논문 게시일 : 2024.08.20
1. Background information
1. Transformer

1. 기존 신경망 모델의 한계
과거에는 기계 번역과 텍스트 생성과 같은 자연어 처리 작업에 주로 **순환 신경망(RNN)**이나 LSTM(Long Short-Term Memory) 모델이 활용되었습니다. 하지만 이러한 모델들은 다음과 같은 문제점을 가지고 있었습니다.
1. 연산 속도 저하: RNN과 LSTM은 데이터를 순차적으로 처리하기 때문에 병렬 연산이 어렵습니다.
2. 장기 의존성 문제: 문장이 길어질수록, 멀리 떨어진 단어들 간의 관계를 효과적으로 학습하는 것이 어려워집니다.
2. Transformer 모델의 등장
이러한 문제를 해결하기 위해 2017년 "Attention Is All You Need" 논문에서 Transformer 모델이 제안되었습니다. Transformer는 다음과 같은 강점을 가지고 있습니다.
- 병렬 처리 가능: 문장을 한 번에 처리할 수 있어 연산 속도가 크게 향상됩니다.
- Self-Attention 메커니즘 활용: 문장의 각 단어가 다른 단어들과 어떤 관계를 맺고 있는지를 효과적으로 학습할 수 있습니다.
3. Self-Attention 메커니즘


Self-Attention은 Transformer 모델의 핵심 개념입니다. 이 메커니즘은 문장 내의 각 단어가 다른 단어들과 어떻게 연관되는지를 계산합니다. 예를 들어, "The cat sat on the mat"이라는 문장에서 "cat"은 "sat" 및 "mat"과 강한 연관성을 가집니다. Self-Attention을 통해 이러한 관계를 학습하여 문맥을 보다 정밀하게 이해할 수 있습니다.
4. Transformer의 구조
Transformer 모델은 인코더(Encoder)와 디코더(Decoder)로 구성됩니다.
인코더: 입력 문장을 받아서 벡터 형태로 변환하며, Self-Attention 메커니즘을 적용합니다.
디코더: 인코더에서 생성된 벡터를 바탕으로 최종 출력을 생성합니다. 번역 모델의 경우, 번역된 문장을 출력하는 역할을 합니다.
4.1 인코더(Encoder)
Transformer의 인코더는 여러 개의 동일한 레이어(Stacked Layers)로 구성되어 있으며, 각 레이어는 다음과 같은 과정을 거칩니다.
1) 임베딩 레이어 (Embedding Layer)
입력된 문장의 각 단어를 고차원 벡터로 변환합니다. 이러한 벡터는 학습을 통해 지속적으로 업데이트됩니다.
2) 포지셔널 인코딩 (Positional Encoding)
Transformer는 RNN처럼 순차적 구조를 갖지 않기 때문에 단어의 위치 정보를 추가해 학습해야 합니다. 포지셔널 인코딩은 단어 벡터에 위치 정보를 더하는 방식으로 적용됩니다.
3) Self-Attention 메커니즘
문장 내 단어들이 서로 어떻게 관련되어 있는지를 학습하는 과정입니다.
1. 쿼리(Query), 키(Key), 밸류(Value) 벡터 생성: 입력 벡터를 변환하여 각각의 벡터를 생성합니다.
2. 어텐션 스코어 계산: Query와 Key 벡터의 내적(dot product)을 계산하여 각 단어 간의 연관성을 정량화한 후, Softmax 함수를 통해 weight를 부여합니다.
(Softmax를 사용하는 이유 : attention score가 음수로 나올 수 있고, weight합이 1이 되어야함)
3. weight 계산: Value 벡터에 attention 스코어를 곱하여 중요한 단어의 정보를 강조합니다.
4) 인코더-디코더 어텐션 (Encoder-Decoder Attention)
인코더에서 생성된 출력과 디코더의 출력을 결합하여 입력 문장과 타겟 문장 간의 관계를 학습합니다.
5) 피드 포워드 신경망 (Feed-Forward Neural Network)
각 단어 벡터를 완전 연결층을 거쳐 더욱 정교한 형태로 변환합니다.
6) 잔차 연결과 정규화 (Residual Connection and Layer Normalization)
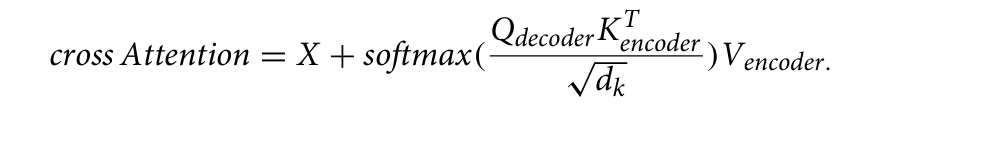
각 레이어의 출력을 입력과 더한 후 정규화를 적용하여 학습을 안정화합니다.
4.2 디코더(Decoder)
디코더는 인코더의 출력을 받아 최종 출력을 생성하는 역할을 합니다. 인코더와 유사한 구조를 가지지만, Masked Self-Attention과 인코더-디코더 어텐션(Encoder-Decoder Attention)이라는 추가적인 과정이 포함됩니다.
1) Masked Self-Attention
타겟 문장의 단어들 간의 관계를 학습하되, 미래 단어를 참조하지 못하도록 마스크(mask)를 적용합니다. 이를 통해 디코더는 현재까지의 단어만을 이용해 다음 단어를 예측할 수 있도록 학습됩니다.
2) 인코더-디코더 어텐션 (Encoder-Decoder Attention)
인코더에서 생성된 출력과 디코더의 출력을 결합하여 입력 문장과 타겟 문장 간의 관계를 학습합니다.
2. BERT & GPT


BERT는 Encoder로 만든 모델입니다. Bidirectional Encoder Representations from Transformers의 약자로, 트랜스포머의 encoder 모델만을 활용한 모델입니다. BERT의 가장 큰 특징은 이전의언어 모델들과 달리 양방향으로 문맥을 파악하며 학습한다는 점입니다. 기존의 언어 모델들은 대부분 단방향적인 학습, 즉 왼쪽에서 오른쪽으로 또는 그 반대로만 텍스트를 읽습니다. 그러나 BERT는 주변의 문맥 정보를 앞 뒤 양방향에서 동시에 파악하므로, 단어나 구문의 정확한 의미를 더 잘 이해할 수 있습니다. Next Sentence Prediction(NSP)과 Masked Language Modeling(MLM)이라는 두 가지 학습 과제를 도입하여 훈련됩니다. BERT는 두 개의 문장을 입력으로 받고, 이를 구분하기 위해 [SEP] 토큰을 삽입합니다. 또한, 문장의 시작에는 [CLS]라는 특별한 토큰을 추가하여 분류 작업에 활용할 수 있도록 합니다. 이후 모델은 다음과 같은 두 가지 문제를 해결하도록 학습됩니다.
- 두 문장이 논리적으로 연결되는가? (NSP)
- 문장에서 가려진 단어는 무엇인가? (MLM)
이처럼 BERT는 문장 간 관계(NSP)와 문장 내 단어 간 연관성(MLM)을 동시에 학습함으로써, 텍스트를 보다 깊이 있게 이해할 수 있도록 설계되었습니다. 트랜스포머의 인코더는 정보를 추출하고 정제하는 데 최적화된 구조를 갖추고 있기 때문에, BERT는 이러한 인코더 구조를 발전시켜 문장을 분석하고 해석하는 능력을 강화한 것입니다.
GPT는 Generative Pre-trained Transformer의 약자로, 이름에서도 알 수 있듯이 주된 목적은 자연스럽게 텍스트를 생성하는 것입니다. 이 모델은 트랜스포머(Transformer) 구조 중에서도 디코더(Decoder)를 기반으로 발전했으며, 이는 관련 논문에서도 명확히 설명되고 있습니다.
GPT의 핵심은 다음 단어를 예측하는 텍스트 예측 모듈(Text Predictor)입니다. 주어진 문맥을 바탕으로 가장 적절한 단어를 생성하며, 이를 반복하면서 문장의 흐름을 자연스럽게 이어갑니다. 이러한 특성 덕분에 GPT는 다양한 자연어 처리 작업에서도 우수한 성능을 보이며, 궁극적으로 챗봇과 같은 대화형 AI 기술로 발전하는 데 중요한 역할을 하게 되었습니다.
2. Multi‑modal transformer architecture

1. Encoder
1. 1. ViT
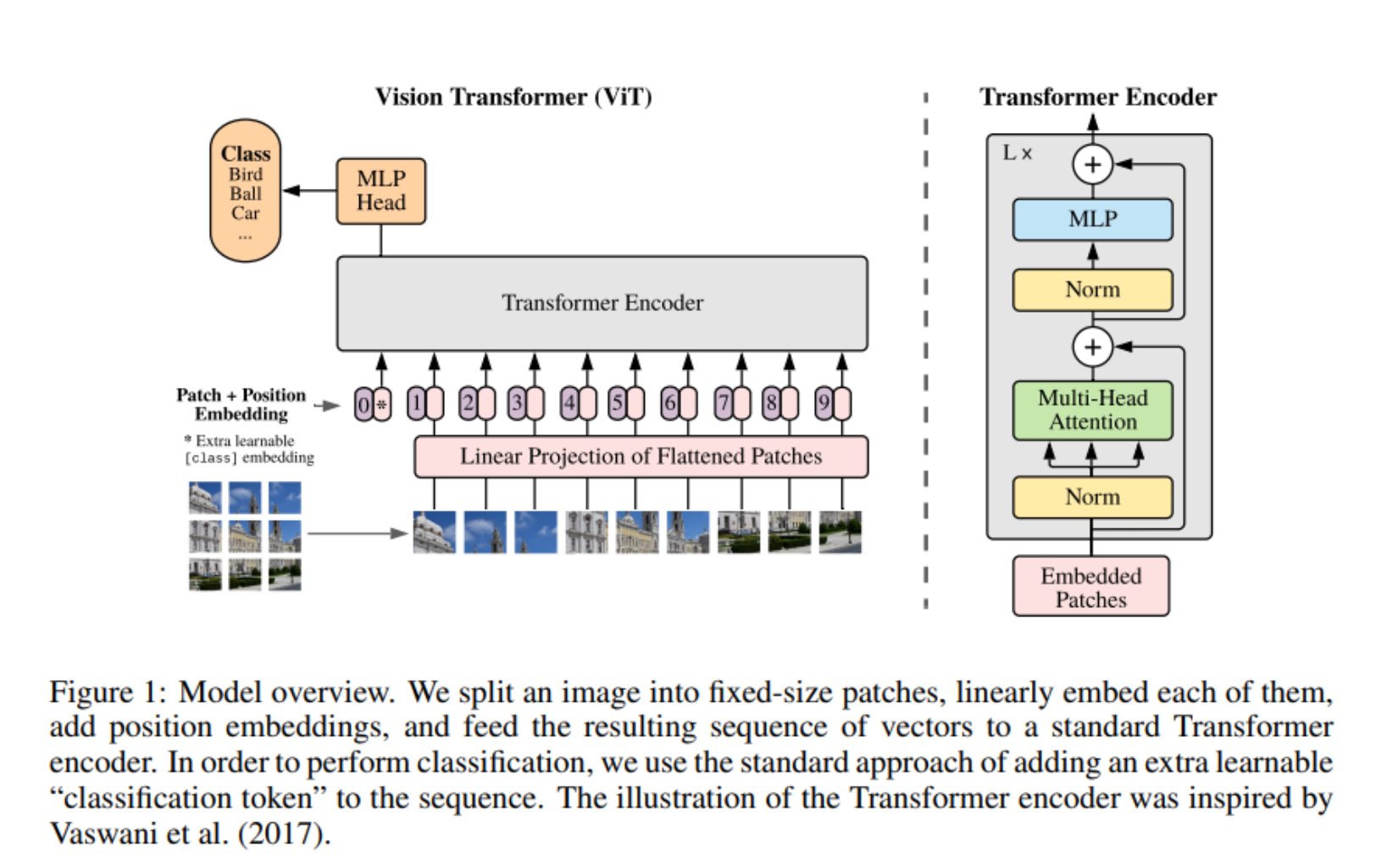
ViT(Vision Transformer)는 이름에서도 알 수 있듯이 Transformer를 활용하여 image를 classification 하는 모델입니다.
모델 구조도 매우 유사합니다. 우선, 이미지를 고정된 크기의 patch로 나눠 Flattened Patches를 만듭니다.
1차원으로 바꾼 이미지를, transformer에 사용할 수 있는 D벡터로 바꾼 후 transformer input으로 사용합니다(1)
Transformer 모델과 유사하게 정규화, Multi-Head Attention 과정을 거칩니다
마지막으로 MLP를 통해 Class로 분류됩니다(3),(4)
수식은 아래와 같습니다.
(z0 : 첫 대입값)

1. 2. BEiT

BERT는 문장을 단어 단위로 토큰화한 후 일부 단어를 마스킹(masking)하여 제거하고, 마스킹된 단어를 예측하도록 학습합니다. 이를 통해 문장을 전체적으로 이해하는 능력을 갖추게 됩니다.
BEiT는 이미지에 대한 토큰화를 해결하는 과정에서 새로운 접근법을 도입했습니다. NLP에서는 사전에 정의된 토크나이저를 사용하여 단어를 토큰화할 수 있지만, 이미지에서는 동일한 방식이 적용되지 않았습니다. 그러나 OpenAI가 발표한 DALL-E 논문에서 제안된 이미지 토크나이저를 활용하면서 이 문제를 해결할 수 있었습니다.
BEiT는 마스킹된 이미지 패치의 최종 출력을 DALL-E를 통해 미리 생성된 discrete token을 예측하는 방식으로 모델을 훈련합니다. 이를 통해 이미지 데이터를 보다 효과적으로 학습할 수 있습니다.
1. 3. DEiT
DeiT는 데이터 효율성이 높은 모델로, 대규모 데이테섯이 필수 요건이 아니며 적은 데이터로도 높은 효율을 달성합니다.

2. Decoder
2. 2. GPT2
GPT는 Generative Pre-trained Transformer의 약자로, text를 생성하는 것에 초점을 둔 모델입니다. Transformer architecture에서 text를 생성하는 부분인 Decoder에서 발전한 모델입니다. GPT는 단어 이후 어떤 단어가 와야할지 예측하면서 글을 생성해냅니다.본 논문의 Architecture에서는 GPT-2가 사용되었는데, GPT-2는 GPT의 단점인 Fine-tuning과정 없이 다양한 자연어 처리과정을 수행할 수 있습니다. Fine-tuning이란 특정 작업에 적합하도록 미리 훈련을 시키는 과정입니다.GPT-2는 입력된 값들과 special Token을 추가함으로써, 수행해야할 Task를 같이 입력받 다음 단어를 예측합니다.
3. Chroma DB & Lang Chain
3. 1. Chroma 벡터 스토어의 역할
- Chroma는 벡터 데이터베이스로, 추가적인 의료 지식과 보고서를 벡터 형태로 저장합니다.
- 벡터 임베딩을 효율적으로 저장하여 빠른 검색 및 정보 활용이 가능합니다.
- FAISS, Pinecone보다 비용 효율성이 높고 오픈 소스라는 장점이 있습니다.
- 이 시스템에서 검색 및 저장 기능을 담당합니다.
3. 2. Lang Chain을 활용한 검색 및 증강(Retrieval Augmentation)
- Lang Chain은 데이터 파이프라인 도구로, Chroma에 저장된 정보를 검색 및 분석하는 역할을 합니다.
- ViTGPT2 모델이 생성한 초기 분석 결과를 바탕으로, 관련 정보를 Chroma에서 검색하여 추가적인 지식을 결합합니다.
- 프롬프트 템플릿을 사용하여 LLM(대형 언어 모델)이 보다 구체적인 분석을 수행하도록 유도합니다.
3. 3. 프롬프트 템플릿 구성
프롬프트 템플릿은 세 가지 주요 요소로 구성됩니다.
- Indication (징후) → 핵심 지표나 관찰된 내용은 무엇인가?
- Impression (소견) → 전반적인 인상이나 의미는 무엇인가?
- Summary of findings (결과 요약) → 가장 중요한 결과를 간결하고 정보적으로 요약하라.
3. 4. 전체 프로세스 요약
- ViTGPT2 모델이 의료 보고서를 생성합니다.
- 생성된 정보를 Chroma 벡터 스토어에 저장합니다.
- Lang Chain이 Chroma에서 유사한 데이터를 검색하여 증강(Retrieval Augmentation) 수행합니다.
- 프롬프트 템플릿을 사용하여 LLM이 더 정교한 분석 및 요약 생성합니다.
이러한 방식을 통해 의료 보고서의 정확성과 이해도를 향상시키고, 보다 효율적인 정보 검색 및 분석이 가능하도록 합니다.