
- 논문 작성일: 2024.09.24
- 논문 리뷰 작성일: 2025.03.08
- 제출된 학회: WACV25
- 인용수: 5회
Abstract
- MAISI (Medical AI for Synthetic Imaging) : 3D Latent Diffusion Model (LDM) 기반으로 대형 CT 영상을 생성하며 해부학적 구조와 병변 크기를 조절할 수 있도록 설계된 모델
- VAE (Variational Auto-Encoder) 기반 compression network : CT 및 MRI 데이터를 처리하며 다양한 크기의 볼륨과 voxel spacing 지원
- Latent diffusion model : 최대 512 × 512 × 768 해상도의 CT 생성
- ControlNet : organ segmentation와 tumer size를 조절하여 Annotated synthetic image 생성
1. Introduction
Challenges in Medical Analysis Image ML model
- 데이터 부족 : 희귀 질환에서 제한된 데이터로 학습 미흡
- 높은 Human annotaion 비용 : 전문가의 도메인 지식이 필요
- Privacy 문제 : 의료 데이터를 공유하는데에 민감한 윤리적 문제
Generaing synthetic data : 의료 이미지 생성
- 기존 데이터셋을 보완하고 환자 데이터 의존도를 낮추며 주석(annotation) 비용을 절감할 수 있는 Synthetic Data 생성 기술이 의료 AI 분야에서 유망한 해결책으로 떠오름
- 최근 생성 모델(GAN, Diffusion Model 등)의 발전을 의료 영상 생성에 적용
→ 다중 대비(Multi-contrast) MR/CT 합성, 다중 모달리티 변환(Cross-modality Translation), 이미지 복원(Image Reconstruction) 등의 다양한 연구가 수행되고 있음
기존 연구의 한계
- 고해상도 3D 의료 영상 생성의 어려움
- $512^3$ 이상의 고해상도 3D CT 볼륨을 생성하는 것은 매우 높은 메모리 소비를 요구
- 따라서 메모리 병목(memory bottleneck) 문제를 해결하는 것이 필수적
- 고정된 출력 볼륨 크기 및 Voxel Spacing 문제
- 기존 모델들은 고정된 볼륨 크기와 Voxel 간격을 사용하여 다양한 해부학적 구조 분석에 적합하지 않음
- 실질적인 의료 적용을 위해 동적으로 볼륨 크기와 Voxel 간격을 조정할 수 있는 기능이 필요함
- 특정 데이터 및 장기에 최적화된 모델의 일반화 문제
- 기존 생성 모델들은 특정 데이터셋 혹은 특정 장기에 맞춰 학습되었기 때문에 새로운 데이터나 장기에 적용할 경우 추가적인 학습이 필요함
- 다양한 데이터셋과 해부학적 구조를 지원하는 범용적인 모델 개발이 필수적
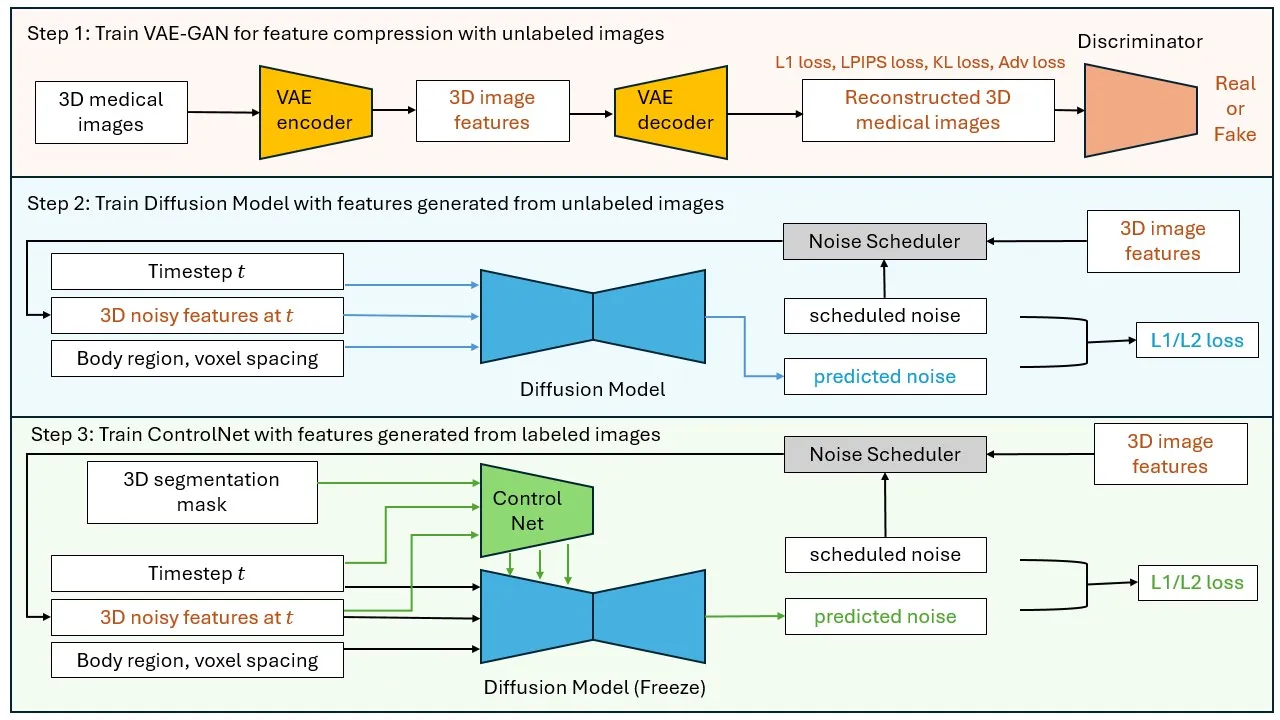
⇒ 고해상도 3D CT Volume Generation을 위해 Volume Compression Network, Latent Diffusion model, ControlNet으로 구성된 MAISI 제안
2. Related Work
- 이전에는 예제 기반 접근법(Example-based Approach), 기하학적 정규화(Geometry-regularized Dictionary Learning) 등 기존 영상 처리 기술 기반이었고 현실감 있고 다양한 의료 영상을 생성하는 데 한계가 있었음
- Machine learning, Deep learning의 발전으로 정교하고 정확한 모델 가능
GAN
- MRI와 CT 이미지 합성과 같은 다양한 작업에 적용
→ cross-modality image translation, image reconstruction, super-resolution - 대부분의 연구가 2D 의료 이미지 또는 작은 볼륨 패치 합성(small volumetric patch synthesis)에 국한됨
- 의료 데이터의 3D 특성을 충분히 반영하지 못하여 임상 적용이 어려움
Diffusion Models
- 높은 품질의 의료 영상 합성 가능, GAN보다 안정적 학습과정, 입력 조건(conditioning)의 유연성
- GenerateCT : 자연어 프롬프트를 입력하여 3D CT 영상 생성 가능하지만 개별 슬라이스를 순차적으로 생성하는 방식이라 3D 구조적 불일치 문제가 발생
- DiffTumor : 다양한 장기의 종양(Tumor)을 합성하여 세그멘테이션 모델의 성능을 향상
MAISI는 기존 GAN과 Diffusion Model의 한계를 극복하면서 고해상도 3D CT 볼륨을 효과적으로 생성할 수 있는 새로운 접근법을 제시하였다.
- Tensor Splitting Parallelism(TSP) 기법을 활용하여 GPU 메모리 사용량을 최적화함
- ControlNet을 활용하여 특정 해부학적 구조 및 병변 크기 조절 가능
- 다양한 임상 데이터셋을 학습하여 일반화 가능성을 확보
3. Methodology
- Volume Compression Network(VAE-GAN)
- 고해상도 3D 의료 영상을 latent space로 변환, 메모리 사용량 감소와 연산 효율성 향상
- Latent diffusion model (LDM)
- Compressed latent space에서 Body Region(신체 부위) 및 Voxel Spacing을 조건으로 유연한 크기의 3D 해부학적 feature 생성 생성 가능
- ControlNet
- Trained Latent DM의 두 번째 단계에서 추가적인 조건(Conditions)을 주입하여 다양한 작업을 지원
- 조건부 세그멘테이션 마스크 적용, 병변 삽입 및 제거(Inpainting), 특정 해부학적 구조 반영 등 광범위한 작업 수행 가능
- 새로운 Task에 적용할 때도 추가적인 재학습(Retraining) 없이 활용 가능 → 모델의 효율성과 확장성을 극대화
3.1 Volume Compression Network

- 입력 CT 볼륨 $x\in{}R^{H×W×D}$ → Encoder $E(x)$
- Encoder $E$가 CT/MRI 영상에서 Latent Representation $z$를 생성
- $z=E(x)\in{}R^{h×w×d}$ (원본보다 작은 해상도)
- Decoder $D(z)$를 통해 원본 영상 복원
- Latent Space에서 복원된 영상 $x^{\prime}=D(z)$
- 3D Discriminator $C$가 복원된 영상의 품질을 평가하고 비현실적 요소를 보정
$$
x \in \mathbb{R}^{H \times W \times D}
\\
z = \mathcal{E}(x) \in \mathbb{R}^{h \times w \times d}
\\
\tilde{x} = \mathcal{D}(z) = \mathcal{D}(\mathcal{E}(x))
\\
\min_{\mathcal{E}, \mathcal{D}} \max_{\mathcal{C}}
\left(
\mathcal{L}_{\text{recon}}(x, \mathcal{D}(\mathcal{E}(x)))
+ \mathcal{L}_{\text{lpips}}(x, \mathcal{D}(\mathcal{E}(x)))
+ \mathcal{L}_{\text{reg}}(\mathcal{E}(x)) + \mathcal{L}_{\text{adv}}
\right)
\\
\mathcal{L}_{\text{adv}} = \log \mathcal{C}(x) + \log(1 - \mathcal{C}(\mathcal{D}(\mathcal{E}(x))))
$$
- 손실 함수 결합하여 학습
- Perceptual Loss $L_{lpips}$ : 생성된 볼륨이 원본과 시각적으로 유사한지 평가
- Adversarial Loss $L_{adv}$ : GAN 기반 3D 판별기(Discriminator)를 활용하여 비현실적인 아티팩트(Artifact)를 식별하고 보정
- L1 reconstruction loss $L_{recon}$ : 원본과 재구성된 볼륨 간 픽셀 단위 차이를 최소화하여 복원 성능을 향상
- KL Regularization $L_{reg}$ : 학습된 Latent Space의 분산을 제어하여 과도한 변화(high variance) 방지
Tensor spliting parallelism (TSP) : Memory bottleneck 해결
- 2D 기반 초해상도(Super-Resolution) 모델이 일부 해결책으로 연구되었지만 3D 전체 볼륨을 처리하는 경우 여전히 높은 메모리 사용량 문제가 해결되지 않음
- Sliding Window Inference는 의료 영상 세그멘테이션 모델에서 Probability Map 생성 시에는 효과적이지만 이미지 합성(Generation)에서는 창(window) 간의 경계 문제가 발생하여 품질 저하

- Convolution, Normalization Layer에서 필요한 overlap을 보존하면서 Feature Map을 여러 개의 작은 세그먼트(Segment)로 분할하고 각 세그먼트를 개별 GPU에 할당하여 연산 후 다시 병합(Merge)하여 최종 output을생성
- Inference 속도 개선, single GPU에서도 순차적으로 연산하여 부족한 메모리 사용량 최소화
⇒ 3D 컨볼루션 최적화
3.2 Diffusion Model

- flexible dimension의 압축된 latent space에서 작동, body region 및 voxel spacing을 conditional input으로 통합
- 마르코프 체인(Markov Chain) 기반의 denoising 작업을 거쳐 Data distribution $p(x)$에서 생성되는 과정을 학습
- U-Net 기반의 Denoising Autoencoder ($\epsilon_\theta$) 학습
- 학습된 모델 $\epsilon_\theta$는 입력된 노이즈 $z_t$를 점진적으로 복원하여 원본 Latent Feature를 예측
- 각 Time Step $t$에서 노이즈 수준을 예측하여 점진적으로 원본 영상 복원
Conditional 생성 기능
- Body region : $i_{top}$, $i_{bottom}$ ⇒ 머리-목, 가슴, 복부, 하체 4개의 One-Hot Vector로 표현
- Voxel spacing : $s$ ⇒ 3D 공간에서 X, Y, Z 축의 Voxel 크기를 조절하여 다양한 해상도 영상 생성 가능
- $c_p=\{i_{top},i_{bottom},s\}$ → 신체 부위, Voxel Spacing 조건을 포함한 입력 조건 집합
- $\epsilon_\theta$는 U-Net 기반 노이즈 예측 모델이며 training process에서 dimension이 달라지는 latent variable $z_t$를 학습하고 output 생성
$$
\mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t, \mathbf{c}_p}
\left[ \left\| \epsilon - \epsilon_{\theta}(z_t, t, \mathbf{c}_p) \right\|_1 \right]
$$
3.3 Additional Conditioning Mechanisms
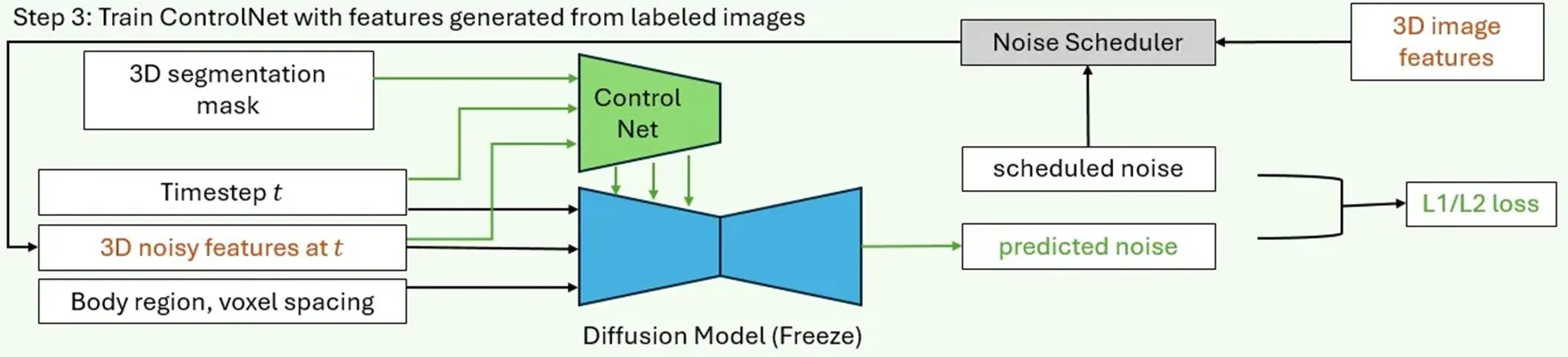
- ControlNet을 활용하여 생성된 3D 의료 영상의 구조를 세부적으로 제어할 수 있도록 설계
- ControlNet의 기본 두 개의 복사본을 사용
- Locked copy (기존 모델의 지식을 유지), Trainable Copy (특정 조건에 맞게 학습 가능), Zero Convolution Layer (초기 가중치 0으로 설정 후 점진적으로 최적화)
- Compact Encoder Network를 사용하여 입력된 condition을 latent feature 내 Task-Specific Condition $c_f$로 전환
- 특정 의료 분석 작업에 맞춘 3D 영상 생성 Task를 retraining 과정 없이 수행 가능
$$
\mathbb{E}_{\mathcal{E}(x), \epsilon \sim \mathcal{N}(0,1), t, \mathbf{c}_p, \color{blue}{\mathbf{c}_f}}
\left[ \left\| \epsilon - \epsilon_{\theta}(z_t, t, \mathbf{c}_p, \color{blue}{\mathbf{c}_f}) \right\|_1 \right]
$$
4. Experiments
- 3개의 구성 모델(VAE, DM, ControlNet)별로 적절한 데이터셋에 대해 학습
- 정상 범위 내 주요 장기가 잘 생성되었는지 품질 확인
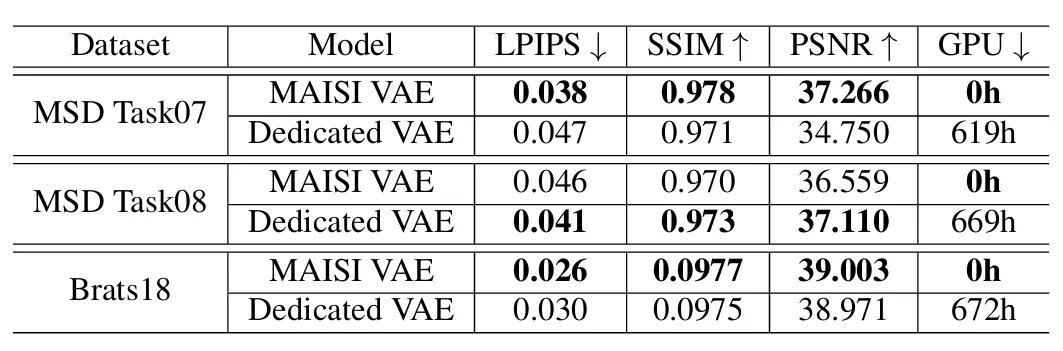
4.1 Evaluation of MAISI VAE
- 일반화 성능을 평가하기 위해 훈련되지 않은 데이터셋(Out-of-Distribution Datasets)에 대해 MAISI VAE model과 특정 데이터셋에서 학습한 Dedicated VAE(test dataset 내에서 학습) 성능 비교
- 추가 학습 없이도 전용 VAE 모델과 동등한 성능을 달성하면서 추가적인 GPU 학습 비용을 절감
- ⇒ 모델 효율성과 실용성 및 최적화 잠재력을 보여줌
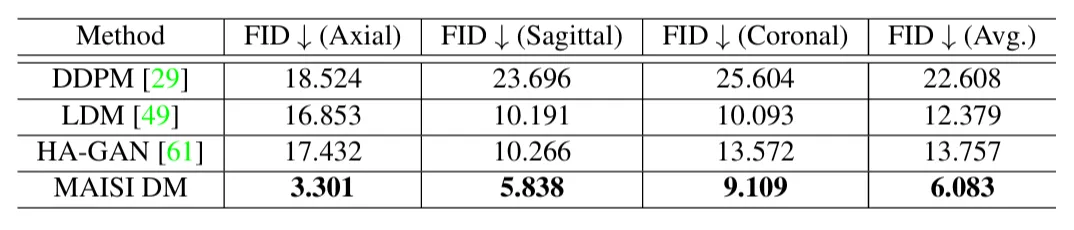
4.2 Evaluation of MAISI Diffusion Model
- 합성 영상 품질 평가 (Synthesis Quality Evaluation) : 실제 dataset과 비교하였을 때 FID 수치 비교
- DDPM, LDM, HA-GAN과 비교하였을 때 실제 dataset과 유사한 이미지를 생성
- HA-GAN은 주로 흉부(Chest) CT 영상 합성에 특화된 모델이므로 MAISI와 직접 비교

- MAISI DM의 성능을 추가적으로 검증하기 위해 autoPET 2023 데이터셋을 활용


- 다양한 Body Region 설정에 따라 anatomically consistent한 영상 생성 가능
- Voxel Spacing 조절을 통해 다양한 해상도로 영상을 생성할 수 있음
4.3 Data Augmentation in Downstream Tasks
MAISI CT Generation
- 127개의 해부학적 구조에 대한 세그멘테이션 마스크(Segmentation Mask)를 활용하여 합성 데이터 생성
- 각 병변(종양) 마스크를 활용하여 기존 환자 데이터의 증강(Augmentation) 수행
- 실제 환자 데이터에서 수집된 종양 형태를 유지하면서도 새로운 합성 데이터를 생성 가능
⇒ 단순 생성
MAISI Inpainting
- 건강한 환자 데이터에서 특정 종양이 존재하는 것처럼 합성하여 새로운 데이터셋 생성
- 간, 폐, 췌장 종양에 대해 inpainting을 수행하여 종양이 존재하는 새로운 샘플을 생성
- 특히 비정형적인 모양을 가지는 병변(골 병변, 대장 종양 등)의 경우, 기존 모델(DiffTumor)보다 더 정교한 합성 가능
⇒ 건강한 환자 Data에 tumor 합성
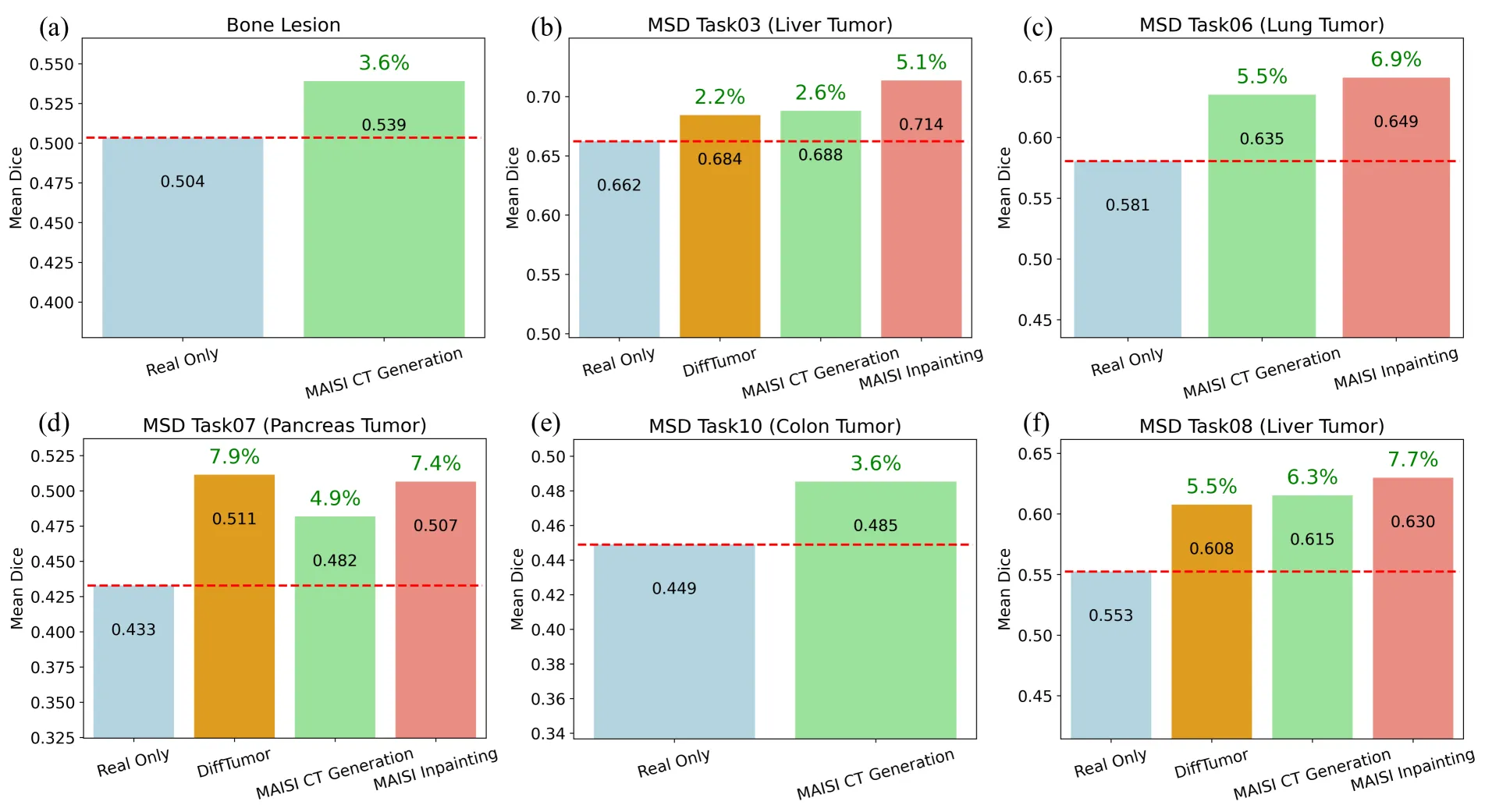
- MAISI dataset augmentaion에서 DSC 향상, out-of-distribution dataset에 대해 test를 수행했을 때 높은 성능을 보임
5. Discussion and Limitation
- 고품질 CT 이미지를 생성하는 데 큰 잠재력
- 한계 : 다양한 인구 집단을 반영한 데이터셋 구축 필요, 계산 비용을 줄이기 위한 모델 최적화 및 경량화 연구 필요
6. Conclusion
- Foundation Model (VAE + LDM)과 ControlNet을 결합하여 고해상도 3D CT 볼륨을 생성하는 모델
- 다양한 신체 부위 및 병변을 반영한 해부학적으로 정교한 3D 의료 이미지 생성 가능
- Flexible volume dimensions과 voxel spacing을 활용하여 현실적인 CT 이미지 생성
- 합성 데이터를 활용한 Data Augmentation을 통해 의료 데이터 부족 문제를 해결하고 Segmentation 및 분류 모델의 성능 향상 기여
