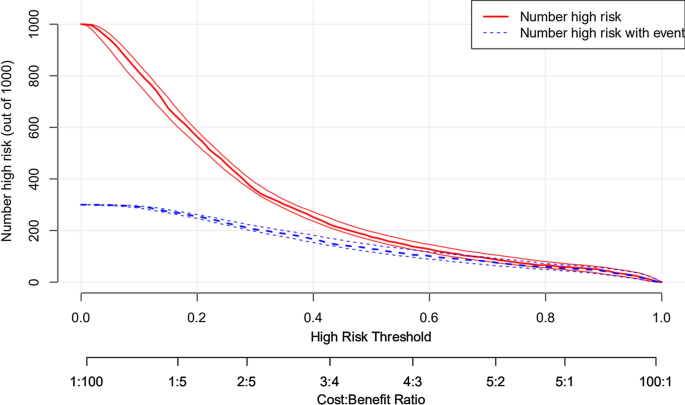
CIC 분석 결과, 노모그램은 넓고 실용적인 임계 확률 범위에서 우수한 Net Benefit을 제공하며, 환자 치료 결과에 긍정적인 영향을 미침을 시각적으로 확인해볼 수 있습니다. 이러한 결과는 XGBoost 모델이 강력한 예측 능력을 가짐을 보여줍니다.
Conclusion
결론적으로, 본 연구에서는 XGBoost 알고리즘을 기반으로 한 머신 러닝 모델이 기존 로지스틱 회귀 분석 및 SAPS-II 점수 모델보다 뛰어난 성능을 보인다는 것을 입증하였습니다. 또한, XGBoost 모델이 임상적으로 사용될 가능성이 있음을 보였고, 패혈증 환자를 위한 정확한 치료 및 맞춤형 관리 전략을 제공하는 데 있어 임상의들을 보조하는 역할을 할 수 있음을 일러주었습니다. 즉, XGBoost 모델은 환자의 생존 가능성을 극대화하는 데 필수적인 요소로 여겨질 가능성이 있음을 보여주었습니다.